 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFed-Signal: An ADR Prediction Model based on Federated Learning
Dec 29, 2025The adverse drug reactions (ADRs) predicted based on the biased records in FAERS (U.S. Food and Drug Administration Adverse Event Reporting System) may mislead diagnosis online. Generally, such problems are solved by optimizing reporting odds ratio (ROR) or proportional reporting ratio (PRR). However, these methods that rely on statistical methods cannot eliminate the biased data, leading to inaccurate signal prediction. In this paper, we propose PFed-signal, a federated learning-based signal prediction model of ADR, which utilizes the Euclidean distance to eliminate the biased data from FAERS, thereby improving the accuracy of ADR prediction. Specifically, we first propose Pfed-Split, a method to split the original dataset into a split dataset based on ADR. Then we propose ADR-signal, an ADR prediction model, including a biased data identification method based on federated learning and an ADR prediction model based on Transformer. The former identifies the biased data according to the Euclidean distance and generates a clean dataset by deleting the biased data. The latter is an ADR prediction model based on Transformer trained on the clean data set. The results show that the ROR and PRR on the clean dataset are better than those of the traditional methods. Furthermore, the accuracy rate, F1 score, recall rate and AUC of PFed-Signal are 0.887, 0.890, 0.913 and 0.957 respectively, which are higher than the baselines.
UrbanGraph: Physics-Informed Spatio-Temporal Dynamic Heterogeneous Graphs for Urban Microclimate Prediction
Oct 01, 2025With rapid urbanization, predicting urban microclimates has become critical, as it affects building energy demand and public health risks. However, existing generative and homogeneous graph approaches fall short in capturing physical consistency, spatial dependencies, and temporal variability. To address this, we introduce UrbanGraph, a physics-informed framework integrating heterogeneous and dynamic spatio-temporal graphs. It encodes key physical processes -- vegetation evapotranspiration, shading, and convective diffusion -- while modeling complex spatial dependencies among diverse urban entities and their temporal evolution. We evaluate UrbanGraph on UMC4/12, a physics-based simulation dataset covering diverse urban configurations and climates. Results show that UrbanGraph improves $R^2$ by up to 10.8% and reduces FLOPs by 17.0% over all baselines, with heterogeneous and dynamic graphs contributing 3.5% and 7.1% gains. Our dataset provides the first high-resolution benchmark for spatio-temporal microclimate modeling, and our method extends to broader urban heterogeneous dynamic computing tasks.
Spiking Vocos: An Energy-Efficient Neural Vocoder
Sep 16, 2025Despite the remarkable progress in the synthesis speed and fidelity of neural vocoders, their high energy consumption remains a critical barrier to practical deployment on computationally restricted edge devices. Spiking Neural Networks (SNNs), widely recognized for their high energy efficiency due to their event-driven nature, offer a promising solution for low-resource scenarios. In this paper, we propose Spiking Vocos, a novel spiking neural vocoder with ultra-low energy consumption, built upon the efficient Vocos framework. To mitigate the inherent information bottleneck in SNNs, we design a Spiking ConvNeXt module to reduce Multiply-Accumulate (MAC) operations and incorporate an amplitude shortcut path to preserve crucial signal dynamics. Furthermore, to bridge the performance gap with its Artificial Neural Network (ANN) counterpart, we introduce a self-architectural distillation strategy to effectively transfer knowledge. A lightweight Temporal Shift Module is also integrated to enhance the model's ability to fuse information across the temporal dimension with negligible computational overhead. Experiments demonstrate that our model achieves performance comparable to its ANN counterpart, with UTMOS and PESQ scores of 3.74 and 3.45 respectively, while consuming only 14.7% of the energy. The source code is available at https://github.com/pymaster17/Spiking-Vocos.
UrbanSense:AFramework for Quantitative Analysis of Urban Streetscapes leveraging Vision Large Language Models
Jun 12, 2025Urban cultures and architectural styles vary significantly across cities due to geographical, chronological, historical, and socio-political factors. Understanding these differences is essential for anticipating how cities may evolve in the future. As representative cases of historical continuity and modern innovation in China, Beijing and Shenzhen offer valuable perspectives for exploring the transformation of urban streetscapes. However, conventional approaches to urban cultural studies often rely on expert interpretation and historical documentation, which are difficult to standardize across different contexts. To address this, we propose a multimodal research framework based on vision-language models, enabling automated and scalable analysis of urban streetscape style differences. This approach enhances the objectivity and data-driven nature of urban form research. The contributions of this study are as follows: First, we construct UrbanDiffBench, a curated dataset of urban streetscapes containing architectural images from different periods and regions. Second, we develop UrbanSense, the first vision-language-model-based framework for urban streetscape analysis, enabling the quantitative generation and comparison of urban style representations. Third, experimental results show that Over 80% of generated descriptions pass the t-test (p less than 0.05). High Phi scores (0.912 for cities, 0.833 for periods) from subjective evaluations confirm the method's ability to capture subtle stylistic differences. These results highlight the method's potential to quantify and interpret urban style evolution, offering a scientifically grounded lens for future design.
