 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding the Correct Visual Evidence Without Forgetting: Mitigating Hallucination in LVLMs via Inter-Layer Visual Attention Discrepancy
May 20, 2026Large Vision-Language Models (LVLMs) have shown remarkable performance on a wide range of vision-language tasks. Despite this progress, they are still prone to hallucination, generating responses that are inconsistent with visual content. In this work, we find that LVLMs tend to hallucinate when they pay insufficient attention to the correct visual evidence and gradually forget it during the generation process. We empirically find that although LVLMs overall attend insufficiently to visual evidence, they exhibit sensitivity to the correct visual evidence in specific layers, with notable inter-layer discrepancy. Motivated by this observation, we propose a novel hallucination mitigation method that enhances visual evidence based on Inter-Layer Visual Attention Discrepancy (ILVAD). Specifically, we obtain the attention weights from early generated tokens to visual tokens across layers and identify the tokens that are repeatedly activated as visual evidence, forming a saliency map. We then enhance attention to visual evidence during generation through the saliency map to reduce visual forgetting. In addition, we leverage the saliency map to obtain attention scores of generated text to visual evidence, in order to select and emphasize text tokens that are strongly grounded in visual evidence. Our method is training-free and plug-and-play. Multiple benchmark evaluations conducted on five recently released models show that our method can consistently mitigate hallucinations in different LVLMs over various architectures. Code is available at https://github.com/ytx-ML/ILVAD.
Oracle-guided Contrastive Clustering
Nov 01, 2022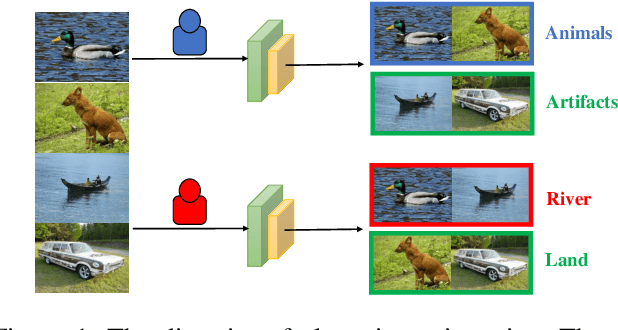
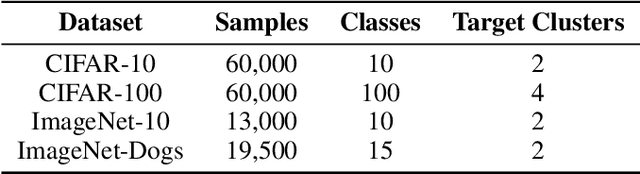
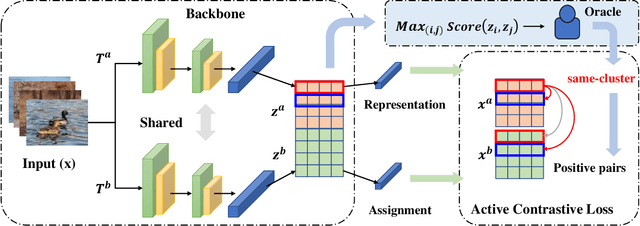
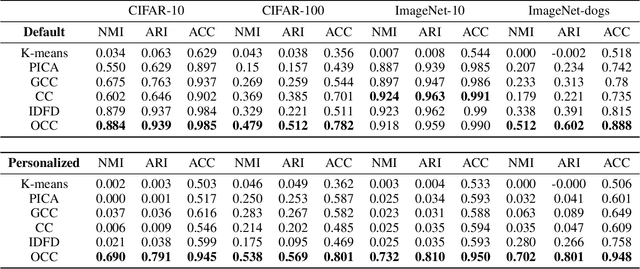
Deep clustering aims to learn a clustering representation through deep architectures. Most of the existing methods usually conduct clustering with the unique goal of maximizing clustering performance, that ignores the personalized demand of clustering tasks.% and results in unguided clustering solutions. However, in real scenarios, oracles may tend to cluster unlabeled data by exploiting distinct criteria, such as distinct semantics (background, color, object, etc.), and then put forward personalized clustering tasks. To achieve task-aware clustering results, in this study, Oracle-guided Contrastive Clustering(OCC) is then proposed to cluster by interactively making pairwise ``same-cluster" queries to oracles with distinctive demands. Specifically, inspired by active learning, some informative instance pairs are queried, and evaluated by oracles whether the pairs are in the same cluster according to their desired orientation. And then these queried same-cluster pairs extend the set of positive instance pairs for contrastive learning, guiding OCC to extract orientation-aware feature representation. Accordingly, the query results, guided by oracles with distinctive demands, may drive the OCC's clustering results in a desired orientation. Theoretically, the clustering risk in an active learning manner is given with a tighter upper bound, that guarantees active queries to oracles do mitigate the clustering risk. Experimentally, extensive results verify that OCC can cluster accurately along the specific orientation and it substantially outperforms the SOTA clustering methods as well. To the best of our knowledge, it is the first deep framework to perform personalized clustering.
