 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFDPM: Attack detection for cyber-physical systems with diffusion probabilistic models
Dec 20, 2021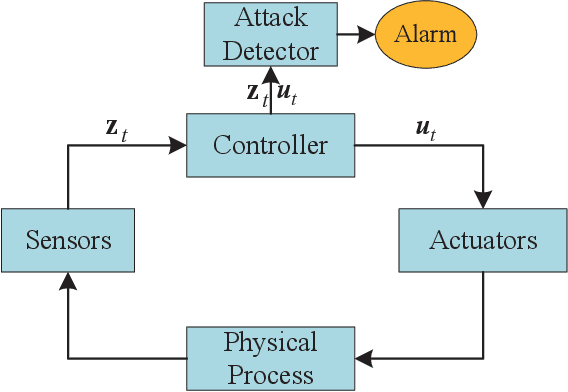

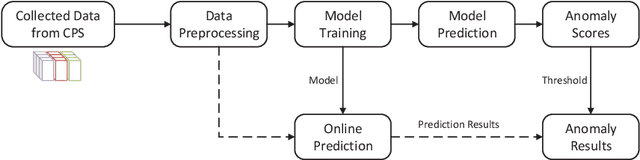
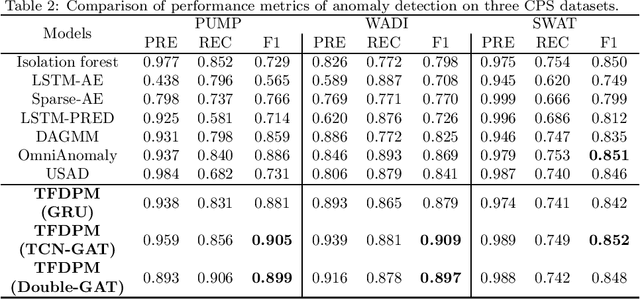
With the development of AIoT, data-driven attack detection methods for cyber-physical systems (CPSs) have attracted lots of attention. However, existing methods usually adopt tractable distributions to approximate data distributions, which are not suitable for complex systems. Besides, the correlation of the data in different channels does not attract sufficient attention. To address these issues, we use energy-based generative models, which are less restrictive on functional forms of the data distribution. In addition, graph neural networks are used to explicitly model the correlation of the data in different channels. In the end, we propose TFDPM, a general framework for attack detection tasks in CPSs. It simultaneously extracts temporal pattern and feature pattern given the historical data. Then extract features are sent to a conditional diffusion probabilistic model. Predicted values can be obtained with the conditional generative network and attacks are detected based on the difference between predicted values and observed values. In addition, to realize real-time detection, a conditional noise scheduling network is proposed to accelerate the prediction process. Experimental results show that TFDPM outperforms existing state-of-the-art attack detection methods. The noise scheduling network increases the detection speed by three times.