FloorplanMAE:A self-supervised framework for complete floorplan generation from partial inputs
Jun 10, 2025In the architectural design process, floorplan design is often a dynamic and iterative process. Architects progressively draw various parts of the floorplan according to their ideas and requirements, continuously adjusting and refining throughout the design process. Therefore, the ability to predict a complete floorplan from a partial one holds significant value in the design process. Such prediction can help architects quickly generate preliminary designs, improve design efficiency, and reduce the workload associated with repeated modifications. To address this need, we propose FloorplanMAE, a self-supervised learning framework for restoring incomplete floor plans into complete ones. First, we developed a floor plan reconstruction dataset, FloorplanNet, specifically trained on architectural floor plans. Secondly, we propose a floor plan reconstruction method based on Masked Autoencoders (MAE), which reconstructs missing parts by masking sections of the floor plan and training a lightweight Vision Transformer (ViT). We evaluated the reconstruction accuracy of FloorplanMAE and compared it with state-of-the-art benchmarks. Additionally, we validated the model using real sketches from the early stages of architectural design. Experimental results show that the FloorplanMAE model can generate high-quality complete floor plans from incomplete partial plans. This framework provides a scalable solution for floor plan generation, with broad application prospects.
ArchiLense: A Framework for Quantitative Analysis of Architectural Styles Based on Vision Large Language Models
Jun 09, 2025Architectural cultures across regions are characterized by stylistic diversity, shaped by historical, social, and technological contexts in addition to geograph-ical conditions. Understanding architectural styles requires the ability to describe and analyze the stylistic features of different architects from various regions through visual observations of architectural imagery. However, traditional studies of architectural culture have largely relied on subjective expert interpretations and historical literature reviews, often suffering from regional biases and limited ex-planatory scope. To address these challenges, this study proposes three core contributions: (1) We construct a professional architectural style dataset named ArchDiffBench, which comprises 1,765 high-quality architectural images and their corresponding style annotations, collected from different regions and historical periods. (2) We propose ArchiLense, an analytical framework grounded in Vision-Language Models and constructed using the ArchDiffBench dataset. By integrating ad-vanced computer vision techniques, deep learning, and machine learning algo-rithms, ArchiLense enables automatic recognition, comparison, and precise classi-fication of architectural imagery, producing descriptive language outputs that ar-ticulate stylistic differences. (3) Extensive evaluations show that ArchiLense achieves strong performance in architectural style recognition, with a 92.4% con-sistency rate with expert annotations and 84.5% classification accuracy, effec-tively capturing stylistic distinctions across images. The proposed approach transcends the subjectivity inherent in traditional analyses and offers a more objective and accurate perspective for comparative studies of architectural culture.
Segment Any Architectural Facades (SAAF):An automatic segmentation model for building facades, walls and windows based on multimodal semantics guidance
Jun 09, 2025In the context of the digital development of architecture, the automatic segmentation of walls and windows is a key step in improving the efficiency of building information models and computer-aided design. This study proposes an automatic segmentation model for building facade walls and windows based on multimodal semantic guidance, called Segment Any Architectural Facades (SAAF). First, SAAF has a multimodal semantic collaborative feature extraction mechanism. By combining natural language processing technology, it can fuse the semantic information in text descriptions with image features, enhancing the semantic understanding of building facade components. Second, we developed an end-to-end training framework that enables the model to autonomously learn the mapping relationship from text descriptions to image segmentation, reducing the influence of manual intervention on the segmentation results and improving the automation and robustness of the model. Finally, we conducted extensive experiments on multiple facade datasets. The segmentation results of SAAF outperformed existing methods in the mIoU metric, indicating that the SAAF model can maintain high-precision segmentation ability when faced with diverse datasets. Our model has made certain progress in improving the accuracy and generalization ability of the wall and window segmentation task. It is expected to provide a reference for the development of architectural computer vision technology and also explore new ideas and technical paths for the application of multimodal learning in the architectural field.
