 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest of Both Worlds: Multimodal Reasoning and Generation via Unified Discrete Flow Matching
Feb 12, 2026We propose UniDFlow, a unified discrete flow-matching framework for multimodal understanding, generation, and editing. It decouples understanding and generation via task-specific low-rank adapters, avoiding objective interference and representation entanglement, while a novel reference-based multimodal preference alignment optimizes relative outcomes under identical conditioning, improving faithfulness and controllability without large-scale retraining. UniDFlpw achieves SOTA performance across eight benchmarks and exhibits strong zero-shot generalization to tasks including inpainting, in-context image generation, reference-based editing, and compositional generation, despite no explicit task-specific training.
Predict and Resist: Long-Term Accident Anticipation under Sensor Noise
Nov 10, 2025Accident anticipation is essential for proactive and safe autonomous driving, where even a brief advance warning can enable critical evasive actions. However, two key challenges hinder real-world deployment: (1) noisy or degraded sensory inputs from weather, motion blur, or hardware limitations, and (2) the need to issue timely yet reliable predictions that balance early alerts with false-alarm suppression. We propose a unified framework that integrates diffusion-based denoising with a time-aware actor-critic model to address these challenges. The diffusion module reconstructs noise-resilient image and object features through iterative refinement, preserving critical motion and interaction cues under sensor degradation. In parallel, the actor-critic architecture leverages long-horizon temporal reasoning and time-weighted rewards to determine the optimal moment to raise an alert, aligning early detection with reliability. Experiments on three benchmark datasets (DAD, CCD, A3D) demonstrate state-of-the-art accuracy and significant gains in mean time-to-accident, while maintaining robust performance under Gaussian and impulse noise. Qualitative analyses further show that our model produces earlier, more stable, and human-aligned predictions in both routine and highly complex traffic scenarios, highlighting its potential for real-world, safety-critical deployment.
Mental Health Impacts of AI Companions: Triangulating Social Media Quasi-Experiments, User Perspectives, and Relational Theory
Sep 26, 2025
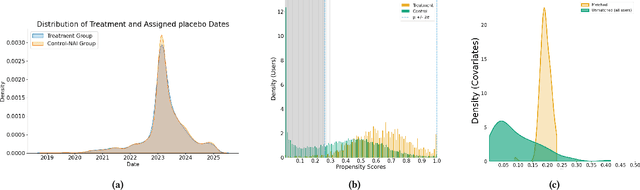
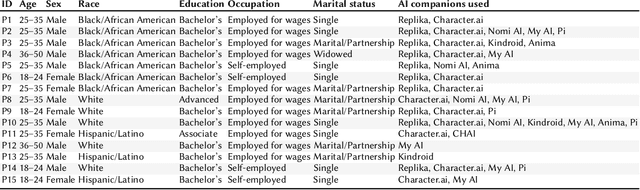
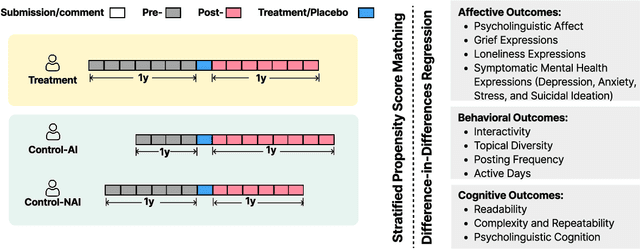
AI-powered companion chatbots (AICCs) such as Replika are increasingly popular, offering empathetic interactions, yet their psychosocial impacts remain unclear. We examined how engaging with AICCs shaped wellbeing and how users perceived these experiences. First, we conducted a large-scale quasi-experimental study of longitudinal Reddit data, applying stratified propensity score matching and Difference-in-Differences regression. Findings revealed mixed effects -- greater affective and grief expression, readability, and interpersonal focus, alongside increases in language about loneliness and suicidal ideation. Second, we complemented these results with 15 semi-structured interviews, which we thematically analyzed and contextualized using Knapp's relationship development model. We identified trajectories of initiation, escalation, and bonding, wherein AICCs provided emotional validation and social rehearsal but also carried risks of over-reliance and withdrawal. Triangulating across methods, we offer design implications for AI companions that scaffold healthy boundaries, support mindful engagement, support disclosure without dependency, and surface relationship stages -- maximizing psychosocial benefits while mitigating risks.
AMD: Adaptive Momentum and Decoupled Contrastive Learning Framework for Robust Long-Tail Trajectory Prediction
Jul 02, 2025Accurately predicting the future trajectories of traffic agents is essential in autonomous driving. However, due to the inherent imbalance in trajectory distributions, tail data in natural datasets often represents more complex and hazardous scenarios. Existing studies typically rely solely on a base model's prediction error, without considering the diversity and uncertainty of long-tail trajectory patterns. We propose an adaptive momentum and decoupled contrastive learning framework (AMD), which integrates unsupervised and supervised contrastive learning strategies. By leveraging an improved momentum contrast learning (MoCo-DT) and decoupled contrastive learning (DCL) module, our framework enhances the model's ability to recognize rare and complex trajectories. Additionally, we design four types of trajectory random augmentation methods and introduce an online iterative clustering strategy, allowing the model to dynamically update pseudo-labels and better adapt to the distributional shifts in long-tail data. We propose three different criteria to define long-tail trajectories and conduct extensive comparative experiments on the nuScenes and ETH$/$UCY datasets. The results show that AMD not only achieves optimal performance in long-tail trajectory prediction but also demonstrates outstanding overall prediction accuracy.
SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents
May 29, 2025Recent advancements in large language model (LLM) agents have significantly accelerated scientific discovery automation, yet concurrently raised critical ethical and safety concerns. To systematically address these challenges, we introduce \textbf{SafeScientist}, an innovative AI scientist framework explicitly designed to enhance safety and ethical responsibility in AI-driven scientific exploration. SafeScientist proactively refuses ethically inappropriate or high-risk tasks and rigorously emphasizes safety throughout the research process. To achieve comprehensive safety oversight, we integrate multiple defensive mechanisms, including prompt monitoring, agent-collaboration monitoring, tool-use monitoring, and an ethical reviewer component. Complementing SafeScientist, we propose \textbf{SciSafetyBench}, a novel benchmark specifically designed to evaluate AI safety in scientific contexts, comprising 240 high-risk scientific tasks across 6 domains, alongside 30 specially designed scientific tools and 120 tool-related risk tasks. Extensive experiments demonstrate that SafeScientist significantly improves safety performance by 35\% compared to traditional AI scientist frameworks, without compromising scientific output quality. Additionally, we rigorously validate the robustness of our safety pipeline against diverse adversarial attack methods, further confirming the effectiveness of our integrated approach. The code and data will be available at https://github.com/ulab-uiuc/SafeScientist. \textcolor{red}{Warning: this paper contains example data that may be offensive or harmful.}
Beyond Patterns: Harnessing Causal Logic for Autonomous Driving Trajectory Prediction
May 11, 2025Accurate trajectory prediction has long been a major challenge for autonomous driving (AD). Traditional data-driven models predominantly rely on statistical correlations, often overlooking the causal relationships that govern traffic behavior. In this paper, we introduce a novel trajectory prediction framework that leverages causal inference to enhance predictive robustness, generalization, and accuracy. By decomposing the environment into spatial and temporal components, our approach identifies and mitigates spurious correlations, uncovering genuine causal relationships. We also employ a progressive fusion strategy to integrate multimodal information, simulating human-like reasoning processes and enabling real-time inference. Evaluations on five real-world datasets--ApolloScape, nuScenes, NGSIM, HighD, and MoCAD--demonstrate our model's superiority over existing state-of-the-art (SOTA) methods, with improvements in key metrics such as RMSE and FDE. Our findings highlight the potential of causal reasoning to transform trajectory prediction, paving the way for robust AD systems.
Advancing Medical Radiograph Representation Learning: A Hybrid Pre-training Paradigm with Multilevel Semantic Granularity
Oct 01, 2024

