 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Piano Transcription Based on Consistent Onset and Offset Decoding with Sustain Pedal Detection
Mar 03, 2025This paper describes a streaming audio-to-MIDI piano transcription approach that aims to sequentially translate a music signal into a sequence of note onset and offset events. The sequence-to-sequence nature of this task may call for the computationally-intensive transformer model for better performance, which has recently been used for offline transcription benchmarks and could be extended for streaming transcription with causal attention mechanisms. We assume that the performance limitation of this naive approach lies in the decoder. Although time-frequency features useful for onset detection are considerably different from those for offset detection, the single decoder is trained to output a mixed sequence of onset and offset events without guarantee of the correspondence between the onset and offset events of the same note. To overcome this limitation, we propose a streaming encoder-decoder model that uses a convolutional encoder aggregating local acoustic features, followed by an autoregressive Transformer decoder detecting a variable number of onset events and another decoder detecting the offset events for the active pitches with validation of the sustain pedal at each time frame. Experiments using the MAESTRO dataset showed that the proposed streaming method performed comparably with or even better than the state-of-the-art offline methods while significantly reducing the computational cost.
MERTech: Instrument Playing Technique Detection Using Self-Supervised Pretrained Model With Multi-Task Finetuning
Oct 15, 2023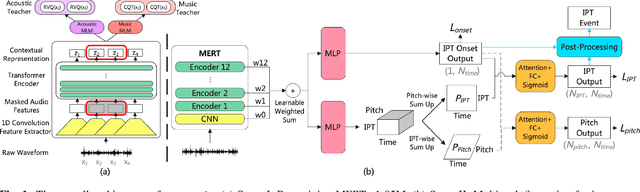
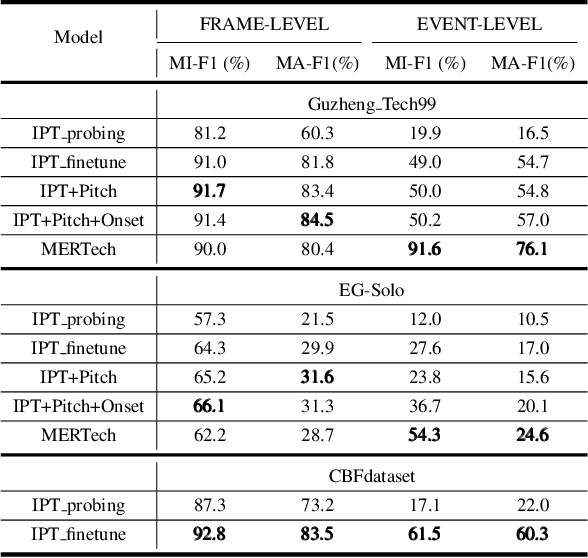
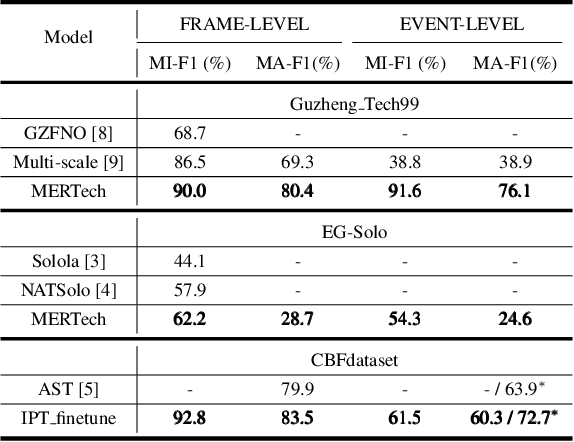
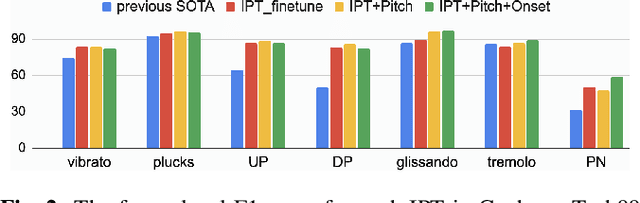
Instrument playing techniques (IPTs) constitute a pivotal component of musical expression. However, the development of automatic IPT detection methods suffers from limited labeled data and inherent class imbalance issues. In this paper, we propose to apply a self-supervised learning model pre-trained on large-scale unlabeled music data and finetune it on IPT detection tasks. This approach addresses data scarcity and class imbalance challenges. Recognizing the significance of pitch in capturing the nuances of IPTs and the importance of onset in locating IPT events, we investigate multi-task finetuning with pitch and onset detection as auxiliary tasks. Additionally, we apply a post-processing approach for event-level prediction, where an IPT activation initiates an event only if the onset output confirms an onset in that frame. Our method outperforms prior approaches in both frame-level and event-level metrics across multiple IPT benchmark datasets. Further experiments demonstrate the efficacy of multi-task finetuning on each IPT class.
