 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Curriculum Pre-Alignment for Domain-Adaptive VLMs
Feb 11, 2026Vision-Language Models (VLMs) demonstrate remarkable general-purpose capabilities but often fall short in specialized domains such as medical imaging or geometric problem-solving. Supervised Fine-Tuning (SFT) can enhance performance within a target domain, but it typically causes catastrophic forgetting, limiting its generalization. The central challenge, therefore, is to adapt VLMs to new domains while preserving their general-purpose capabilities. Continual pretraining is effective for expanding knowledge in Large Language Models (LLMs), but it is less feasible for VLMs due to prohibitive computational costs and the unavailability of pretraining data for most open-source models. This necessitates efficient post-training adaptation methods. Reinforcement learning (RL)-based approaches such as Group Relative Policy Optimization (GRPO) have shown promise in preserving general abilities, yet they often fail in domain adaptation scenarios where the model initially lacks sufficient domain knowledge, leading to optimization collapse. To bridge this gap, we propose Reinforced Curriculum Pre-Alignment (RCPA), a novel post-training paradigm that introduces a curriculum-aware progressive modulation mechanism. In the early phase, RCPA applies partial output constraints to safely expose the model to new domain concepts. As the model's domain familiarity increases, training gradually transitions to full generation optimization, refining responses and aligning them with domain-specific preferences. This staged adaptation balances domain knowledge acquisition with the preservation of general multimodal capabilities. Extensive experiments across specialized domains and general benchmarks validate the effectiveness of RCPA, establishing a practical pathway toward building high-performing and domain-adaptive VLMs.
Enhanced Few-Shot Class-Incremental Learning via Ensemble Models
Jan 14, 2024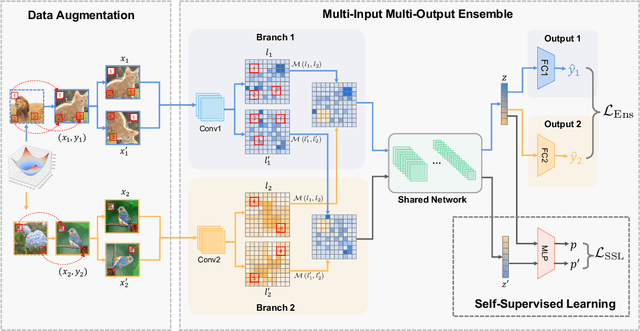
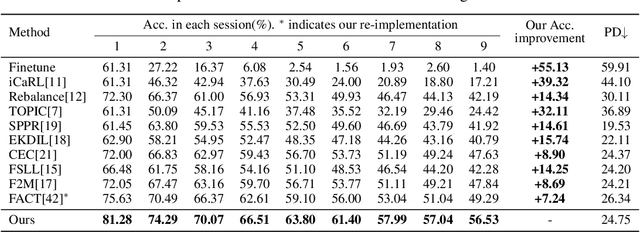
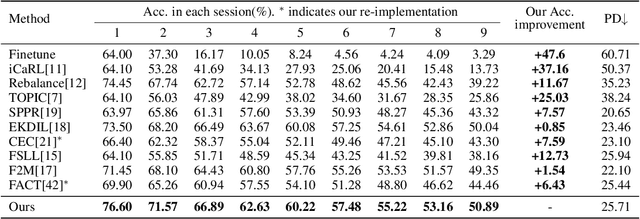
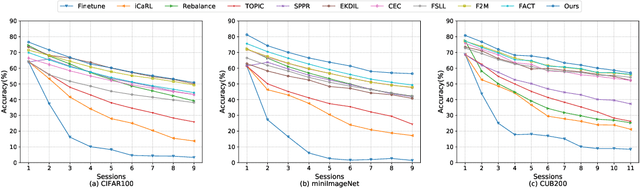
Few-shot class-incremental learning (FSCIL) aims to continually fit new classes with limited training data, while maintaining the performance of previously learned classes. The main challenges are overfitting the rare new training samples and forgetting old classes. While catastrophic forgetting has been extensively studied, the overfitting problem has attracted less attention in FSCIL. To tackle overfitting challenge, we design a new ensemble model framework cooperated with data augmentation to boost generalization. In this way, the enhanced model works as a library storing abundant features to guarantee fast adaptation to downstream tasks. Specifically, the multi-input multi-output ensemble structure is applied with a spatial-aware data augmentation strategy, aiming at diversifying the feature extractor and alleviating overfitting in incremental sessions. Moreover, self-supervised learning is also integrated to further improve the model generalization. Comprehensive experimental results show that the proposed method can indeed mitigate the overfitting problem in FSCIL, and outperform the state-of-the-art methods.
