 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFACE: A Face-based Autoregressive Representation for High-Fidelity and Efficient Mesh Generation
Mar 03, 2026Autoregressive models for 3D mesh generation suffer from a fundamental limitation: they flatten meshes into long vertex-coordinate sequences. This results in prohibitive computational costs, hindering the efficient synthesis of high-fidelity geometry. We argue this bottleneck stems from operating at the wrong semantic level. We introduce FACE, a novel Autoregressive Autoencoder (ARAE) framework that reconceptualizes the task by generating meshes at the face level. Our one-face-one-token strategy treats each triangle face, the fundamental building block of a mesh, as a single, unified token. This simple yet powerful design reduces the sequence length by a factor of nine, leading to an unprecedented compression ratio of 0.11, halving the previous state-of-the-art. This dramatic efficiency gain does not compromise quality; by pairing our face-level decoder with a powerful VecSet encoder, FACE achieves state-of-the-art reconstruction quality on standard benchmarks. The versatility of the learned latent space is further demonstrated by training a latent diffusion model that achieves high-fidelity, single-image-to-mesh generation. FACE provides a simple, scalable, and powerful paradigm that lowers the barrier to high-quality structured 3D content creation.
iFlame: Interleaving Full and Linear Attention for Efficient Mesh Generation
Mar 20, 2025This paper propose iFlame, a novel transformer-based network architecture for mesh generation. While attention-based models have demonstrated remarkable performance in mesh generation, their quadratic computational complexity limits scalability, particularly for high-resolution 3D data. Conversely, linear attention mechanisms offer lower computational costs but often struggle to capture long-range dependencies, resulting in suboptimal outcomes. To address this trade-off, we propose an interleaving autoregressive mesh generation framework that combines the efficiency of linear attention with the expressive power of full attention mechanisms. To further enhance efficiency and leverage the inherent structure of mesh representations, we integrate this interleaving approach into an hourglass architecture, which significantly boosts efficiency. Our approach reduces training time while achieving performance comparable to pure attention-based models. To improve inference efficiency, we implemented a caching algorithm that almost doubles the speed and reduces the KV cache size by seven-eighths compared to the original Transformer. We evaluate our framework on ShapeNet and Objaverse, demonstrating its ability to generate high-quality 3D meshes efficiently. Our results indicate that the proposed interleaving framework effectively balances computational efficiency and generative performance, making it a practical solution for mesh generation. The training takes only 2 days with 4 GPUs on 39k data with a maximum of 4k faces on Objaverse.
Revisiting CAD Model Generation by Learning Raster Sketch
Mar 02, 2025The integration of deep generative networks into generating Computer-Aided Design (CAD) models has garnered increasing attention over recent years. Traditional methods often rely on discrete sequences of parametric line/curve segments to represent sketches. Differently, we introduce RECAD, a novel framework that generates Raster sketches and 3D Extrusions for CAD models. Representing sketches as raster images offers several advantages over discrete sequences: 1) it breaks the limitations on the types and numbers of lines/curves, providing enhanced geometric representation capabilities; 2) it enables interpolation within a continuous latent space; and 3) it allows for more intuitive user control over the output. Technically, RECAD employs two diffusion networks: the first network generates extrusion boxes conditioned on the number and types of extrusions, while the second network produces sketch images conditioned on these extrusion boxes. By combining these two networks, RECAD effectively generates sketch-and-extrude CAD models, offering a more robust and intuitive approach to CAD model generation. Experimental results indicate that RECAD achieves strong performance in unconditional generation, while also demonstrating effectiveness in conditional generation and output editing.
GoHD: Gaze-oriented and Highly Disentangled Portrait Animation with Rhythmic Poses and Realistic Expression
Dec 13, 2024



Audio-driven talking head generation necessitates seamless integration of audio and visual data amidst the challenges posed by diverse input portraits and intricate correlations between audio and facial motions. In response, we propose a robust framework GoHD designed to produce highly realistic, expressive, and controllable portrait videos from any reference identity with any motion. GoHD innovates with three key modules: Firstly, an animation module utilizing latent navigation is introduced to improve the generalization ability across unseen input styles. This module achieves high disentanglement of motion and identity, and it also incorporates gaze orientation to rectify unnatural eye movements that were previously overlooked. Secondly, a conformer-structured conditional diffusion model is designed to guarantee head poses that are aware of prosody. Thirdly, to estimate lip-synchronized and realistic expressions from the input audio within limited training data, a two-stage training strategy is devised to decouple frequent and frame-wise lip motion distillation from the generation of other more temporally dependent but less audio-related motions, e.g., blinks and frowns. Extensive experiments validate GoHD's advanced generalization capabilities, demonstrating its effectiveness in generating realistic talking face results on arbitrary subjects.