HPPNet: Modeling the Harmonic Structure and Pitch Invariance in Piano Transcription
Aug 31, 2022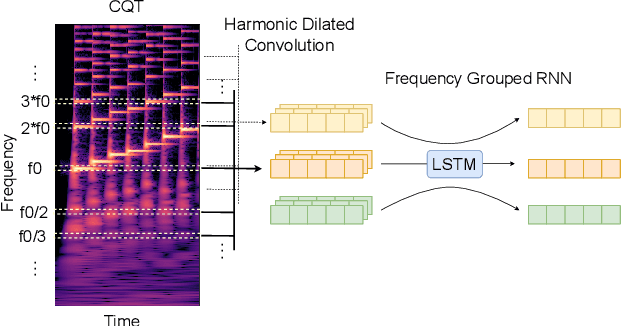
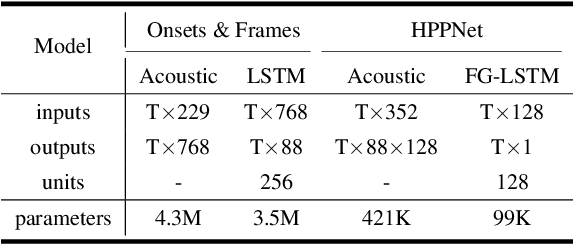
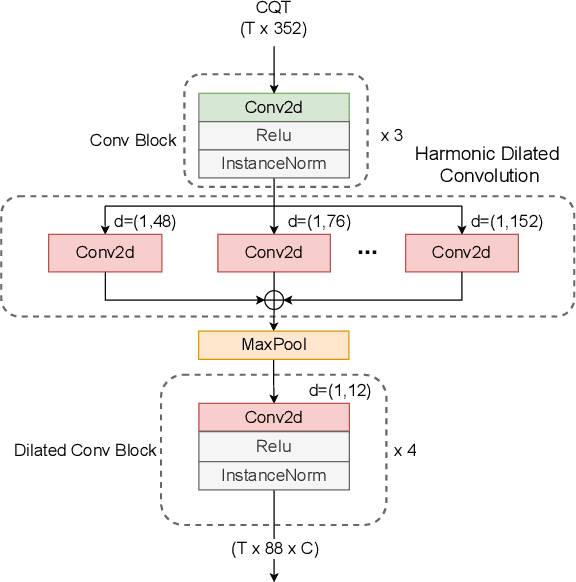
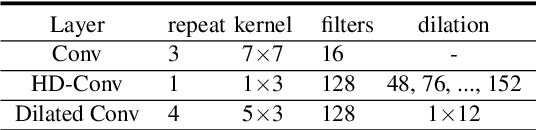
While neural network models are making significant progress in piano transcription, they are becoming more resource-consuming due to requiring larger model size and more computing power. In this paper, we attempt to apply more prior about piano to reduce model size and improve the transcription performance. The sound of a piano note contains various overtones, and the pitch of a key does not change over time. To make full use of such latent information, we propose HPPNet that using the Harmonic Dilated Convolution to capture the harmonic structures and the Frequency Grouped Recurrent Neural Network to model the pitch-invariance over time. Experimental results on the MAESTRO dataset show that our piano transcription system achieves state-of-the-art performance both in frame and note scores (frame F1 93.15%, note F1 97.18%). Moreover, the model size is much smaller than the previous state-of-the-art deep learning models.