Generalized Graph Prompt: Toward a Unification of Pre-Training and Downstream Tasks on Graphs
Nov 26, 2023



Graph neural networks have emerged as a powerful tool for graph representation learning, but their performance heavily relies on abundant task-specific supervision. To reduce labeling requirement, the "pre-train, prompt" paradigms have become increasingly common. However, existing study of prompting on graphs is limited, lacking a universal treatment to appeal to different downstream tasks. In this paper, we propose GraphPrompt, a novel pre-training and prompting framework on graphs. GraphPrompt not only unifies pre-training and downstream tasks into a common task template but also employs a learnable prompt to assist a downstream task in locating the most relevant knowledge from the pre-trained model in a task-specific manner. To further enhance GraphPrompt in these two stages, we extend it into GraphPrompt+ with two major enhancements. First, we generalize several popular graph pre-training tasks beyond simple link prediction to broaden the compatibility with our task template. Second, we propose a more generalized prompt design that incorporates a series of prompt vectors within every layer of the pre-trained graph encoder, in order to capitalize on the hierarchical information across different layers beyond just the readout layer. Finally, we conduct extensive experiments on five public datasets to evaluate and analyze GraphPrompt and GraphPrompt+.
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022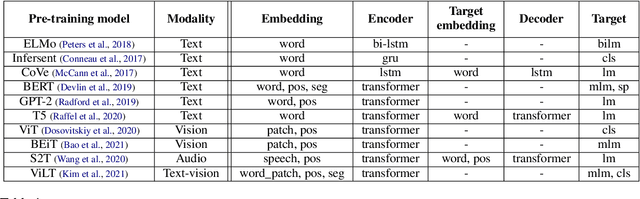
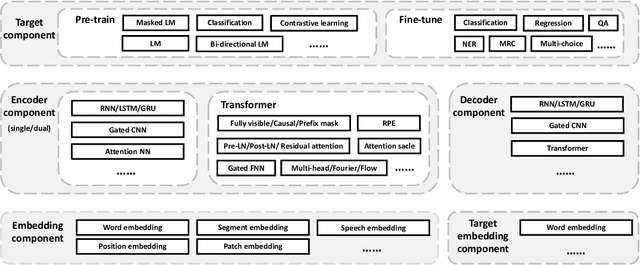
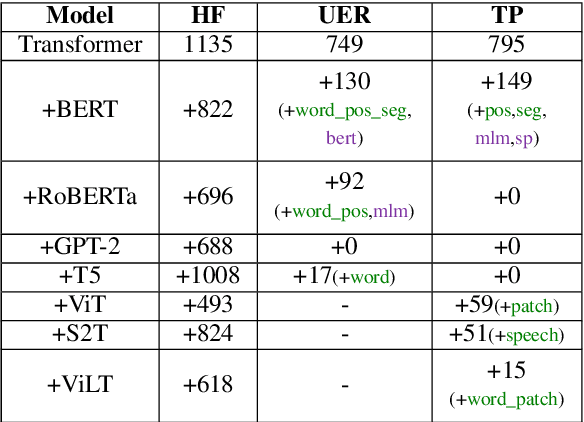
Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.
