 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Optimizable to Interactable: Mixed Digital Twin-Empowered Testing of Vehicle-Infrastructure Cooperation Systems
Mar 19, 2026Sufficient testing under corner cases is critical for the long-term operation of vehicle-infrastructure cooperation systems (VICS). However, existing corner-case generation methods are primarily AI-driven, and VICS testing under corner cases is typically limited to simulation. In this paper, we introduce an L5 ''Interactable'' level to the VICS digital twin (VICS-DT) taxonomy, extending beyond the conventional L4 ''Optimizable'' level. We further propose an L5-level VICS testing framework, IMPACT (Interactive Mixed-digital-twin Paradigm for Advanced Cooperative vehicle-infrastructure Testing). By enabling direct human interactions with VICS entities, IMPACT incorporates highly uncertain and unpredictable human behaviors into the testing loop, naturally generating high-quality corner cases that complement AI-based methods. Furthermore, the mixedDT-enabled ''Physical-Virtual Action Interaction'' facilitates safe VICS testing under corner cases, incorporating real-world environments and entities rather than purely in simulation. Finally, we implement IMPACT on the I-VIT (Interactive Vehicle-Infrastructure Testbed), and experiments demonstrate its effectiveness. The experimental videos are available at our project website: https://dongjh20.github.io/IMPACT.
Multi-Source Human-in-the-Loop Digital Twin Testbed for Connected and Autonomous Vehicles in Mixed Traffic Flow
Mar 18, 2026In the emerging mixed traffic environments, Connected and Autonomous Vehicles (CAVs) have to interact with surrounding human-driven vehicles (HDVs). This paper introduces MSH-MCCT (Multi-Source Human-in-the-Loop Mixed Cloud Control Testbed), a novel CAV testbed that captures complex interactions between various CAVs and HDVs. Utilizing the Mixed Digital Twin concept, which combines Mixed Reality with Digital Twin, MSH-MCCT integrates physical, virtual, and mixed platforms, along with multi-source control inputs. Bridged by the mixed platform, MSH-MCCT allows human drivers and CAV algorithms to operate both physical and virtual vehicles within multiple fields of view. Particularly, this testbed facilitates the coexistence and real-time interaction of physical and virtual CAVs \& HDVs, significantly enhancing the experimental flexibility and scalability. Experiments on vehicle platooning in mixed traffic showcase the potential of MSH-MCCT to conduct CAV testing with multi-source real human drivers in the loop through driving simulators of diverse fidelity. The videos for the experiments are available at our project website: https://dongjh20.github.io/MSH-MCCT.
STAPO: Stabilizing Reinforcement Learning for LLMs by Silencing Rare Spurious Tokens
Feb 17, 2026Reinforcement Learning (RL) has significantly improved large language model reasoning, but existing RL fine-tuning methods rely heavily on heuristic techniques such as entropy regularization and reweighting to maintain stability. In practice, they often experience late-stage performance collapse, leading to degraded reasoning quality and unstable training. We derive that the magnitude of token-wise policy gradients in RL is negatively correlated with token probability and local policy entropy. Building on this result, we prove that training instability is driven by a tiny fraction of tokens, approximately 0.01\%, which we term \emph{spurious tokens}. When such tokens appear in correct responses, they contribute little to the reasoning outcome but inherit the full sequence-level reward, leading to abnormally amplified gradient updates. Motivated by this observation, we propose Spurious-Token-Aware Policy Optimization (STAPO) for large-scale model refining, which selectively masks such updates and renormalizes the loss over valid tokens. Across six mathematical reasoning benchmarks using Qwen 1.7B, 8B, and 14B base models, STAPO consistently demonstrates superior entropy stability and achieves an average performance improvement of 7.13\% over GRPO, 20-Entropy and JustRL.
