 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Feedback Regulated Opto-Mechanical Soft Robotic Actuators
Dec 20, 2024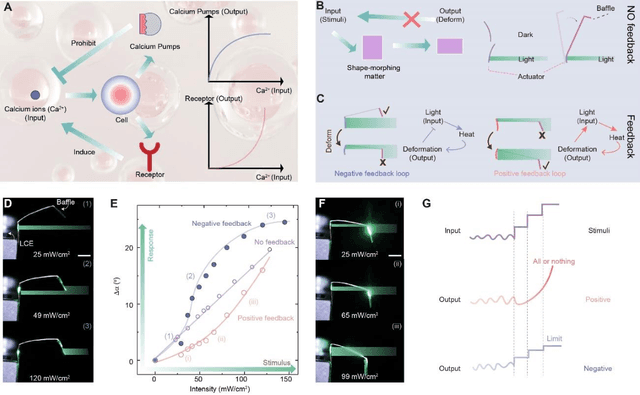
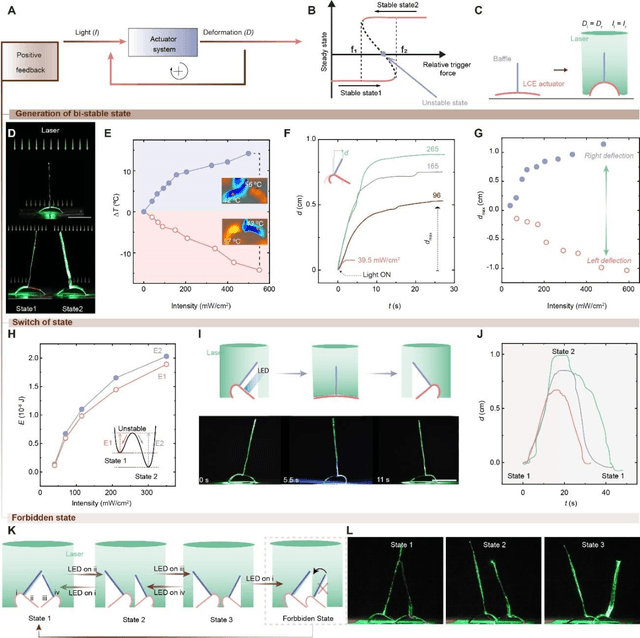
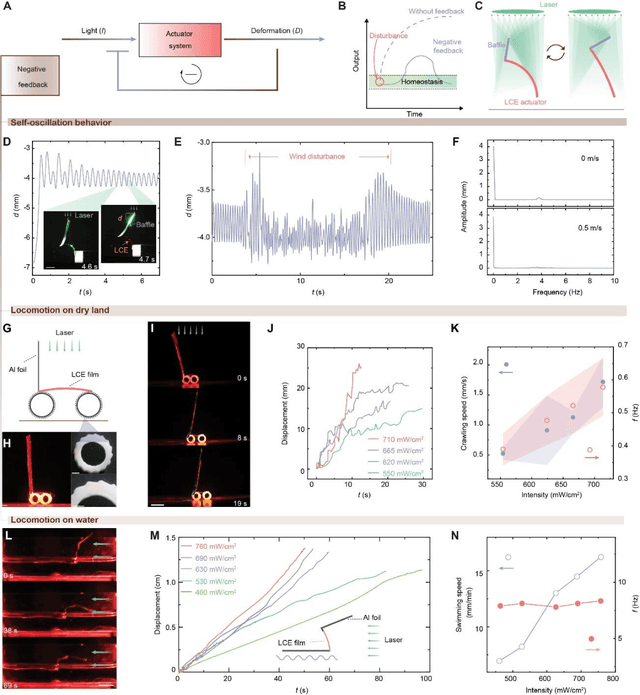
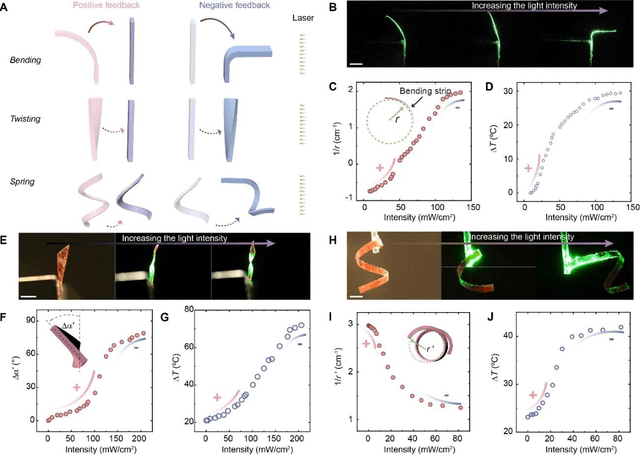
Natural organisms can convert environmental stimuli into sensory feedback to regulate their body and realize active adaptivity. However, realizing such a feedback-regulation mechanism in synthetic material systems remains a grand challenge. It is believed that achieving complex feedback mechanisms in responsive materials will pave the way toward autonomous, intelligent structure and actuation without complex electronics. Inspired by living systems, we report a general principle to design and construct such feedback loops in light-responsive materials. Specifically, we design a baffle-actuator mechanism to incorporate programmed feedback into the opto-mechanical responsiveness. By simply addressing the baffle position with respect to the incident light beam, positive and negative feedback are programmed. We demonstrate the transformation of a light-bending strip into a switcher, where the intensity of light determines the energy barrier under positive feedback, realizing multi-stable shape-morphing. By leveraging the negative feedback and associated homeostasis, we demonstrate two soft robots, i.e., a locomotor and a swimmer. Furthermore, we unveil the ubiquity of feedback in light-responsive materials, which provides new insight into self-regulated robotic matters.