CDFormer: Cross-Domain Few-Shot Object Detection Transformer Against Feature Confusion
May 02, 2025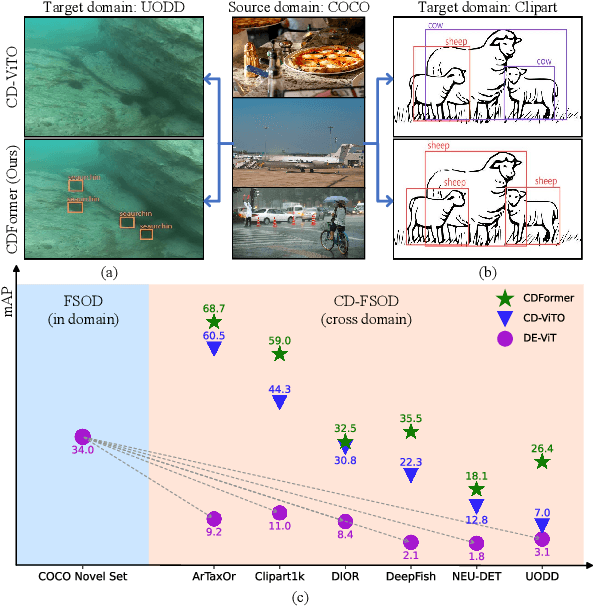
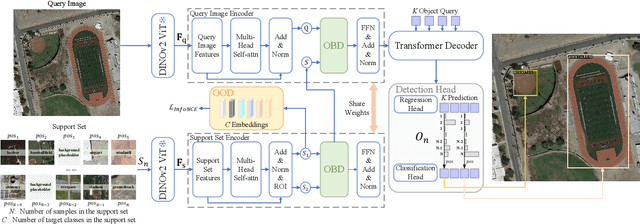

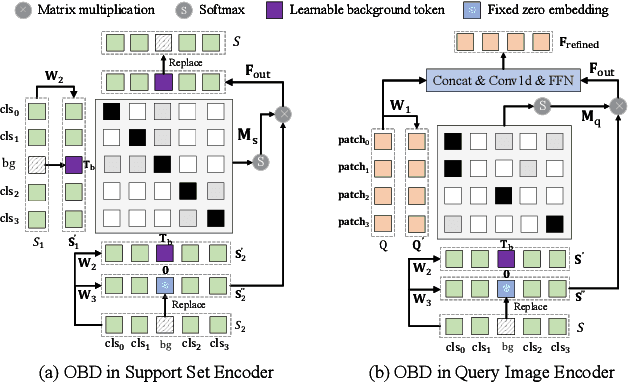
Cross-domain few-shot object detection (CD-FSOD) aims to detect novel objects across different domains with limited class instances. Feature confusion, including object-background confusion and object-object confusion, presents significant challenges in both cross-domain and few-shot settings. In this work, we introduce CDFormer, a cross-domain few-shot object detection transformer against feature confusion, to address these challenges. The method specifically tackles feature confusion through two key modules: object-background distinguishing (OBD) and object-object distinguishing (OOD). The OBD module leverages a learnable background token to differentiate between objects and background, while the OOD module enhances the distinction between objects of different classes. Experimental results demonstrate that CDFormer outperforms previous state-of-the-art approaches, achieving 12.9% mAP, 11.0% mAP, and 10.4% mAP improvements under the 1/5/10 shot settings, respectively, when fine-tuned.