AdaL: Adaptive Gradient Transformation Contributes to Convergences and Generalizations
Jul 04, 2021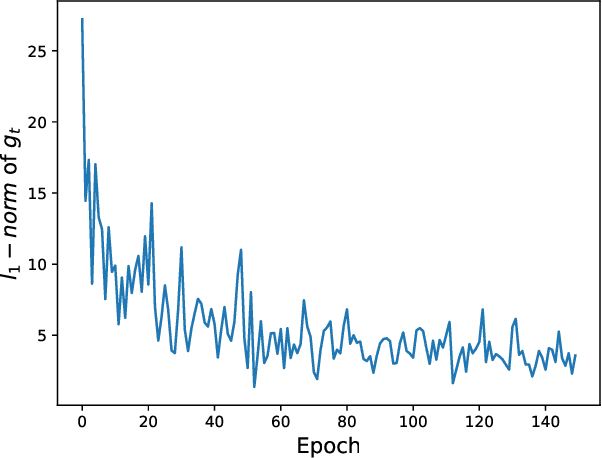

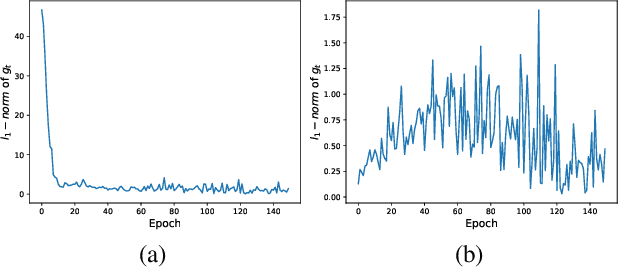

Adaptive optimization methods have been widely used in deep learning. They scale the learning rates adaptively according to the past gradient, which has been shown to be effective to accelerate the convergence. However, they suffer from poor generalization performance compared with SGD. Recent studies point that smoothing exponential gradient noise leads to generalization degeneration phenomenon. Inspired by this, we propose AdaL, with a transformation on the original gradient. AdaL accelerates the convergence by amplifying the gradient in the early stage, as well as dampens the oscillation and stabilizes the optimization by shrinking the gradient later. Such modification alleviates the smoothness of gradient noise, which produces better generalization performance. We have theoretically proved the convergence of AdaL and demonstrated its effectiveness on several benchmarks.
ScoreGrad: Multivariate Probabilistic Time Series Forecasting with Continuous Energy-based Generative Models
Jun 18, 2021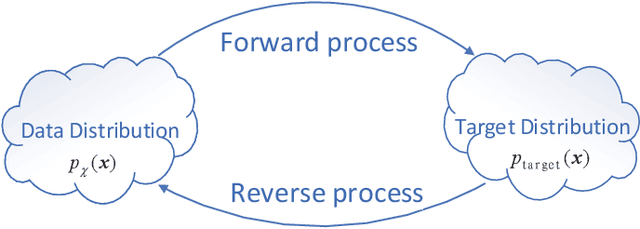
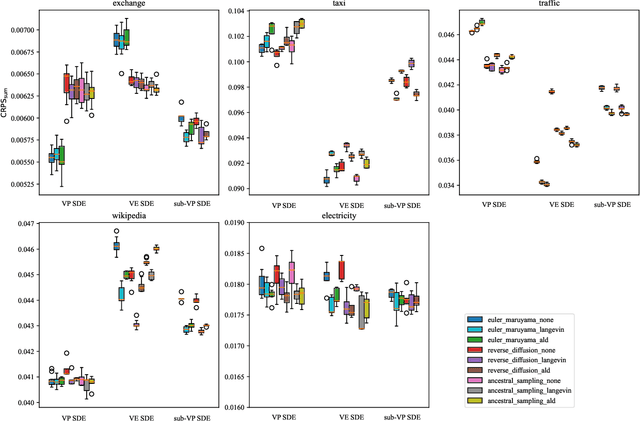
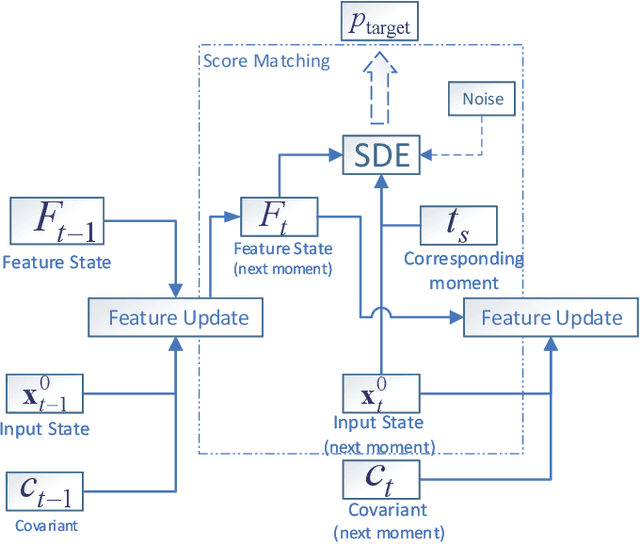
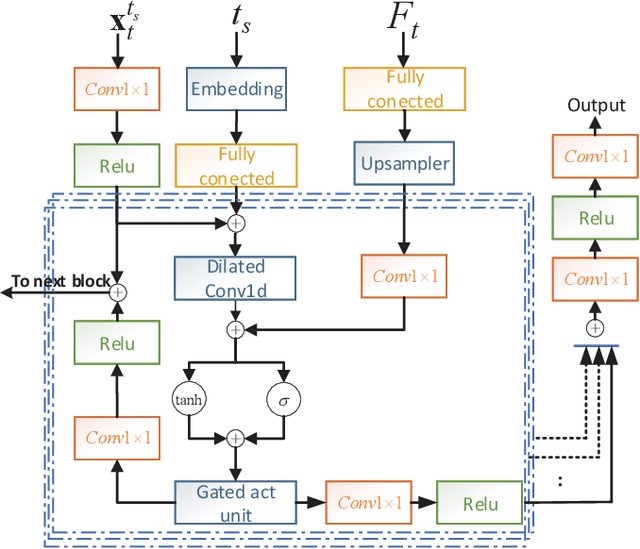
Multivariate time series prediction has attracted a lot of attention because of its wide applications such as intelligence transportation, AIOps. Generative models have achieved impressive results in time series modeling because they can model data distribution and take noise into consideration. However, many existing works can not be widely used because of the constraints of functional form of generative models or the sensitivity to hyperparameters. In this paper, we propose ScoreGrad, a multivariate probabilistic time series forecasting framework based on continuous energy-based generative models. ScoreGrad is composed