M2HF: Multi-level Multi-modal Hybrid Fusion for Text-Video Retrieval
Aug 16, 2022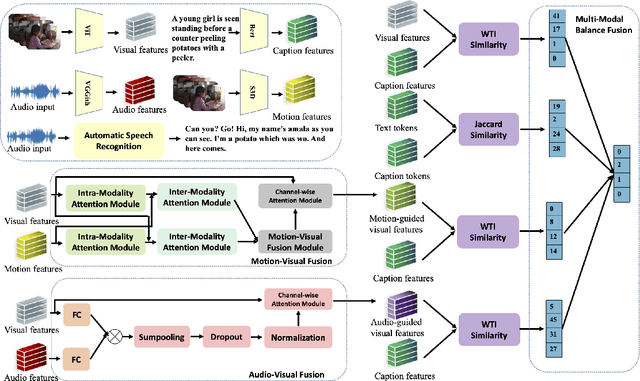
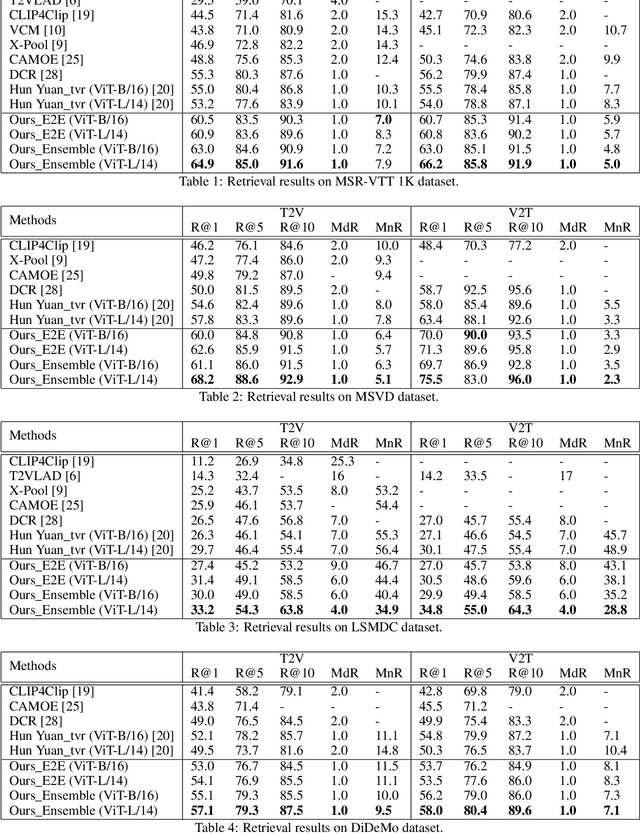


Videos contain multi-modal content, and exploring multi-level cross-modal interactions with natural language queries can provide great prominence to text-video retrieval task (TVR). However, new trending methods applying large-scale pre-trained model CLIP for TVR do not focus on multi-modal cues in videos. Furthermore, the traditional methods simply concatenating multi-modal features do not exploit fine-grained cross-modal information in videos. In this paper, we propose a multi-level multi-modal hybrid fusion (M2HF) network to explore comprehensive interactions between text queries and each modality content in videos. Specifically, M2HF first utilizes visual features extracted by CLIP to early fuse with audio and motion features extracted from videos, obtaining audio-visual fusion features and motion-visual fusion features respectively. Multi-modal alignment problem is also considered in this process. Then, visual features, audio-visual fusion features, motion-visual fusion features, and texts extracted from videos establish cross-modal relationships with caption queries in a multi-level way. Finally, the retrieval outputs from all levels are late fused to obtain final text-video retrieval results. Our framework provides two kinds of training strategies, including an ensemble manner and an end-to-end manner. Moreover, a novel multi-modal balance loss function is proposed to balance the contributions of each modality for efficient end-to-end training. M2HF allows us to obtain state-of-the-art results on various benchmarks, eg, Rank@1 of 64.9\%, 68.2\%, 33.2\%, 57.1\%, 57.8\% on MSR-VTT, MSVD, LSMDC, DiDeMo, and ActivityNet, respectively.