OCMG-Net: Neural Oriented Normal Refinement for Unstructured Point Clouds
Sep 02, 2024We present a robust refinement method for estimating oriented normals from unstructured point clouds. In contrast to previous approaches that either suffer from high computational complexity or fail to achieve desirable accuracy, our novel framework incorporates sign orientation and data augmentation in the feature space to refine the initial oriented normals, striking a balance between efficiency and accuracy. To address the issue of noise-caused direction inconsistency existing in previous approaches, we introduce a new metric called the Chamfer Normal Distance, which faithfully minimizes the estimation error by correcting the annotated normal with the closest point found on the potentially clean point cloud. This metric not only tackles the challenge but also aids in network training and significantly enhances network robustness against noise. Moreover, we propose an innovative dual-parallel architecture that integrates Multi-scale Local Feature Aggregation and Hierarchical Geometric Information Fusion, which enables the network to capture intricate geometric details more effectively and notably reduces ambiguity in scale selection. Extensive experiments demonstrate the superiority and versatility of our method in both unoriented and oriented normal estimation tasks across synthetic and real-world datasets among indoor and outdoor scenarios. The code is available at https://github.com/YingruiWoo/OCMG-Net.git.
Correspondence-Free Non-Rigid Point Set Registration Using Unsupervised Clustering Analysis
Jun 27, 2024This paper presents a novel non-rigid point set registration method that is inspired by unsupervised clustering analysis. Unlike previous approaches that treat the source and target point sets as separate entities, we develop a holistic framework where they are formulated as clustering centroids and clustering members, separately. We then adopt Tikhonov regularization with an $\ell_1$-induced Laplacian kernel instead of the commonly used Gaussian kernel to ensure smooth and more robust displacement fields. Our formulation delivers closed-form solutions, theoretical guarantees, independence from dimensions, and the ability to handle large deformations. Subsequently, we introduce a clustering-improved Nystr\"om method to effectively reduce the computational complexity and storage of the Gram matrix to linear, while providing a rigorous bound for the low-rank approximation. Our method achieves high accuracy results across various scenarios and surpasses competitors by a significant margin, particularly on shapes with substantial deformations. Additionally, we demonstrate the versatility of our method in challenging tasks such as shape transfer and medical registration.
TCAN: Text-oriented Cross Attention Network for Multimodal Sentiment Analysis
Apr 06, 2024



Multimodal Sentiment Analysis (MSA) endeavors to understand human sentiment by leveraging language, visual, and acoustic modalities. Despite the remarkable performance exhibited by previous MSA approaches, the presence of inherent multimodal heterogeneities poses a challenge, with the contribution of different modalities varying considerably. Past research predominantly focused on improving representation learning techniques and feature fusion strategies. However, many of these efforts overlooked the variation in semantic richness among different modalities, treating each modality uniformly. This approach may lead to underestimating the significance of strong modalities while overemphasizing the importance of weak ones. Motivated by these insights, we introduce a Text-oriented Cross-Attention Network (TCAN), emphasizing the predominant role of the text modality in MSA. Specifically, for each multimodal sample, by taking unaligned sequences of the three modalities as inputs, we initially allocate the extracted unimodal features into a visual-text and an acoustic-text pair. Subsequently, we implement self-attention on the text modality and apply text-queried cross-attention to the visual and acoustic modalities. To mitigate the influence of noise signals and redundant features, we incorporate a gated control mechanism into the framework. Additionally, we introduce unimodal joint learning to gain a deeper understanding of homogeneous emotional tendencies across diverse modalities through backpropagation. Experimental results demonstrate that TCAN consistently outperforms state-of-the-art MSA methods on two datasets (CMU-MOSI and CMU-MOSEI).