An Accelerator for Rule Induction in Fuzzy Rough Theory
Jan 07, 2022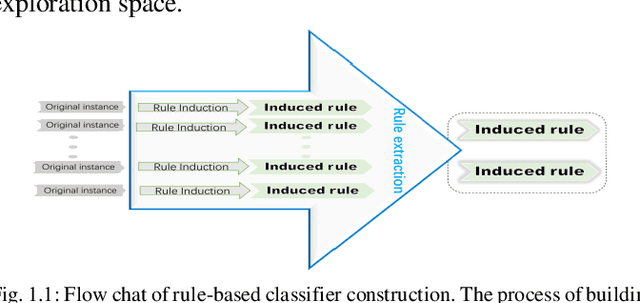
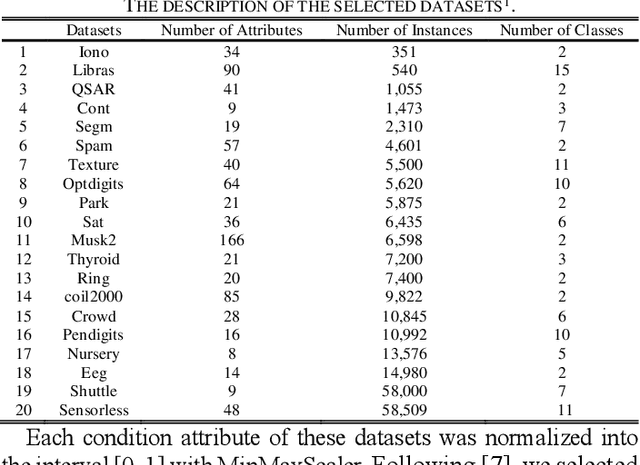
Rule-based classifier, that extract a subset of induced rules to efficiently learn/mine while preserving the discernibility information, plays a crucial role in human-explainable artificial intelligence. However, in this era of big data, rule induction on the whole datasets is computationally intensive. So far, to the best of our knowledge, no known method focusing on accelerating rule induction has been reported. This is first study to consider the acceleration technique to reduce the scale of computation in rule induction. We propose an accelerator for rule induction based on fuzzy rough theory; the accelerator can avoid redundant computation and accelerate the building of a rule classifier. First, a rule induction method based on consistence degree, called Consistence-based Value Reduction (CVR), is proposed and used as basis to accelerate. Second, we introduce a compacted search space termed Key Set, which only contains the key instances required to update the induced rule, to conduct value reduction. The monotonicity of Key Set ensures the feasibility of our accelerator. Third, a rule-induction accelerator is designed based on Key Set, and it is theoretically guaranteed to display the same results as the unaccelerated version. Specifically, the rank preservation property of Key Set ensures consistency between the rule induction achieved by the accelerator and the unaccelerated method. Finally, extensive experiments demonstrate that the proposed accelerator can perform remarkably faster than the unaccelerated rule-based classifier methods, especially on datasets with numerous instances.
