 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence Driven Channel Coding and Resource Optimization for Wireless Networks
Jan 11, 2026The ongoing evolution of 5G and its enhanced version, 5G+, has significantly transformed the telecommunications landscape, driving an unprecedented demand for ultra-high-speed data transmission, ultra-low latency, and resilient connectivity. These capabilities are essential for enabling mission-critical applications such as the Internet of Things, autonomous vehicles, and smart city infrastructures. This paper investigates the important role of Artificial Intelligence (AI) in addressing the key challenges faced by 5G/5G+ networks, including interference mitigation, dynamic resource allocation, and maintaining seamless network operation. The study particularly focuses on AI-driven innovations in coding theory, which offer advanced solutions to the limitations of conventional error correction and modulation techniques. By employing deep learning, reinforcement learning, and neural network-based approaches, this research demonstrates significant advancements in error correction performance, decoding efficiency, and adaptive transmission strategies. Additionally, the integration of AI with emerging technologies, such as massive multiple-input and multiple-output, intelligent reflecting surfaces, and privacy-enhancing mechanisms, is discussed, highlighting their potential to propel the next generation of wireless networks. This paper also provides insights into the transformative impact of AI on modern wireless communication, establishing a foundation for scalable, adaptive, and more efficient network architectures.
Trajectory Optimization for UAV-Based Medical Delivery with Temporal Logic Constraints and Convex Feasible Set Collision Avoidance
Jun 06, 2025This paper addresses the problem of trajectory optimization for unmanned aerial vehicles (UAVs) performing time-sensitive medical deliveries in urban environments. Specifically, we consider a single UAV with 3 degree-of-freedom dynamics tasked with delivering blood packages to multiple hospitals, each with a predefined time window and priority. Mission objectives are encoded using Signal Temporal Logic (STL), enabling the formal specification of spatial-temporal constraints. To ensure safety, city buildings are modeled as 3D convex obstacles, and obstacle avoidance is handled through a Convex Feasible Set (CFS) method. The entire planning problem-combining UAV dynamics, STL satisfaction, and collision avoidance-is formulated as a convex optimization problem that ensures tractability and can be solved efficiently using standard convex programming techniques. Simulation results demonstrate that the proposed method generates dynamically feasible, collision-free trajectories that satisfy temporal mission goals, providing a scalable and reliable approach for autonomous UAV-based medical logistics.
UAV-UGV Cooperative Trajectory Optimization and Task Allocation for Medical Rescue Tasks in Post-Disaster Environments
Jun 06, 2025
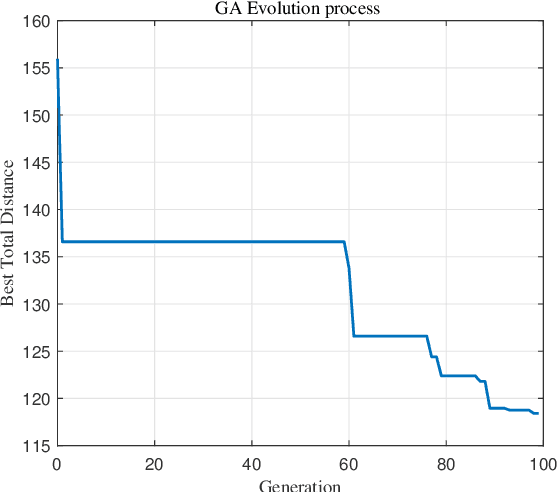


In post-disaster scenarios, rapid and efficient delivery of medical resources is critical and challenging due to severe damage to infrastructure. To provide an optimized solution, we propose a cooperative trajectory optimization and task allocation framework leveraging unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs). This study integrates a Genetic Algorithm (GA) for efficient task allocation among multiple UAVs and UGVs, and employs an informed-RRT* (Rapidly-exploring Random Tree Star) algorithm for collision-free trajectory generation. Further optimization of task sequencing and path efficiency is conducted using Covariance Matrix Adaptation Evolution Strategy (CMA-ES). Simulation experiments conducted in a realistic post-disaster environment demonstrate that our proposed approach significantly improves the overall efficiency of medical rescue operations compared to traditional strategies, showing substantial reductions in total mission completion time and traveled distance. Additionally, the cooperative utilization of UAVs and UGVs effectively balances their complementary advantages, highlighting the system' s scalability and practicality for real-world deployment.
