 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2HF: Multi-level Multi-modal Hybrid Fusion for Text-Video Retrieval
Paper and Code
Aug 16, 2022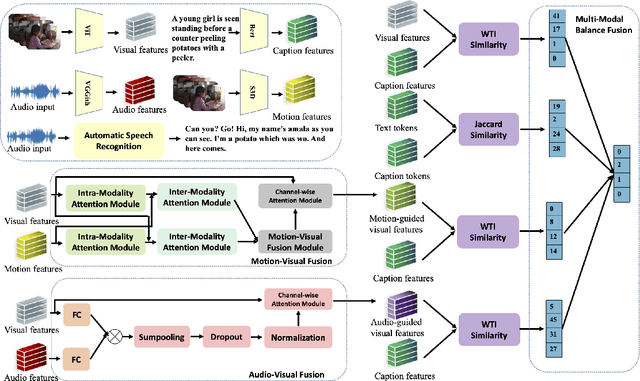
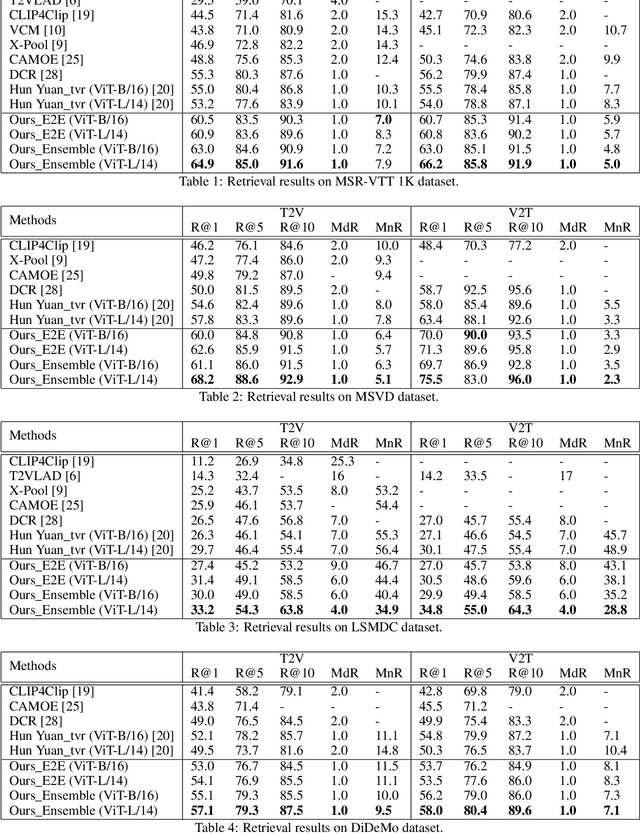


Videos contain multi-modal content, and exploring multi-level cross-modal interactions with natural language queries can provide great prominence to text-video retrieval task (TVR). However, new trending methods applying large-scale pre-trained model CLIP for TVR do not focus on multi-modal cues in videos. Furthermore, the traditional methods simply concatenating multi-modal features do not exploit fine-grained cross-modal information in videos. In this paper, we propose a multi-level multi-modal hybrid fusion (M2HF) network to explore comprehensive interactions between text queries and each modality content in videos. Specifically, M2HF first utilizes visual features extracted by CLIP to early fuse with audio and motion features extracted from videos, obtaining audio-visual fusion features and motion-visual fusion features respectively. Multi-modal alignment problem is also considered in this process. Then, visual features, audio-visual fusion features, motion-visual fusion features, and texts extracted from videos establish cross-modal relationships with caption queries in a multi-level way. Finally, the retrieval outputs from all levels are late fused to obtain final text-video retrieval results. Our framework provides two kinds of training strategies, including an ensemble manner and an end-to-end manner. Moreover, a novel multi-modal balance loss function is proposed to balance the contributions of each modality for efficient end-to-end training. M2HF allows us to obtain state-of-the-art results on various benchmarks, eg, Rank@1 of 64.9\%, 68.2\%, 33.2\%, 57.1\%, 57.8\% on MSR-VTT, MSVD, LSMDC, DiDeMo, and ActivityNet, respectively.