 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapture Uncertainties in Deep Neural Networks for Safe Operation of Autonomous Driving Vehicles
Aug 11, 2021Uncertainties in Deep Neural Network (DNN)-based perception and vehicle's motion pose challenges to the development of safe autonomous driving vehicles. In this paper, we propose a safe motion planning framework featuring the quantification and propagation of DNN-based perception uncertainties and motion uncertainties. Contributions of this work are twofold: (1) A Bayesian Deep Neural network model which detects 3D objects and quantitatively captures the associated aleatoric and epistemic uncertainties of DNNs; (2) An uncertainty-aware motion planning algorithm (PU-RRT) that accounts for uncertainties in object detection and ego-vehicle's motion. The proposed approaches are validated via simulated complex scenarios built in CARLA. Experimental results show that the proposed motion planning scheme can cope with uncertainties of DNN-based perception and vehicle motion, and improve the operational safety of autonomous vehicles while still achieving desirable efficiency.
AdaL: Adaptive Gradient Transformation Contributes to Convergences and Generalizations
Jul 04, 2021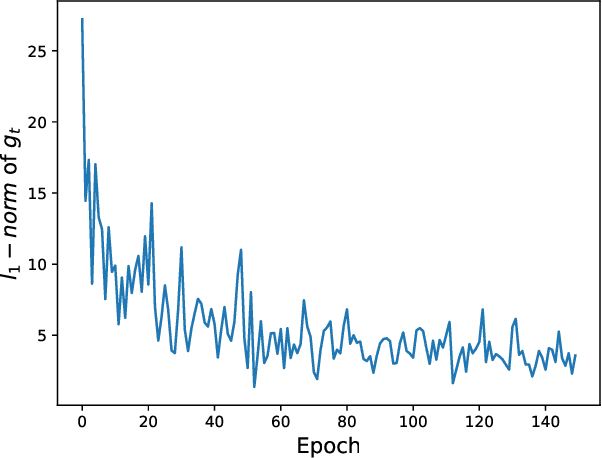

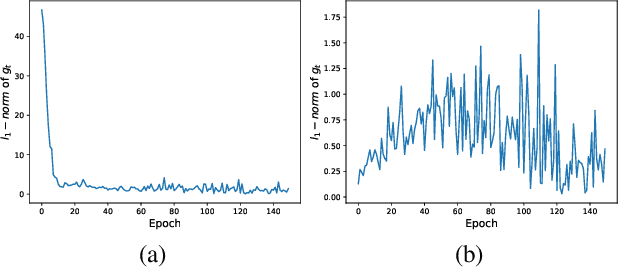

Adaptive optimization methods have been widely used in deep learning. They scale the learning rates adaptively according to the past gradient, which has been shown to be effective to accelerate the convergence. However, they suffer from poor generalization performance compared with SGD. Recent studies point that smoothing exponential gradient noise leads to generalization degeneration phenomenon. Inspired by this, we propose AdaL, with a transformation on the original gradient. AdaL accelerates the convergence by amplifying the gradient in the early stage, as well as dampens the oscillation and stabilizes the optimization by shrinking the gradient later. Such modification alleviates the smoothness of gradient noise, which produces better generalization performance. We have theoretically proved the convergence of AdaL and demonstrated its effectiveness on several benchmarks.
A comparative study of neural network techniques for automatic software vulnerability detection
Apr 29, 2021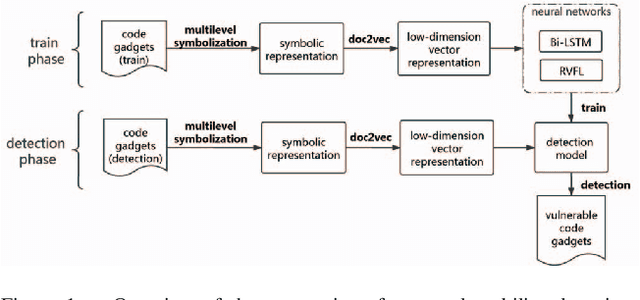
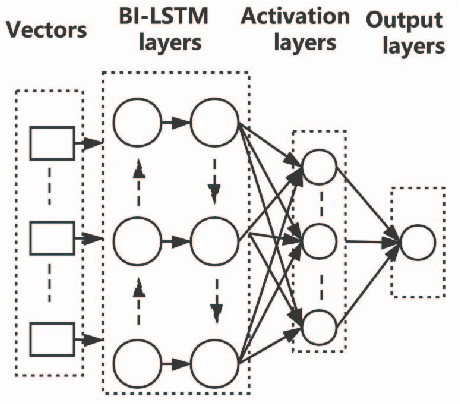
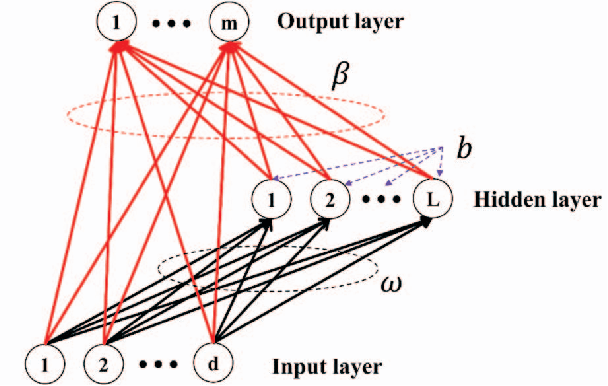
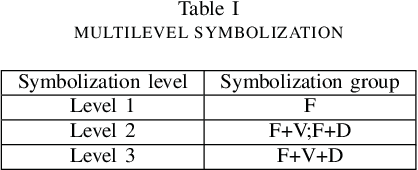
Software vulnerabilities are usually caused by design flaws or implementation errors, which could be exploited to cause damage to the security of the system. At present, the most commonly used method for detecting software vulnerabilities is static analysis. Most of the related technologies work based on rules or code similarity (source code level) and rely on manually defined vulnerability features. However, these rules and vulnerability features