Enhanced Trust Region Sequential Convex Optimization for Multi-Drone Thermal Screening Trajectory Planning in Urban Environments
Jun 06, 2025The rapid detection of abnormal body temperatures in urban populations is essential for managing public health risks, especially during outbreaks of infectious diseases. Multi-drone thermal screening systems offer promising solutions for fast, large-scale, and non-intrusive human temperature monitoring. However, trajectory planning for multiple drones in complex urban environments poses significant challenges, including collision avoidance, coverage efficiency, and constrained flight environments. In this study, we propose an enhanced trust region sequential convex optimization (TR-SCO) algorithm for optimal trajectory planning of multiple drones performing thermal screening tasks. Our improved algorithm integrates a refined convex optimization formulation within a trust region framework, effectively balancing trajectory smoothness, obstacle avoidance, altitude constraints, and maximum screening coverage. Simulation results demonstrate that our approach significantly improves trajectory optimality and computational efficiency compared to conventional convex optimization methods. This research provides critical insights and practical contributions toward deploying efficient multi-drone systems for real-time thermal screening in urban areas. For reader who are interested in our research, we release our source code at https://github.com/Cherry0302/Enhanced-TR-SCO.
Radiant: Large-scale 3D Gaussian Rendering based on Hierarchical Framework
Dec 07, 2024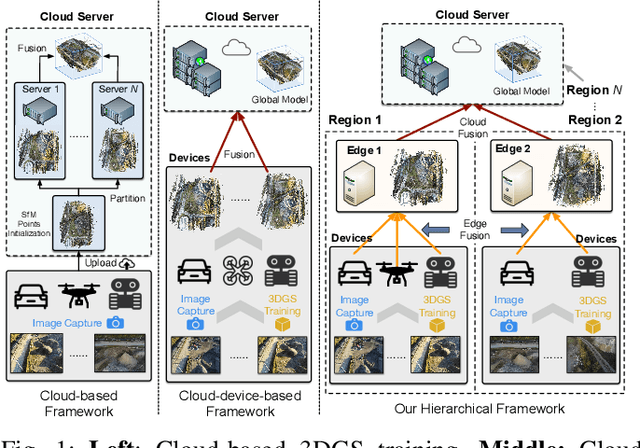
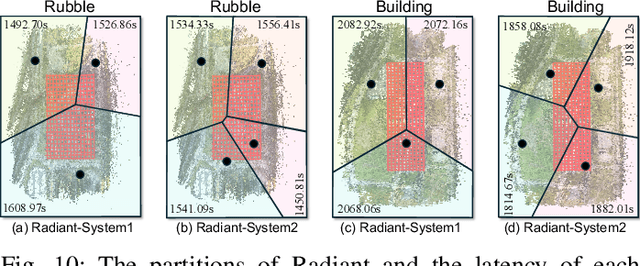
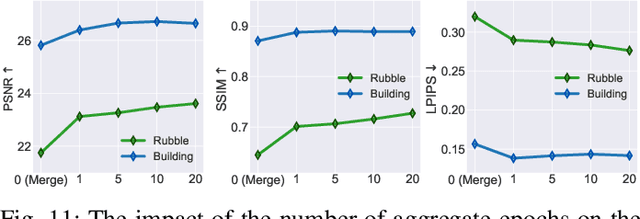

With the advancement of computer vision, the recently emerged 3D Gaussian Splatting (3DGS) has increasingly become a popular scene reconstruction algorithm due to its outstanding performance. Distributed 3DGS can efficiently utilize edge devices to directly train on the collected images, thereby offloading computational demands and enhancing efficiency. However, traditional distributed frameworks often overlook computational and communication challenges in real-world environments, hindering large-scale deployment and potentially posing privacy risks. In this paper, we propose Radiant, a hierarchical 3DGS algorithm designed for large-scale scene reconstruction that considers system heterogeneity, enhancing the model performance and training efficiency. Via extensive empirical study, we find that it is crucial to partition the regions for each edge appropriately and allocate varying camera positions to each device for image collection and training. The core of Radiant is partitioning regions based on heterogeneous environment information and allocating workloads to each device accordingly. Furthermore, we provide a 3DGS model aggregation algorithm that enhances the quality and ensures the continuity of models' boundaries. Finally, we develop a testbed, and experiments demonstrate that Radiant improved reconstruction quality by up to 25.7\% and reduced up to 79.6\% end-to-end latency.