of time series feature extraction module and conditional stochastic differential equation based score matching module. The prediction can be achieved by iteratively solving reverse-time SDE. To the best of our knowledge, ScoreGrad is the first continuous energy based generative model used for time series forecasting. Furthermore, ScoreGrad achieves state-of-the-art results on six real-world datasets. The impact of hyperparameters and sampler types on the performance are also explored. Code is available at https://github.com/yantijin/ScoreGradPred.
Revisiting Graph Convolutional Network on Semi-Supervised Node Classification from an Optimization Perspective
Sep 25, 2020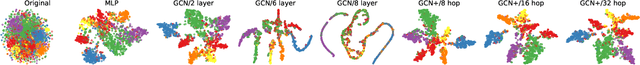
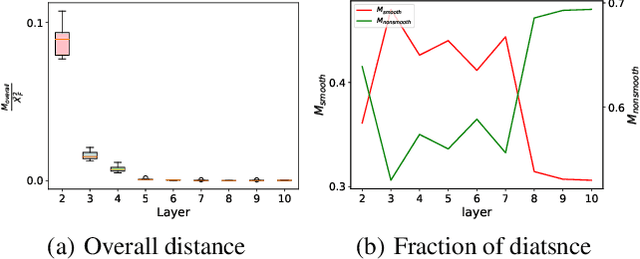
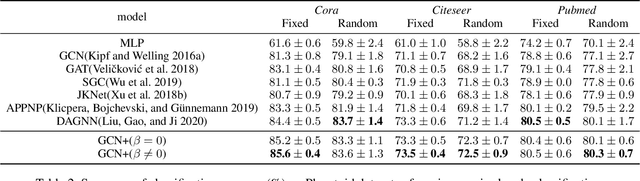
Graph convolutional networks (GCNs) have achieved promising performance on various graph-based tasks. However they suffer from over-smoothing when stacking more layers. In this paper, we present a quantitative study on this observation and develop novel insights towards the deeper GCN. First, we interpret the current graph convolutional operations from an optimization perspective and argue that over-smoothing is mainly caused by the naive first-order approximation of the solution to the optimization problem. Subsequently, we introduce two metrics to measure the over-smoothing on node-level tasks. Specifically, we calculate the fraction of the pairwise distance between connected and disconnected nodes to the overall distance respectively. Based on our theoretical and empirical analysis, we establish a universal theoretical framework of GCN from an optimization perspective and derive a novel convolutional kernel named GCN+ which has lower parameter amount while relieving the over-smoothing inherently. Extensive experiments on real-world datasets demonstrate the superior performance of GCN+ over state-of-the-art baseline methods on the node classification tasks.