Maximize the Exploration of Congeneric Semantics for Weakly Supervised Semantic Segmentation
Oct 08, 2021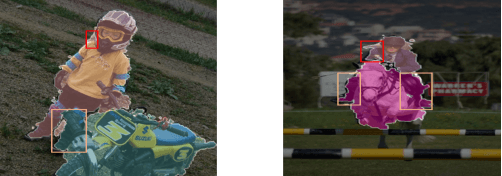

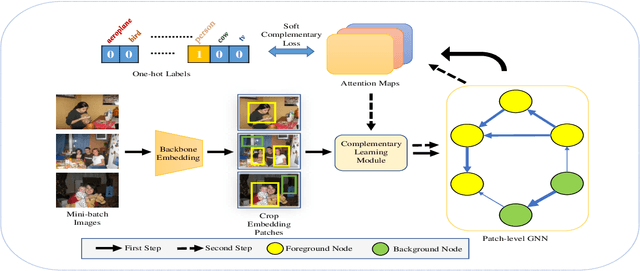
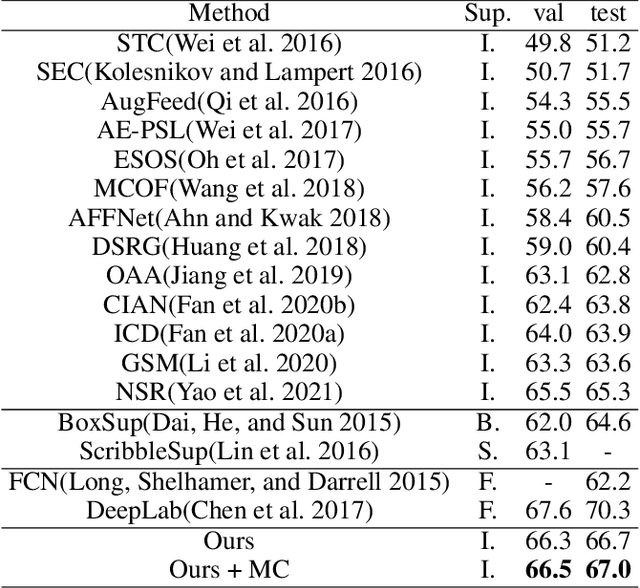
With the increase in the number of image data and the lack of corresponding labels, weakly supervised learning has drawn a lot of attention recently in computer vision tasks, especially in the fine-grained semantic segmentation problem. To alleviate human efforts from expensive pixel-by-pixel annotations, our method focuses on weakly supervised semantic segmentation (WSSS) with image-level tags, which are much easier to obtain. As a huge gap exists between pixel-level segmentation and image-level labels, how to reflect the image-level semantic information on each pixel is an important question. To explore the congeneric semantic regions from the same class to the maximum, we construct the patch-level graph neural network (P-GNN) based on the self-detected patches from different images that contain the same class labels. Patches can frame the objects as much as possible and include as little background as possible. The graph network that is established with patches as the nodes can maximize the mutual learning of similar objects. We regard the embedding vectors of patches as nodes, and use transformer-based complementary learning module to construct weighted edges according to the embedding similarity between different nodes. Moreover, to better supplement semantic information, we propose soft-complementary loss functions matched with the whole network structure. We conduct experiments on the popular PASCAL VOC 2012 benchmarks, and our model yields state-of-the-art performance.