Deep Learning-based Image and Video Inpainting: A Survey
Jan 07, 2024Image and video inpainting is a classic problem in computer vision and computer graphics, aiming to fill in the plausible and realistic content in the missing areas of images and videos. With the advance of deep learning, this problem has achieved significant progress recently. The goal of this paper is to comprehensively review the deep learning-based methods for image and video inpainting. Specifically, we sort existing methods into different categories from the perspective of their high-level inpainting pipeline, present different deep learning architectures, including CNN, VAE, GAN, diffusion models, etc., and summarize techniques for module design. We review the training objectives and the common benchmark datasets. We present evaluation metrics for low-level pixel and high-level perceptional similarity, conduct a performance evaluation, and discuss the strengths and weaknesses of representative inpainting methods. We also discuss related real-world applications. Finally, we discuss open challenges and suggest potential future research directions.
CMG-Net: Robust Normal Estimation for Point Clouds via Chamfer Normal Distance and Multi-scale Geometry
Dec 14, 2023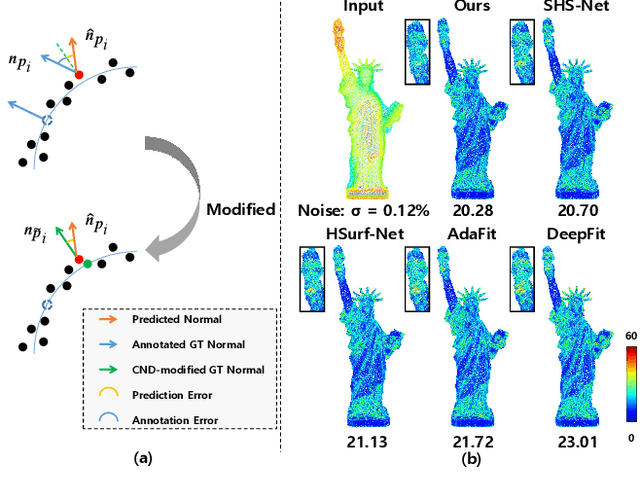
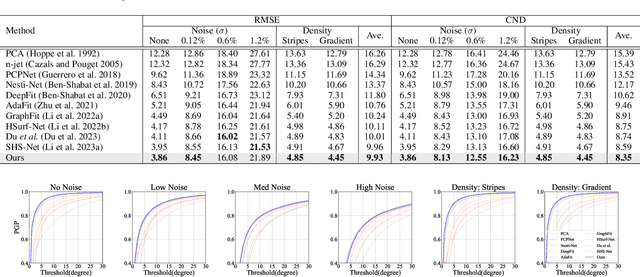
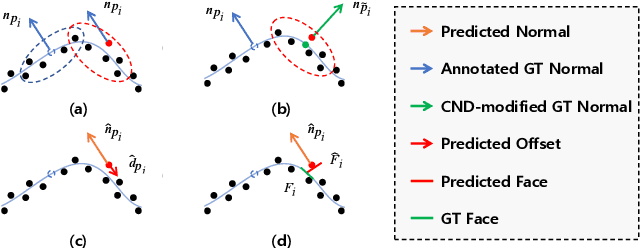
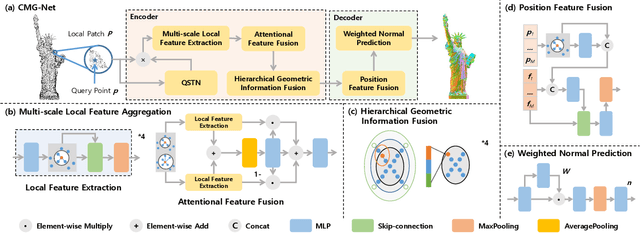
This work presents an accurate and robust method for estimating normals from point clouds. In contrast to predecessor approaches that minimize the deviations between the annotated and the predicted normals directly, leading to direction inconsistency, we first propose a new metric termed Chamfer Normal Distance to address this issue. This not only mitigates the challenge but also facilitates network training and substantially enhances the network robustness against noise. Subsequently, we devise an innovative architecture that encompasses Multi-scale Local Feature Aggregation and Hierarchical Geometric Information Fusion. This design empowers the network to capture intricate geometric details more effectively and alleviate the ambiguity in scale selection. Extensive experiments demonstrate that our method achieves the state-of-the-art performance on both synthetic and real-world datasets, particularly in scenarios contaminated by noise. Our implementation is available at https://github.com/YingruiWoo/CMG-Net_Pytorch.