are difficult to be defined and designed accurately, which makes static analysis face many challenges in practical applications. To alleviate this problem, some researchers have proposed to use neural networks that have the ability of automatic feature extraction to improve the intelligence of detection. However, there are many types of neural networks, and different data preprocessing methods will have a significant impact on model performance. It is a great challenge for engineers and researchers to choose a proper neural network and data preprocessing method for a given problem. To solve this problem, we have conducted extensive experiments to test the performance of the two most typical neural networks (i.e., Bi-LSTM and RVFL) with the two most classical data preprocessing methods (i.e., the vector representation and the program symbolization methods) on software vulnerability detection problems and obtained a series of interesting research conclusions, which can provide valuable guidelines for researchers and engineers. Specifically, we found that 1) the training speed of RVFL is always faster than BiLSTM, but the prediction accuracy of Bi-LSTM model is higher than RVFL; 2) using doc2vec for vector representation can make the model have faster training speed and generalization ability than using word2vec; and 3) multi-level symbolization is helpful to improve the precision of neural network models.
A Biologically Inspired Feature Enhancement Framework for Zero-Shot Learning
May 13, 2020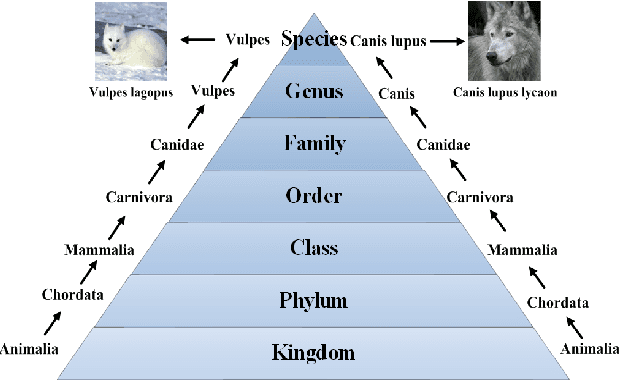
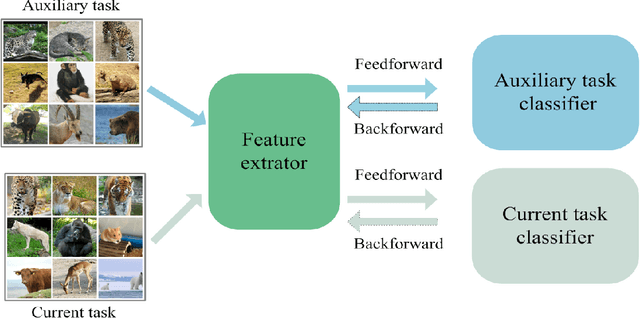
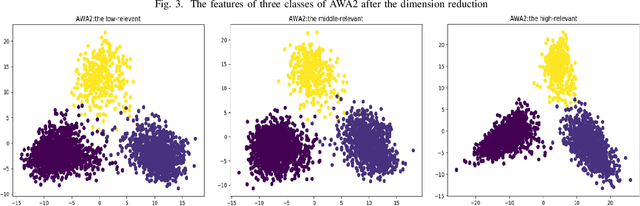
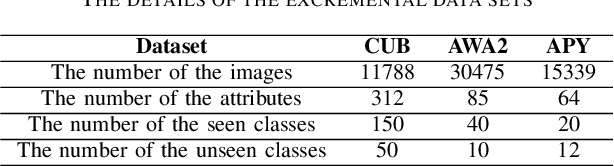
Most of the Zero-Shot Learning (ZSL) algorithms currently use pre-trained models as their feature extractors, which are usually trained on the ImageNet data set by using deep neural networks. The richness of the feature information embedded in the pre-trained models can help the ZSL model extract more useful features from its limited training samples. However, sometimes the difference between the training data set of the current ZSL task and the ImageNet data set is too large, which may lead to the use of pre-trained models has no obvious help or even negative impact on the performance of the ZSL model. To solve this problem, this paper proposes a biologically inspired feature enhancement framework for ZSL. Specifically, we design a dual-channel learning framework that uses auxiliary data sets to enhance the feature extractor of the ZSL model and propose a novel method to guide the selection of the auxiliary data sets based on the knowledge of biological taxonomy. Extensive experimental results show that our proposed method can effectively improve the generalization ability of the ZSL model and achieve state-of-the-art results on three benchmark ZSL tasks. We also explained the experimental phenomena through the way of feature visualization.