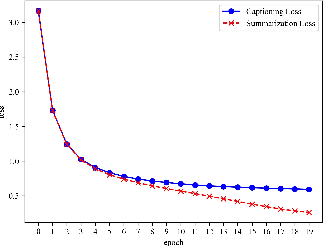

This paper introduces an innovative approach to Medical Vision-Language Pre-training (Med-VLP) area in the specialized context of radiograph representation learning. While conventional methods frequently merge textual annotations into unified reports, we acknowledge the intrinsic hierarchical relationship between the findings and impression section in radiograph datasets. To establish a targeted correspondence between images and texts, we propose a novel HybridMED framework to align global-level visual representations with impression and token-level visual representations with findings. Moreover, our framework incorporates a generation decoder that employs two proxy tasks, responsible for generating the impression from (1) images, via a captioning branch, and (2) findings, through a summarization branch. Additionally, knowledge distillation is leveraged to facilitate the training process. Experiments on the MIMIC-CXR dataset reveal that our summarization branch effectively distills knowledge to the captioning branch, enhancing model performance without significantly increasing parameter requirements due to the shared self-attention and feed-forward architecture.
* 18 pages
GS-Net: Generalizable Plug-and-Play 3D Gaussian Splatting Module
Sep 17, 2024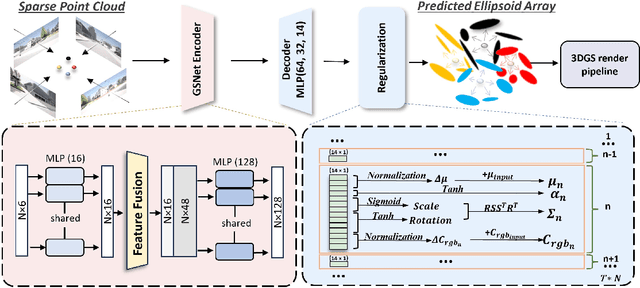

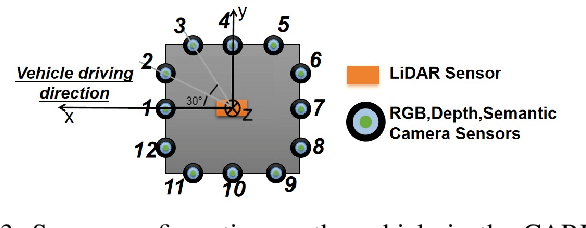

3D Gaussian Splatting (3DGS) integrates the strengths of primitive-based representations and volumetric rendering techniques, enabling real-time, high-quality rendering. However, 3DGS models typically overfit to single-scene training and are highly sensitive to the initialization of Gaussian ellipsoids, heuristically derived from Structure from Motion (SfM) point clouds, which limits both generalization and practicality. To address these limitations, we propose GS-Net, a generalizable, plug-and-play 3DGS module that densifies Gaussian ellipsoids from sparse SfM point clouds, enhancing geometric structure representation. To the best of our knowledge, GS-Net is the first plug-and-play 3DGS module with cross-scene generalization capabilities. Additionally, we introduce the CARLA-NVS dataset, which incorporates additional camera viewpoints to thoroughly evaluate reconstruction and rendering quality. Extensive experiments demonstrate that applying GS-Net to 3DGS yields a PSNR improvement of 2.08 dB for conventional viewpoints and 1.86 dB for novel viewpoints, confirming the method's effectiveness and robustness.