M2HF: Multi-level Multi-modal Hybrid Fusion for Text-Video Retrieval
Aug 16, 2022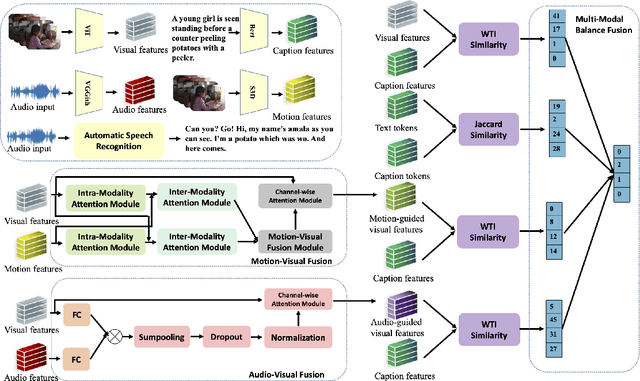
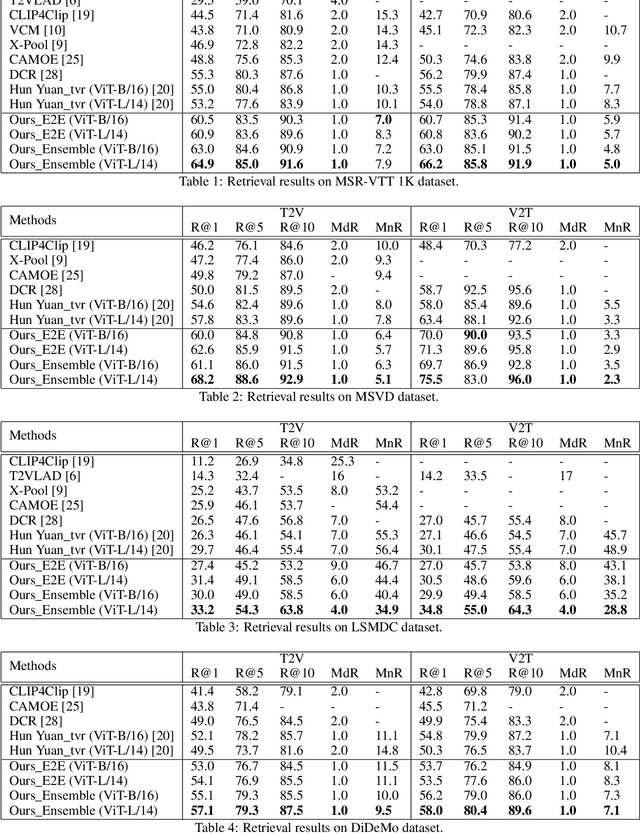


Videos contain multi-modal content, and exploring multi-level cross-modal interactions with natural language queries can provide great prominence to text-video retrieval task (TVR). However, new trending methods applying large-scale pre-trained model CLIP for TVR do not focus on multi-modal cues in videos. Furthermore, the traditional methods simply concatenating multi-modal features do not exploit fine-grained cross-modal information in videos. In this paper, we propose a multi-level multi-modal hybrid fusion (M2HF) network to explore comprehensive interactions between text queries and each modality content in videos. Specifically, M2HF first utilizes visual features extracted by CLIP to early fuse with audio and motion features extracted from videos, obtaining audio-visual fusion features and motion-visual fusion features respectively. Multi-modal alignment problem is also considered in this process. Then, visual features, audio-visual fusion features, motion-visual fusion features, and texts extracted from videos establish cross-modal relationships with caption queries in a multi-level way. Finally, the retrieval outputs from all levels are late fused to obtain final text-video retrieval results. Our framework provides two kinds of training strategies, including an ensemble manner and an end-to-end manner. Moreover, a novel multi-modal balance loss function is proposed to balance the contributions of each modality for efficient end-to-end training. M2HF allows us to obtain state-of-the-art results on various benchmarks, eg, Rank@1 of 64.9\%, 68.2\%, 33.2\%, 57.1\%, 57.8\% on MSR-VTT, MSVD, LSMDC, DiDeMo, and ActivityNet, respectively.