The Medical Segmentation Decathlon
Jun 10, 2021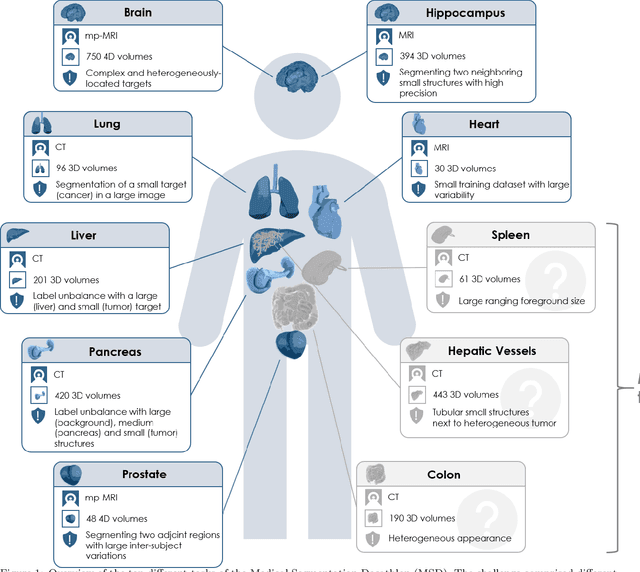
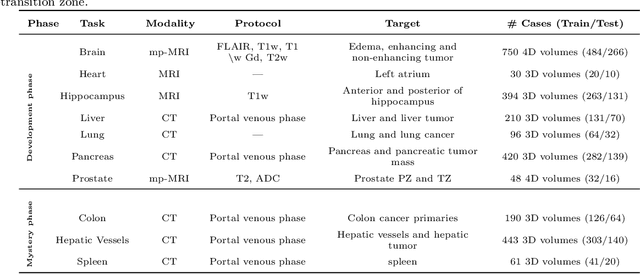
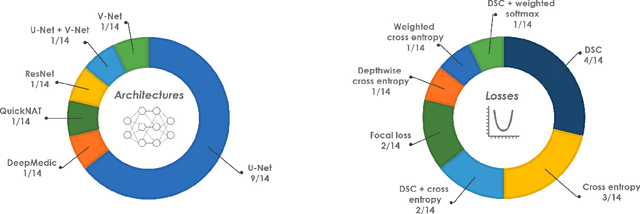
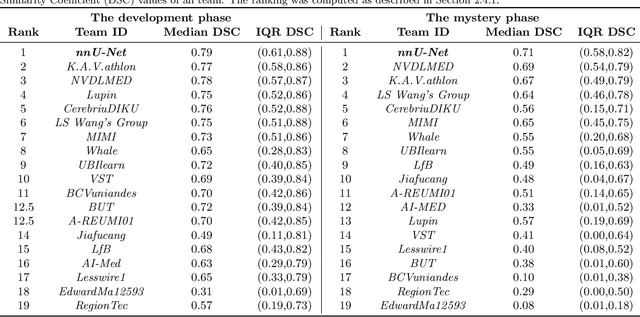
International challenges have become the de facto standard for comparative assessment of image analysis algorithms given a specific task. Segmentation is so far the most widely investigated medical image processing task, but the various segmentation challenges have typically been organized in isolation, such that algorithm development was driven by the need to tackle a single specific clinical problem. We hypothesized that a method capable of performing well on multiple tasks will generalize well to a previously unseen task and potentially outperform a custom-designed solution. To investigate the hypothesis, we organized the Medical Segmentation Decathlon (MSD) - a biomedical image analysis challenge, in which algorithms compete in a multitude of both tasks and modalities. The underlying data set was designed to explore the axis of difficulties typically encountered when dealing with medical images, such as small data sets, unbalanced labels, multi-site data and small objects. The MSD challenge confirmed that algorithms with a consistent good performance on a set of tasks preserved their good average performance on a different set of previously unseen tasks. Moreover, by monitoring the MSD winner for two years, we found that this algorithm continued generalizing well to a wide range of other clinical problems, further confirming our hypothesis. Three main conclusions can be drawn from this study: (1) state-of-the-art image segmentation algorithms are mature, accurate, and generalize well when retrained on unseen tasks; (2) consistent algorithmic performance across multiple tasks is a strong surrogate of algorithmic generalizability; (3) the training of accurate AI segmentation models is now commoditized to non AI experts.