Stochastic Graph Recurrent Neural Network
Sep 01, 2020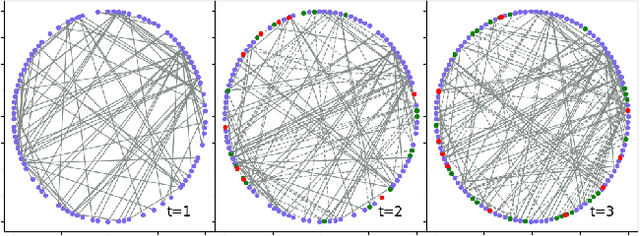
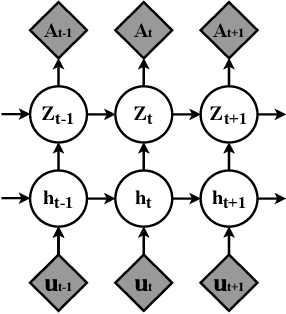
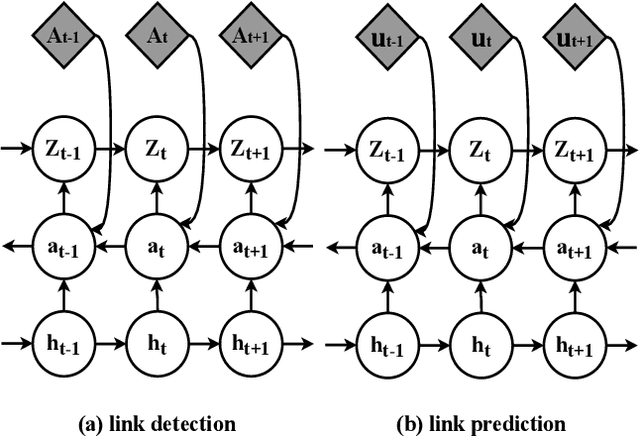
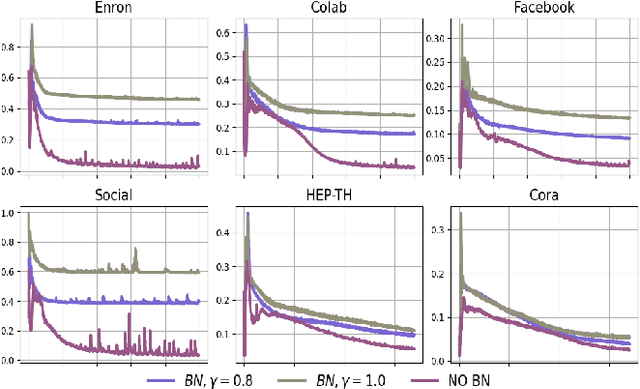
Representation learning over graph structure data has been widely studied due to its wide application prospects. However, previous methods mainly focus on static graphs while many real-world graphs evolve over time. Modeling such evolution is important for predicting properties of unseen networks. To resolve this challenge, we propose SGRNN, a novel neural architecture that applies stochastic latent variables to simultaneously capture the evolution in node attributes and topology. Specifically, deterministic states are separated from stochastic states in the iterative process to suppress mutual interference. With semi-implicit variational inference integrated to SGRNN, a non-Gaussian variational distribution is proposed to help further improve the performance. In addition, to alleviate KL-vanishing problem in SGRNN, a simple and interpretable structure is proposed based on the lower bound of KL-divergence. Extensive experiments on real-world datasets demonstrate the effectiveness of the proposed model. Code is available at https://github.com/StochasticGRNN/SGRNN.