CMG-Net: Robust Normal Estimation for Point Clouds via Chamfer Normal Distance and Multi-scale Geometry
Dec 14, 2023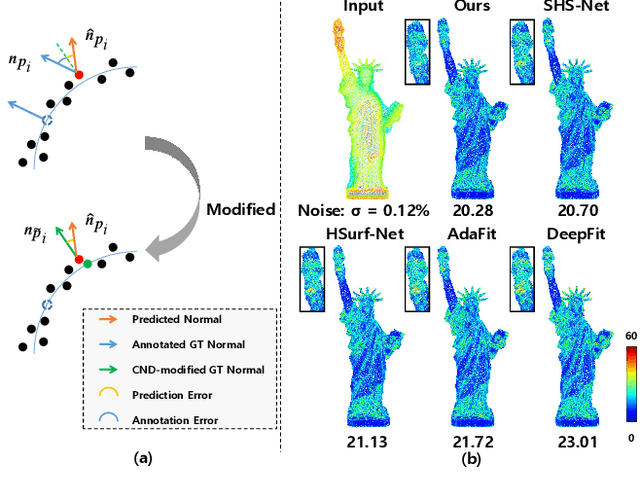
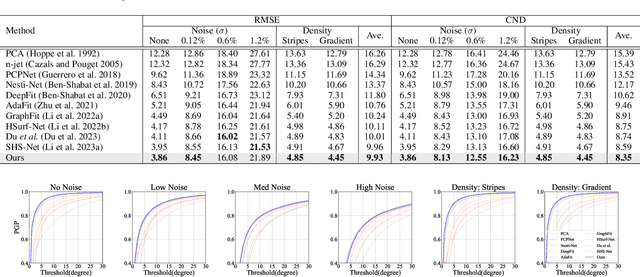
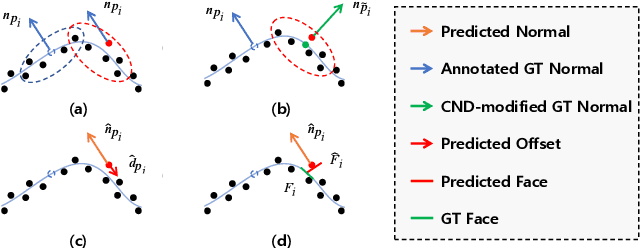
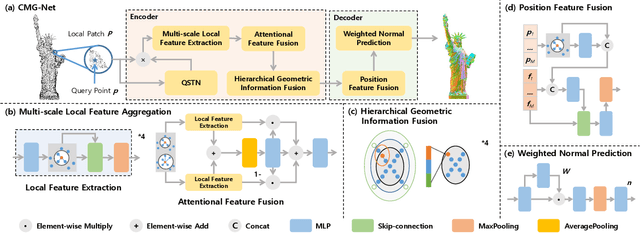
This work presents an accurate and robust method for estimating normals from point clouds. In contrast to predecessor approaches that minimize the deviations between the annotated and the predicted normals directly, leading to direction inconsistency, we first propose a new metric termed Chamfer Normal Distance to address this issue. This not only mitigates the challenge but also facilitates network training and substantially enhances the network robustness against noise. Subsequently, we devise an innovative architecture that encompasses Multi-scale Local Feature Aggregation and Hierarchical Geometric Information Fusion. This design empowers the network to capture intricate geometric details more effectively and alleviate the ambiguity in scale selection. Extensive experiments demonstrate that our method achieves the state-of-the-art performance on both synthetic and real-world datasets, particularly in scenarios contaminated by noise. Our implementation is available at https://github.com/YingruiWoo/CMG-Net_Pytorch.