Adversarial Learning with Cost-Sensitive Classes
Jan 29, 2021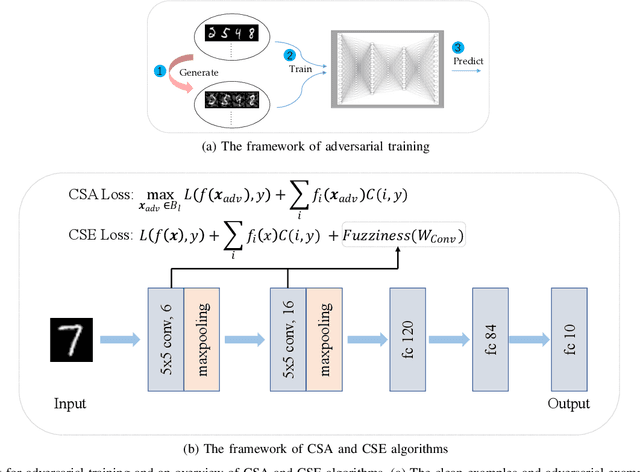

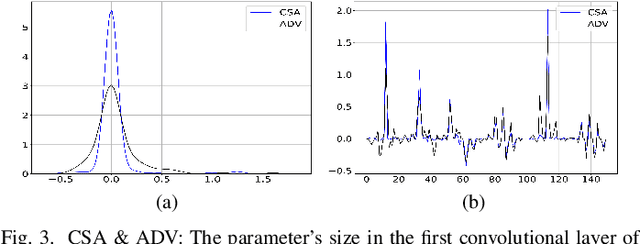
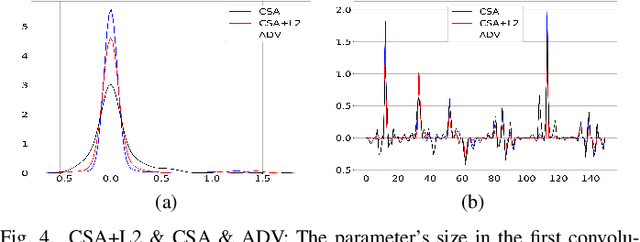
It is necessary to improve the performance of some special classes or to particularly protect them from attacks in adversarial learning. This paper proposes a framework combining cost-sensitive classification and adversarial learning together to train a model that can distinguish between protected and unprotected classes, such that the protected classes are less vulnerable to adversarial examples. We find in this framework an interesting phenomenon during the training of deep neural networks, called Min-Max property, that is, the absolute values of most parameters in the convolutional layer approach zero while the absolute values of a few parameters are significantly larger becoming bigger. Based on this Min-Max property which is formulated and analyzed in a view of random distribution, we further build a new defense model against adversarial examples for adversarial robustness improvement. An advantage of the built model is that it does no longer need adversarial training, and thus, has a higher computational efficiency than most existing models of needing adversarial training. It is experimentally confirmed that, regarding the average accuracy of all classes, our model is almost as same as the existing models when an attack does not occur and is better than the existing models when an attack occurs. Specifically, regarding the accuracy of protected classes, the proposed model is much better than the existing models when an attack occurs.
Generalized Adversarial Examples: Attacks and Defenses
Nov 28, 2020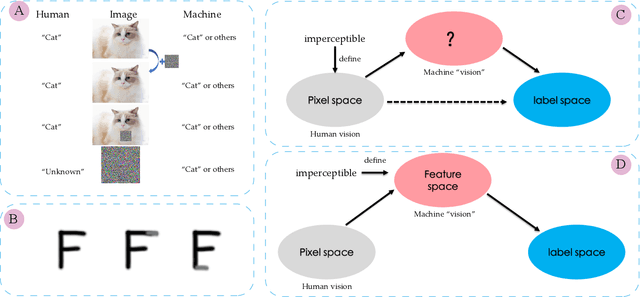
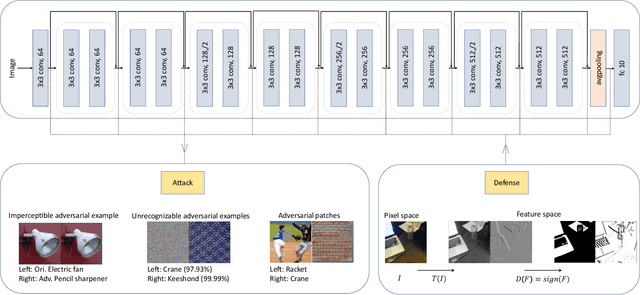
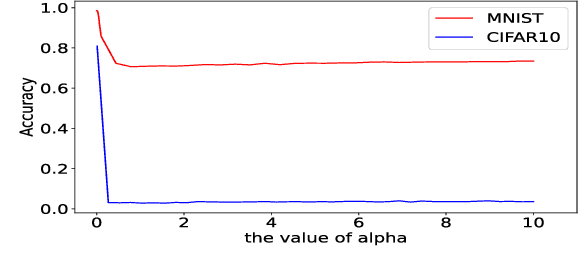

Most of the works follow such definition of adversarial example that is imperceptible to humans but can fool the deep neural networks (DNNs). Some works find another interesting form of adversarial examples such as one which is unrecognizable to humans, but DNNs classify it as one class with high confidence and adversarial patch. Based on this phenomenon, in this paper, from the perspective of cognition of humans and machines, we propose a new definition of adversarial examples. We show that imperceptible adversarial examples, unrecognizable adversarial examples, and adversarial patches are derivates of generalized adversarial examples. Then, we propose three types of adversarial attacks based on the generalized definition. Finally, we propose a defence mechanism that achieves state-of-the-art performance. We construct a lossy compression function to filter out the redundant features generated by the network. In this process, the perturbation produced by the attacker will be filtered out. Therefore, the defence mechanism can effectively improve the robustness of the model. The experiments show that our attack methods can effectively generate adversarial examples, and our defence method can significantly improve the adversarial robustness of DNNs compared with adversarial training. As far as we know, our defending method achieves the best performance even though we do not adopt adversarial training.