LL-GaussianMap: Zero-shot Low-Light Image Enhancement via 2D Gaussian Splatting Guided Gain Maps
Jan 27, 2026Significant progress has been made in low-light image enhancement with respect to visual quality. However, most existing methods primarily operate in the pixel domain or rely on implicit feature representations. As a result, the intrinsic geometric structural priors of images are often neglected. 2D Gaussian Splatting (2DGS) has emerged as a prominent explicit scene representation technique characterized by superior structural fitting capabilities and high rendering efficiency. Despite these advantages, the utilization of 2DGS in low-level vision tasks remains unexplored. To bridge this gap, LL-GaussianMap is proposed as the first unsupervised framework incorporating 2DGS into low-light image enhancement. Distinct from conventional methodologies, the enhancement task is formulated as a gain map generation process guided by 2DGS primitives. The proposed method comprises two primary stages. First, high-fidelity structural reconstruction is executed utilizing 2DGS. Then, data-driven enhancement dictionary coefficients are rendered via the rasterization mechanism of Gaussian splatting through an innovative unified enhancement module. This design effectively incorporates the structural perception capabilities of 2DGS into gain map generation, thereby preserving edges and suppressing artifacts during enhancement. Additionally, the reliance on paired data is circumvented through unsupervised learning. Experimental results demonstrate that LL-GaussianMap achieves superior enhancement performance with an extremely low storage footprint, highlighting the effectiveness of explicit Gaussian representations for image enhancement.
LL-GaussianImage: Efficient Image Representation for Zero-shot Low-Light Enhancement with 2D Gaussian Splatting
Jan 22, 20262D Gaussian Splatting (2DGS) is an emerging explicit scene representation method with significant potential for image compression due to high fidelity and high compression ratios. However, existing low-light enhancement algorithms operate predominantly within the pixel domain. Processing 2DGS-compressed images necessitates a cumbersome decompression-enhancement-recompression pipeline, which compromises efficiency and introduces secondary degradation. To address these limitations, we propose LL-GaussianImage, the first zero-shot unsupervised framework designed for low-light enhancement directly within the 2DGS compressed representation domain. Three primary advantages are offered by this framework. First, a semantic-guided Mixture-of-Experts enhancement framework is designed. Dynamic adaptive transformations are applied to the sparse attribute space of 2DGS using rendered images as guidance to enable compression-as-enhancement without full decompression to a pixel grid. Second, a multi-objective collaborative loss function system is established to strictly constrain smoothness and fidelity during enhancement, suppressing artifacts while improving visual quality. Third, a two-stage optimization process is utilized to achieve reconstruction-as-enhancement. The accuracy of the base representation is ensured through single-scale reconstruction and network robustness is enhanced. High-quality enhancement of low-light images is achieved while high compression ratios are maintained. The feasibility and superiority of the paradigm for direct processing within the compressed representation domain are validated through experimental results.
Hierarchical Feature-level Reverse Propagation for Post-Training Neural Networks
Jun 08, 2025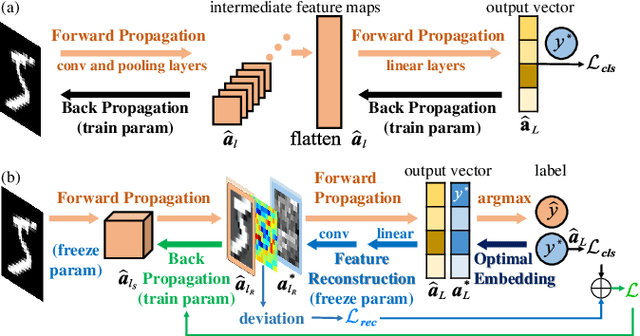



End-to-end autonomous driving has emerged as a dominant paradigm, yet its highly entangled black-box models pose significant challenges in terms of interpretability and safety assurance. To improve model transparency and training flexibility, this paper proposes a hierarchical and decoupled post-training framework tailored for pretrained neural networks. By reconstructing intermediate feature maps from ground-truth labels, surrogate supervisory signals are introduced at transitional layers to enable independent training of specific components, thereby avoiding the complexity and coupling of conventional end-to-end backpropagation and providing interpretable insights into networks' internal mechanisms. To the best of our knowledge, this is the first method to formalize feature-level reverse computation as well-posed optimization problems, which we rigorously reformulate as systems of linear equations or least squares problems. This establishes a novel and efficient training paradigm that extends gradient backpropagation to feature backpropagation. Extensive experiments on multiple standard image classification benchmarks demonstrate that the proposed method achieves superior generalization performance and computational efficiency compared to traditional training approaches, validating its effectiveness and potential.