Arena: A Patch-of-Interest ViT Inference Acceleration System for Edge-Assisted Video Analytics
Apr 14, 2024The advent of edge computing has made real-time intelligent video analytics feasible. Previous works, based on traditional model architecture (e.g., CNN, RNN, etc.), employ various strategies to filter out non-region-of-interest content to minimize bandwidth and computation consumption but show inferior performance in adverse environments. Recently, visual foundation models based on transformers have shown great performance in adverse environments due to their amazing generalization capability. However, they require a large amount of computation power, which limits their applications in real-time intelligent video analytics. In this paper, we find visual foundation models like Vision Transformer (ViT) also have a dedicated acceleration mechanism for video analytics. To this end, we introduce Arena, an end-to-end edge-assisted video inference acceleration system based on ViT. We leverage the capability of ViT that can be accelerated through token pruning by only offloading and feeding Patches-of-Interest (PoIs) to the downstream models. Additionally, we employ probability-based patch sampling, which provides a simple but efficient mechanism for determining PoIs where the probable locations of objects are in subsequent frames. Through extensive evaluations on public datasets, our findings reveal that Arena can boost inference speeds by up to $1.58\times$ and $1.82\times$ on average while consuming only 54% and 34% of the bandwidth, respectively, all with high inference accuracy.
TFDPM: Attack detection for cyber-physical systems with diffusion probabilistic models
Dec 20, 2021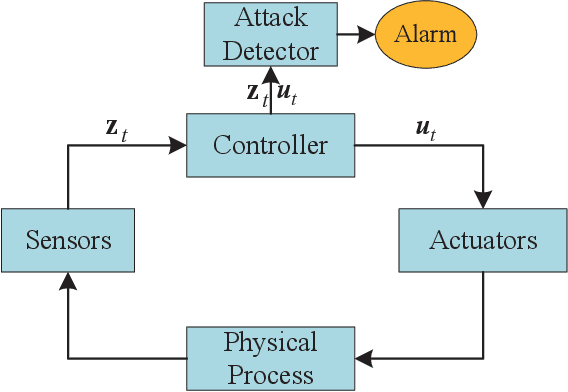

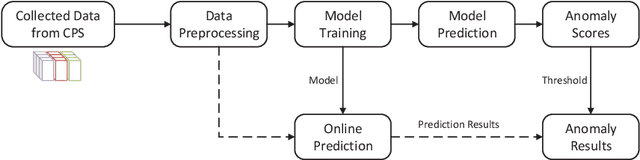
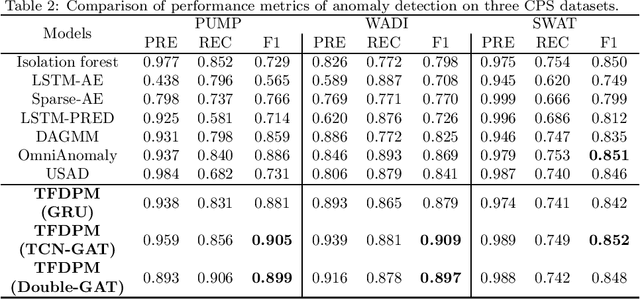
With the development of AIoT, data-driven attack detection methods for cyber-physical systems (CPSs) have attracted lots of attention. However, existing methods usually adopt tractable distributions to approximate data distributions, which are not suitable for complex systems. Besides, the correlation of the data in different channels does not attract sufficient attention. To address these issues, we use energy-based generative models, which are less restrictive on functional forms of the data distribution. In addition, graph neural networks are used to explicitly model the correlation of the data in different channels. In the end, we propose TFDPM, a general framework for attack detection tasks in CPSs. It simultaneously extracts temporal pattern and feature pattern given the historical data. Then extract features are sent to a conditional diffusion probabilistic model. Predicted values can be obtained with the conditional generative network and attacks are detected based on the difference between predicted values and observed values. In addition, to realize real-time detection, a conditional noise scheduling network is proposed to accelerate the prediction process. Experimental results show that TFDPM outperforms existing state-of-the-art attack detection methods. The noise scheduling network increases the detection speed by three times.