A Study on the Uncertainty of Convolutional Layers in Deep Neural Networks
Nov 27, 2020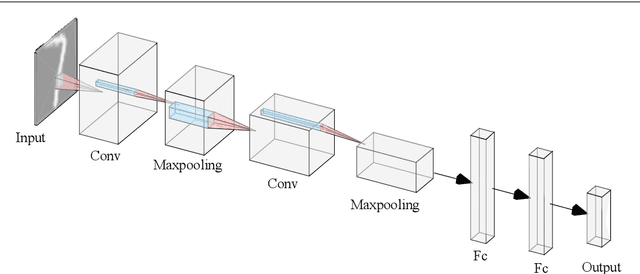
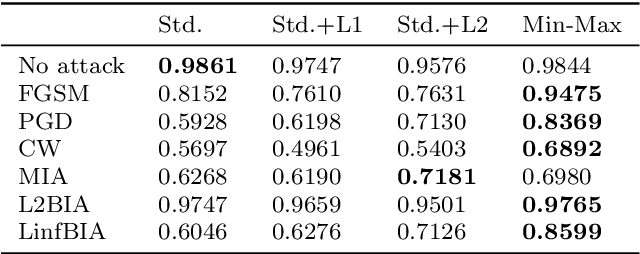
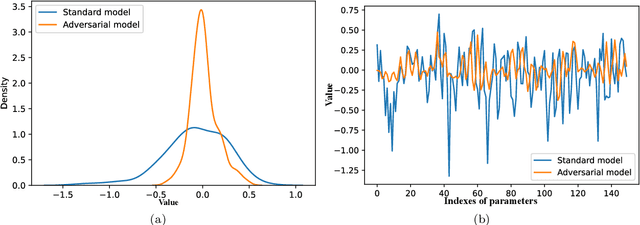
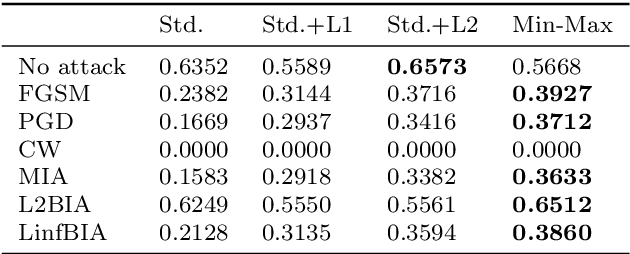
This paper shows a Min-Max property existing in the connection weights of the convolutional layers in a neural network structure, i.e., the LeNet. Specifically, the Min-Max property means that, during the back propagation-based training for LeNet, the weights of the convolutional layers will become far away from their centers of intervals, i.e., decreasing to their minimum or increasing to their maximum. From the perspective of uncertainty, we demonstrate that the Min-Max property corresponds to minimizing the fuzziness of the model parameters through a simplified formulation of convolution. It is experimentally confirmed that the model with the Min-Max property has a stronger adversarial robustness, thus this property can be incorporated into the design of loss function. This paper points out a changing tendency of uncertainty in the convolutional layers of LeNet structure, and gives some insights to the interpretability of convolution.