Towards Human-Like Trajectory Prediction for Autonomous Driving: A Behavior-Centric Approach
May 27, 2025



Predicting the trajectories of vehicles is crucial for the development of autonomous driving (AD) systems, particularly in complex and dynamic traffic environments. In this study, we introduce HiT (Human-like Trajectory Prediction), a novel model designed to enhance trajectory prediction by incorporating behavior-aware modules and dynamic centrality measures. Unlike traditional methods that primarily rely on static graph structures, HiT leverages a dynamic framework that accounts for both direct and indirect interactions among traffic participants. This allows the model to capture the subtle yet significant influences of surrounding vehicles, enabling more accurate and human-like predictions. To evaluate HiT's performance, we conducted extensive experiments using diverse and challenging real-world datasets, including NGSIM, HighD, RounD, ApolloScape, and MoCAD++. The results demonstrate that HiT consistently outperforms other top models across multiple metrics, particularly excelling in scenarios involving aggressive driving behaviors. This research presents a significant step forward in trajectory prediction, offering a more reliable and interpretable approach for enhancing the safety and efficiency of fully autonomous driving systems.
Conformal Symplectic Optimization for Stable Reinforcement Learning
Dec 03, 2024



Training deep reinforcement learning (RL) agents necessitates overcoming the highly unstable nonconvex stochastic optimization inherent in the trial-and-error mechanism. To tackle this challenge, we propose a physics-inspired optimization algorithm called relativistic adaptive gradient descent (RAD), which enhances long-term training stability. By conceptualizing neural network (NN) training as the evolution of a conformal Hamiltonian system, we present a universal framework for transferring long-term stability from conformal symplectic integrators to iterative NN updating rules, where the choice of kinetic energy governs the dynamical properties of resulting optimization algorithms. By utilizing relativistic kinetic energy, RAD incorporates principles from special relativity and limits parameter updates below a finite speed, effectively mitigating abnormal gradient influences. Additionally, RAD models NN optimization as the evolution of a multi-particle system where each trainable parameter acts as an independent particle with an individual adaptive learning rate. We prove RAD's sublinear convergence under general nonconvex settings, where smaller gradient variance and larger batch sizes contribute to tighter convergence. Notably, RAD degrades to the well-known adaptive moment estimation (ADAM) algorithm when its speed coefficient is chosen as one and symplectic factor as a small positive value. Experimental results show RAD outperforming nine baseline optimizers with five RL algorithms across twelve environments, including standard benchmarks and challenging scenarios. Notably, RAD achieves up to a 155.1% performance improvement over ADAM in Atari games, showcasing its efficacy in stabilizing and accelerating RL training.
Hierarchical End-to-End Autonomous Driving: Integrating BEV Perception with Deep Reinforcement Learning
Sep 26, 2024End-to-end autonomous driving offers a streamlined alternative to the traditional modular pipeline, integrating perception, prediction, and planning within a single framework. While Deep Reinforcement Learning (DRL) has recently gained traction in this domain, existing approaches often overlook the critical connection between feature extraction of DRL and perception. In this paper, we bridge this gap by mapping the DRL feature extraction network directly to the perception phase, enabling clearer interpretation through semantic segmentation. By leveraging Bird's-Eye-View (BEV) representations, we propose a novel DRL-based end-to-end driving framework that utilizes multi-sensor inputs to construct a unified three-dimensional understanding of the environment. This BEV-based system extracts and translates critical environmental features into high-level abstract states for DRL, facilitating more informed control. Extensive experimental evaluations demonstrate that our approach not only enhances interpretability but also significantly outperforms state-of-the-art methods in autonomous driving control tasks, reducing the collision rate by 20%.
Unveiling the Black Box: Independent Functional Module Evaluation for Bird's-Eye-View Perception Model
Sep 18, 2024End-to-end models are emerging as the mainstream in autonomous driving perception. However, the inability to meticulously deconstruct their internal mechanisms results in diminished development efficacy and impedes the establishment of trust. Pioneering in the issue, we present the Independent Functional Module Evaluation for Bird's-Eye-View Perception Model (BEV-IFME), a novel framework that juxtaposes the module's feature maps against Ground Truth within a unified semantic Representation Space to quantify their similarity, thereby assessing the training maturity of individual functional modules. The core of the framework lies in the process of feature map encoding and representation aligning, facilitated by our proposed two-stage Alignment AutoEncoder, which ensures the preservation of salient information and the consistency of feature structure. The metric for evaluating the training maturity of functional modules, Similarity Score, demonstrates a robust positive correlation with BEV metrics, with an average correlation coefficient of 0.9387, attesting to the framework's reliability for assessment purposes.