DMS-GCN: Dynamic Mutiscale Spatiotemporal Graph Convolutional Networks for Human Motion Prediction
Dec 20, 2021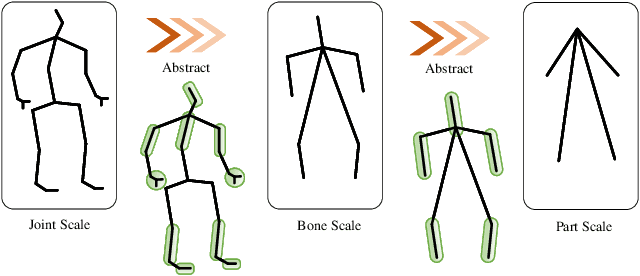
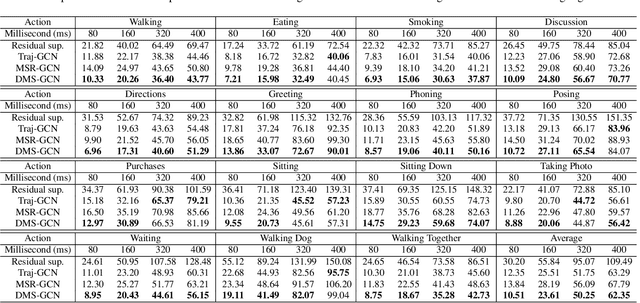
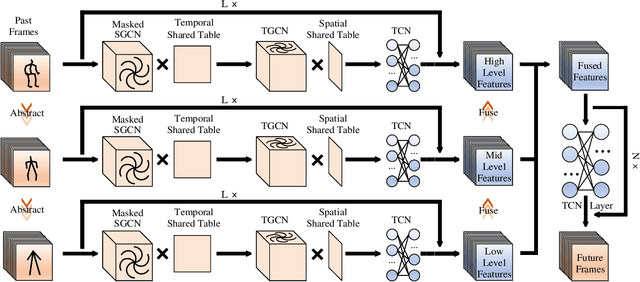

Human motion prediction is an important and challenging task in many computer vision application domains. Recent work concentrates on utilizing the timing processing ability of recurrent neural networks (RNNs) to achieve smooth and reliable results in short-term prediction. However, as evidenced by previous work, RNNs suffer from errors accumulation, leading to unreliable results. In this paper, we propose a simple feed-forward deep neural network for motion prediction, which takes into account temporal smoothness and spatial dependencies between human body joints. We design a Multi-scale Spatio-temporal graph convolutional networks (GCNs) to implicitly establish the Spatio-temporal dependence in the process of human movement, where different scales fused dynamically during training. The entire model is suitable for all actions and follows a framework of encoder-decoder. The encoder consists of temporal GCNs to capture motion features between frames and semi-autonomous learned spatial GCNs to extract spatial structure among joint trajectories. The decoder uses temporal convolution networks (TCNs) to maintain its extensive ability. Extensive experiments show that our approach outperforms SOTA methods on the datasets of Human3.6M and CMU Mocap while only requiring much lesser parameters. Code will be available at https://github.com/yzg9353/DMSGCN.
AdaL: Adaptive Gradient Transformation Contributes to Convergences and Generalizations
Jul 04, 2021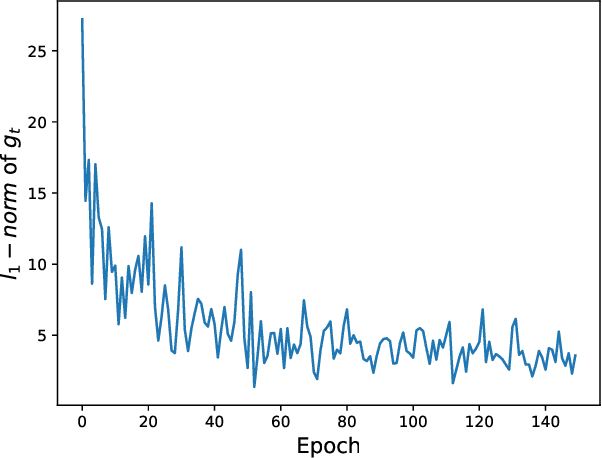

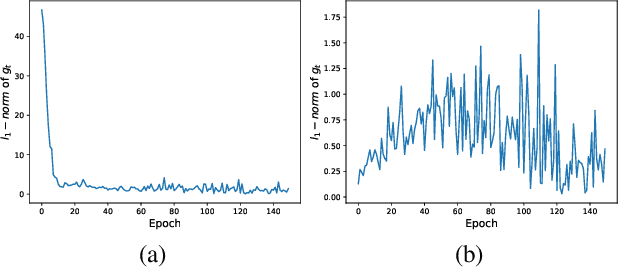

Adaptive optimization methods have been widely used in deep learning. They scale the learning rates adaptively according to the past gradient, which has been shown to be effective to accelerate the convergence. However, they suffer from poor generalization performance compared with SGD. Recent studies point that smoothing exponential gradient noise leads to generalization degeneration phenomenon. Inspired by this, we propose AdaL, with a transformation on the original gradient. AdaL accelerates the convergence by amplifying the gradient in the early stage, as well as dampens the oscillation and stabilizes the optimization by shrinking the gradient later. Such modification alleviates the smoothness of gradient noise, which produces better generalization performance. We have theoretically proved the convergence of AdaL and demonstrated its effectiveness on several benchmarks.