A Survey on Epistemic (Model) Uncertainty in Supervised Learning: Recent Advances and Applications
Nov 04, 2021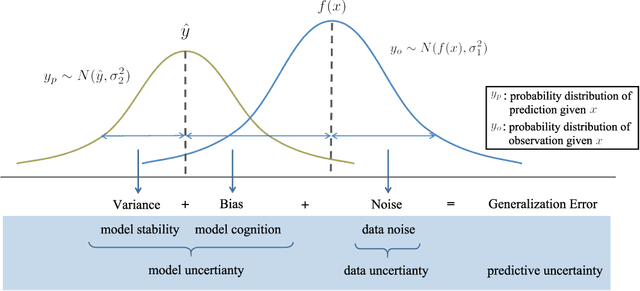
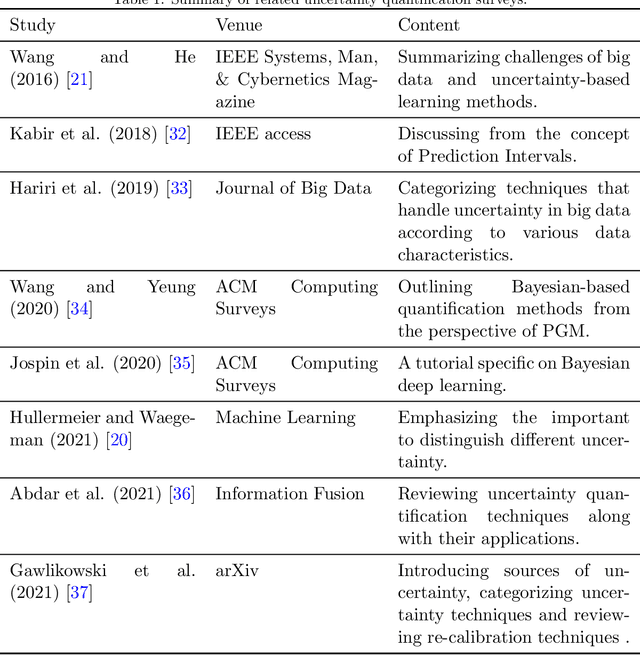
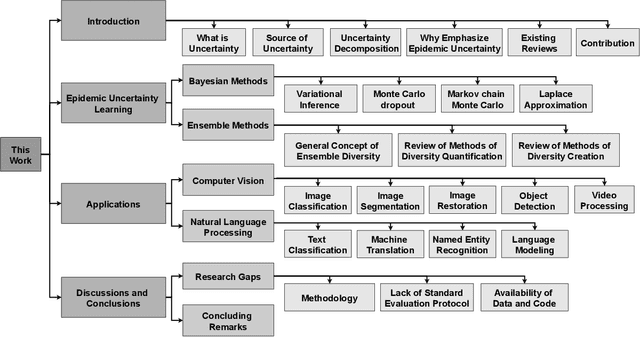
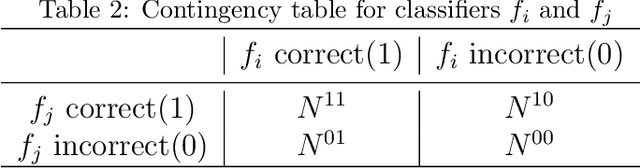
Quantifying the uncertainty of supervised learning models plays an important role in making more reliable predictions. Epistemic uncertainty, which usually is due to insufficient knowledge about the model, can be reduced by collecting more data or refining the learning models. Over the last few years, scholars have proposed many epistemic uncertainty handling techniques which can be roughly grouped into two categories, i.e., Bayesian and ensemble. This paper provides a comprehensive review of epistemic uncertainty learning techniques in supervised learning over the last five years. As such, we, first, decompose the epistemic uncertainty into bias and variance terms. Then, a hierarchical categorization of epistemic uncertainty learning techniques along with their representative models is introduced. In addition, several applications such as computer vision (CV) and natural language processing (NLP) are presented, followed by a discussion on research gaps and possible future research directions.