HarmoF0: Logarithmic Scale Dilated Convolution For Pitch Estimation
May 02, 2022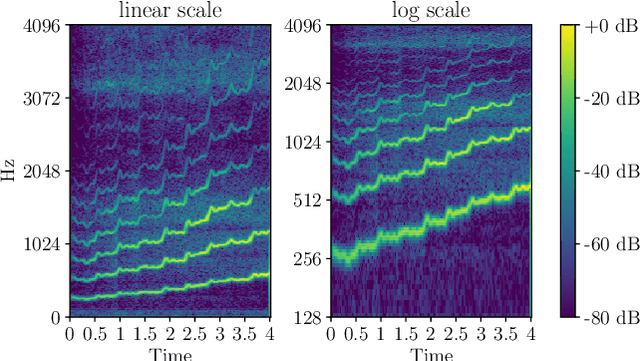
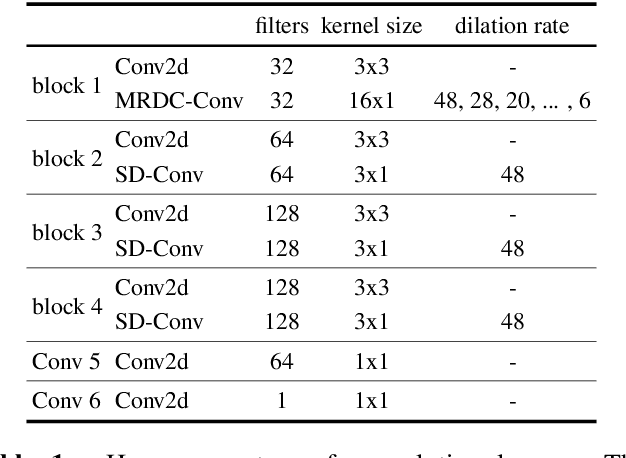
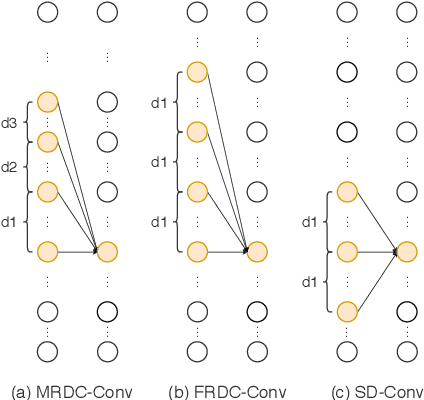
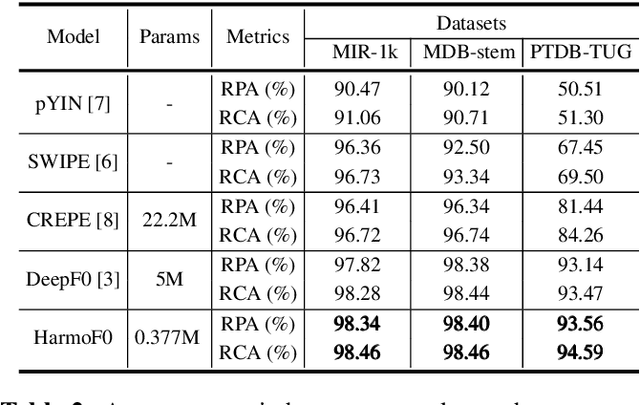
Sounds, especially music, contain various harmonic components scattered in the frequency dimension. It is difficult for normal convolutional neural networks to observe these overtones. This paper introduces a multiple rates dilated causal convolution (MRDC-Conv) method to capture the harmonic structure in logarithmic scale spectrograms efficiently. The harmonic is helpful for pitch estimation, which is important for many sound processing applications. We propose HarmoF0, a fully convolutional network, to evaluate the MRDC-Conv and other dilated convolutions in pitch estimation. The results show that this model outperforms the DeepF0, yields state-of-the-art performance in three datasets, and simultaneously reduces more than 90% parameters. We also find that it has stronger noise resistance and fewer octave errors.