ScoreGrad: Multivariate Probabilistic Time Series Forecasting with Continuous Energy-based Generative Models
Jun 18, 2021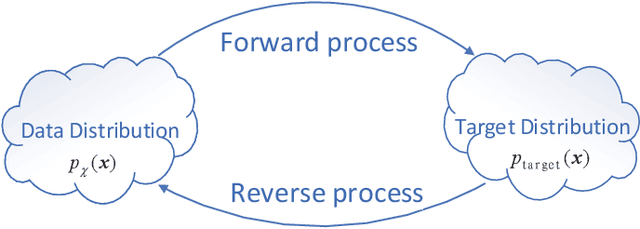
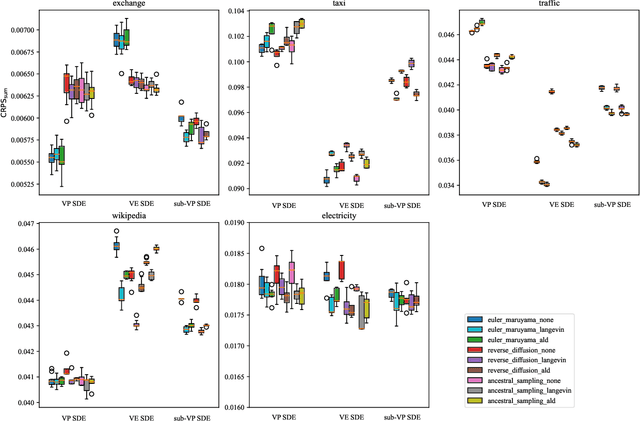
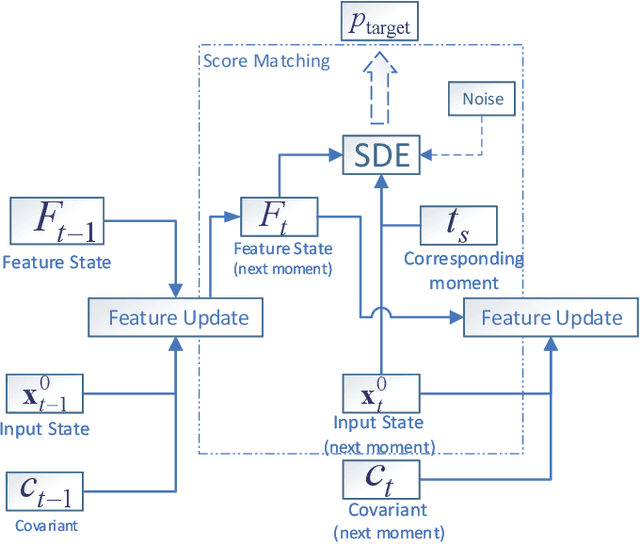
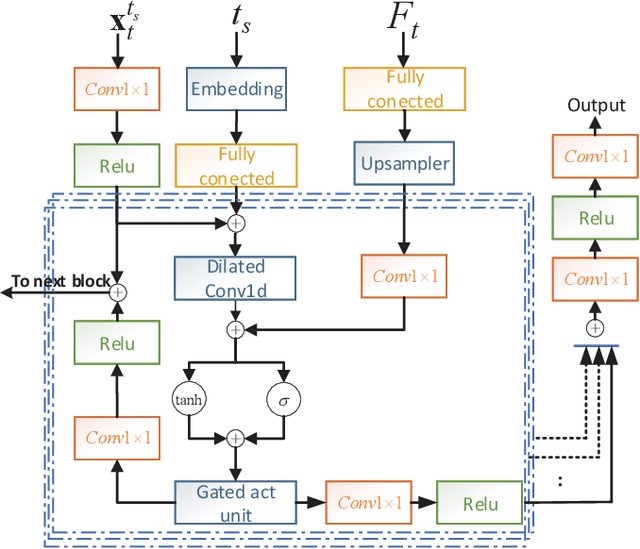
Multivariate time series prediction has attracted a lot of attention because of its wide applications such as intelligence transportation, AIOps. Generative models have achieved impressive results in time series modeling because they can model data distribution and take noise into consideration. However, many existing works can not be widely used because of the constraints of functional form of generative models or the sensitivity to hyperparameters. In this paper, we propose ScoreGrad, a multivariate probabilistic time series forecasting framework based on continuous energy-based generative models. ScoreGrad is composed of time series feature extraction module and conditional stochastic differential equation based score matching module. The prediction can be achieved by iteratively solving reverse-time SDE. To the best of our knowledge, ScoreGrad is the first continuous energy based generative model used for time series forecasting. Furthermore, ScoreGrad achieves state-of-the-art results on six real-world datasets. The impact of hyperparameters and sampler types on the performance are also explored. Code is available at https://github.com/yantijin/ScoreGradPred.