Adversarial Learning with Cost-Sensitive Classes
Jan 29, 2021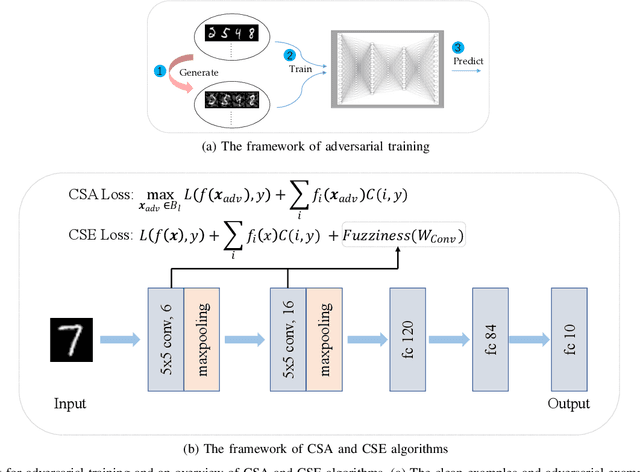

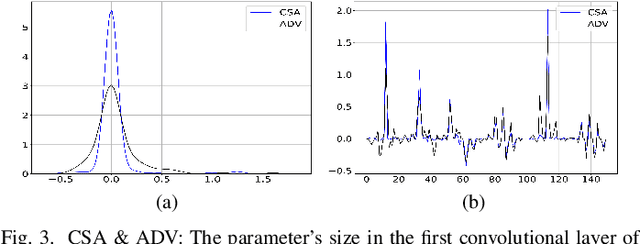
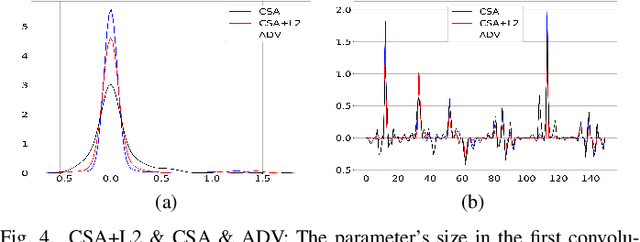
It is necessary to improve the performance of some special classes or to particularly protect them from attacks in adversarial learning. This paper proposes a framework combining cost-sensitive classification and adversarial learning together to train a model that can distinguish between protected and unprotected classes, such that the protected classes are less vulnerable to adversarial examples. We find in this framework an interesting phenomenon during the training of deep neural networks, called Min-Max property, that is, the absolute values of most parameters in the convolutional layer approach zero while the absolute values of a few parameters are significantly larger becoming bigger. Based on this Min-Max property which is formulated and analyzed in a view of random distribution, we further build a new defense model against adversarial examples for adversarial robustness improvement. An advantage of the built model is that it does no longer need adversarial training, and thus, has a higher computational efficiency than most existing models of needing adversarial training. It is experimentally confirmed that, regarding the average accuracy of all classes, our model is almost as same as the existing models when an attack does not occur and is better than the existing models when an attack occurs. Specifically, regarding the accuracy of protected classes, the proposed model is much better than the existing models when an attack occurs.
Generalized Adversarial Examples: Attacks and Defenses
Nov 28, 2020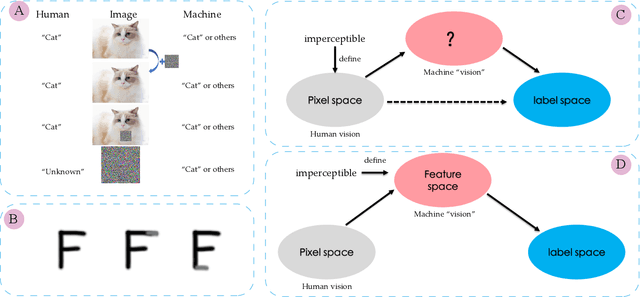
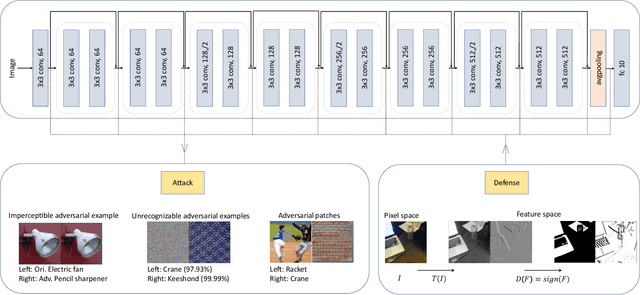

Most of the works follow such definition of adversarial example that is imperceptible to humans but can fool the deep neural networks (DNNs). Some works find another interesting form of adversarial examples such as one which is unrecognizable to humans, but DNNs classify it as one class with high confidence and adversarial patch. Based on this phenomenon, in this paper, from the perspective of cognition of humans and machines, we propose a new definition of adversarial examples. We show that imperceptible adversarial examples, unrecognizable adversarial examples, and adversarial patches are derivates of generalized adversarial examples. Then, we propose three types of adversarial attacks based on the generalized definition. Finally, we propose a defence mechanism that achieves state-of-the-art performance. We construct a lossy compression function to filter out the redundant features generated by the network. In this process, the perturbation produced by the attacker will be filtered out. Therefore, the defence mechanism can effectively improve the robustness of the model. The experiments show that our attack methods can effectively generate adversarial examples, and our defence method can significantly improve the adversarial robustness of DNNs compared with adversarial training. As far as we know, our defending method achieves the best performance even though we do not adopt adversarial training.