GS-Net: Generalizable Plug-and-Play 3D Gaussian Splatting Module
Sep 17, 2024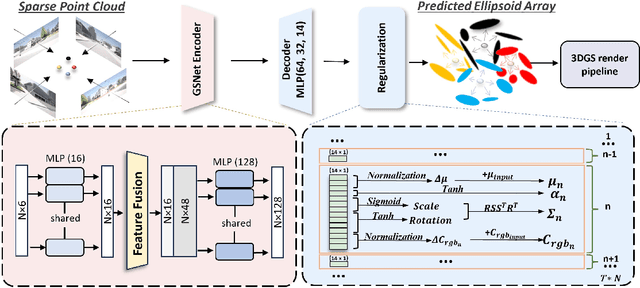

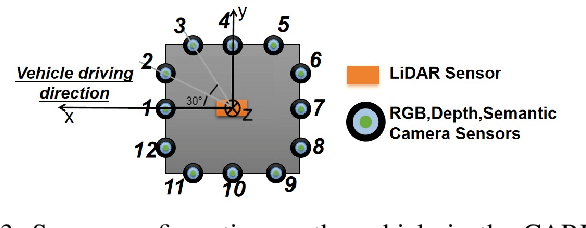

3D Gaussian Splatting (3DGS) integrates the strengths of primitive-based representations and volumetric rendering techniques, enabling real-time, high-quality rendering. However, 3DGS models typically overfit to single-scene training and are highly sensitive to the initialization of Gaussian ellipsoids, heuristically derived from Structure from Motion (SfM) point clouds, which limits both generalization and practicality. To address these limitations, we propose GS-Net, a generalizable, plug-and-play 3DGS module that densifies Gaussian ellipsoids from sparse SfM point clouds, enhancing geometric structure representation. To the best of our knowledge, GS-Net is the first plug-and-play 3DGS module with cross-scene generalization capabilities. Additionally, we introduce the CARLA-NVS dataset, which incorporates additional camera viewpoints to thoroughly evaluate reconstruction and rendering quality. Extensive experiments demonstrate that applying GS-Net to 3DGS yields a PSNR improvement of 2.08 dB for conventional viewpoints and 1.86 dB for novel viewpoints, confirming the method's effectiveness and robustness.
HPPNet: Modeling the Harmonic Structure and Pitch Invariance in Piano Transcription
Aug 31, 2022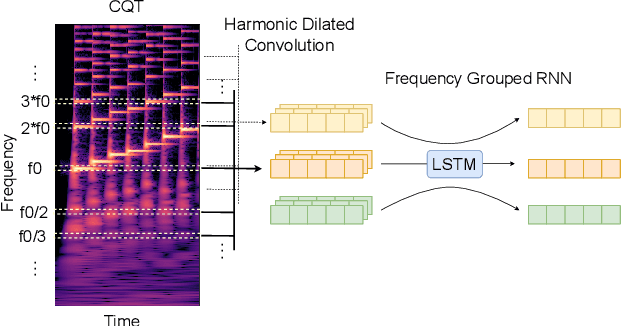
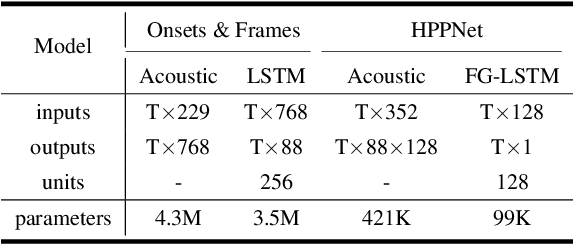
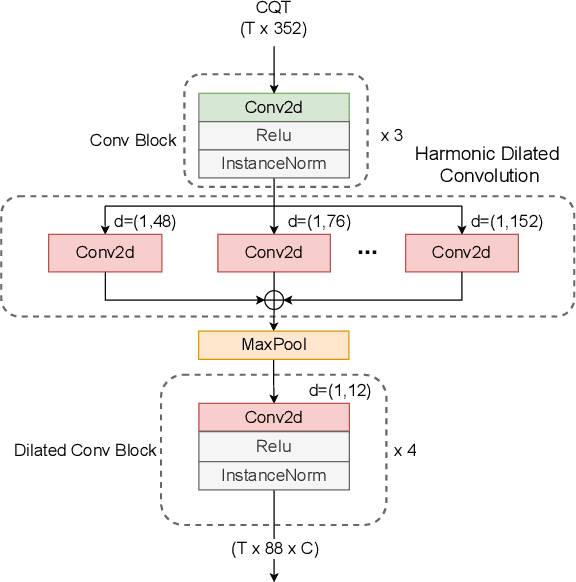
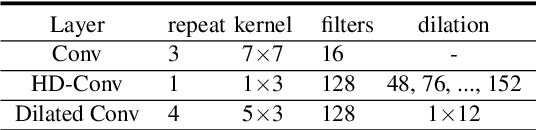
While neural network models are making significant progress in piano transcription, they are becoming more resource-consuming due to requiring larger model size and more computing power. In this paper, we attempt to apply more prior about piano to reduce model size and improve the transcription performance. The sound of a piano note contains various overtones, and the pitch of a key does not change over time. To make full use of such latent information, we propose HPPNet that using the Harmonic Dilated Convolution to capture the harmonic structures and the Frequency Grouped Recurrent Neural Network to model the pitch-invariance over time. Experimental results on the MAESTRO dataset show that our piano transcription system achieves state-of-the-art performance both in frame and note scores (frame F1 93.15%, note F1 97.18%). Moreover, the model size is much smaller than the previous state-of-the-art deep learning models.