A Biologically Inspired Feature Enhancement Framework for Zero-Shot Learning
May 13, 2020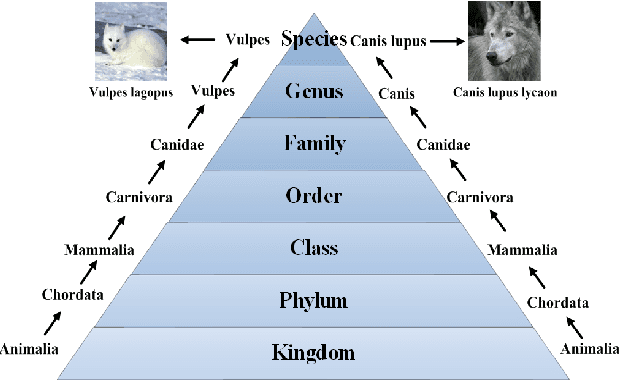
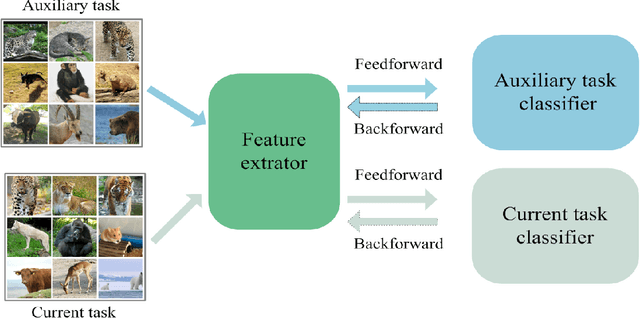
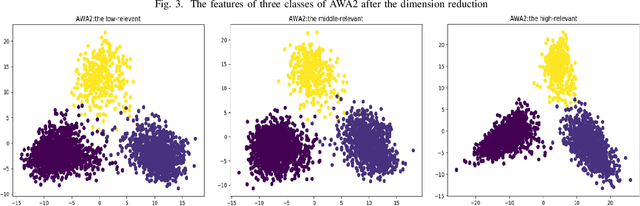
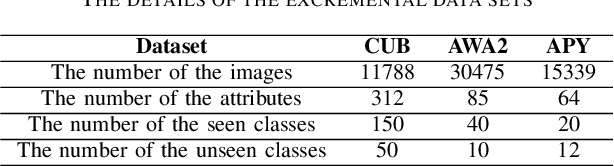
Most of the Zero-Shot Learning (ZSL) algorithms currently use pre-trained models as their feature extractors, which are usually trained on the ImageNet data set by using deep neural networks. The richness of the feature information embedded in the pre-trained models can help the ZSL model extract more useful features from its limited training samples. However, sometimes the difference between the training data set of the current ZSL task and the ImageNet data set is too large, which may lead to the use of pre-trained models has no obvious help or even negative impact on the performance of the ZSL model. To solve this problem, this paper proposes a biologically inspired feature enhancement framework for ZSL. Specifically, we design a dual-channel learning framework that uses auxiliary data sets to enhance the feature extractor of the ZSL model and propose a novel method to guide the selection of the auxiliary data sets based on the knowledge of biological taxonomy. Extensive experimental results show that our proposed method can effectively improve the generalization ability of the ZSL model and achieve state-of-the-art results on three benchmark ZSL tasks. We also explained the experimental phenomena through the way of feature visualization.