 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Audio Prototyping: a prototype system for unified sound retrieval and procedural generation
May 30, 2026Sound design workflows frequently oscillate between time-consuming library searches and the complexity of procedural synthesis, with practitioners typically relying on disconnected tools to address each challenge separately. This paper introduces Quality Audio Prototyping (QuAP), a working prototype that unifies content-based audio retrieval and procedural sound generation within a single interface, reducing the procedural distance between a narrative concept and its sonic realisation. QuAP integrates a similarity-based retrieval engine with real-time procedural audio models, complemented by a rule-based assistant that provides perceptually informed parameter guidance, offering definitions and recommendations derived from empirical optimisation rather than requiring prior synthesis knowledge. Preliminary evaluation confirms the viability of this approach: subjective assessment demonstrated statistically significant quality improvements in five of six embedded synthesis models, and an encoder ablation study established the preferred retrieval architecture on a sound effect dataset. A user evaluation with 16 practitioners confirmed the tool's workflow utility, with all participants agreeing that the parameter assistant preserved creative agency while lowering the barrier to procedural interaction.
CMI-RewardBench: Evaluating Music Reward Models with Compositional Multimodal Instruction
Mar 04, 2026While music generation models have evolved to handle complex multimodal inputs mixing text, lyrics, and reference audio, evaluation mechanisms have lagged behind. In this paper, we bridge this critical gap by establishing a comprehensive ecosystem for music reward modeling under Compositional Multimodal Instruction (CMI), where the generated music may be conditioned on text descriptions, lyrics, and audio prompts. We first introduce CMI-Pref-Pseudo, a large-scale preference dataset comprising 110k pseudo-labeled samples, and CMI-Pref, a high-quality, human-annotated corpus tailored for fine-grained alignment tasks. To unify the evaluation landscape, we propose CMI-RewardBench, a unified benchmark that evaluates music reward models on heterogeneous samples across musicality, text-music alignment, and compositional instruction alignment. Leveraging these resources, we develop CMI reward models (CMI-RMs), a parameter-efficient reward model family capable of processing heterogeneous inputs. We evaluate their correlation with human judgments scores on musicality and alignment on CMI-Pref along with previous datasets. Further experiments demonstrate that CMI-RM not only correlates strongly with human judgments, but also enables effective inference-time scaling via top-k filtering. The necessary training data, benchmarks, and reward models are publicly available.
SCRAPL: Scattering Transform with Random Paths for Machine Learning
Feb 11, 2026The Euclidean distance between wavelet scattering transform coefficients (known as paths) provides informative gradients for perceptual quality assessment of deep inverse problems in computer vision, speech, and audio processing. However, these transforms are computationally expensive when employed as differentiable loss functions for stochastic gradient descent due to their numerous paths, which significantly limits their use in neural network training. Against this problem, we propose "Scattering transform with Random Paths for machine Learning" (SCRAPL): a stochastic optimization scheme for efficient evaluation of multivariable scattering transforms. We implement SCRAPL for the joint time-frequency scattering transform (JTFS) which demodulates spectrotemporal patterns at multiple scales and rates, allowing a fine characterization of intermittent auditory textures. We apply SCRAPL to differentiable digital signal processing (DDSP), specifically, unsupervised sound matching of a granular synthesizer and the Roland TR-808 drum machine. We also propose an initialization heuristic based on importance sampling, which adapts SCRAPL to the perceptual content of the dataset, improving neural network convergence and evaluation performance. We make our code and audio samples available and provide SCRAPL as a Python package.
AVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
AutoMV: An Automatic Multi-Agent System for Music Video Generation
Dec 13, 2025Music-to-Video (M2V) generation for full-length songs faces significant challenges. Existing methods produce short, disjointed clips, failing to align visuals with musical structure, beats, or lyrics, and lack temporal consistency. We propose AutoMV, a multi-agent system that generates full music videos (MVs) directly from a song. AutoMV first applies music processing tools to extract musical attributes, such as structure, vocal tracks, and time-aligned lyrics, and constructs these features as contextual inputs for following agents. The screenwriter Agent and director Agent then use this information to design short script, define character profiles in a shared external bank, and specify camera instructions. Subsequently, these agents call the image generator for keyframes and different video generators for "story" or "singer" scenes. A Verifier Agent evaluates their output, enabling multi-agent collaboration to produce a coherent longform MV. To evaluate M2V generation, we further propose a benchmark with four high-level categories (Music Content, Technical, Post-production, Art) and twelve ine-grained criteria. This benchmark was applied to compare commercial products, AutoMV, and human-directed MVs with expert human raters: AutoMV outperforms current baselines significantly across all four categories, narrowing the gap to professional MVs. Finally, we investigate using large multimodal models as automatic MV judges; while promising, they still lag behind human expert, highlighting room for future work.
Twenty-Five Years of MIR Research: Achievements, Practices, Evaluations, and Future Challenges
Nov 10, 2025In this paper, we trace the evolution of Music Information Retrieval (MIR) over the past 25 years. While MIR gathers all kinds of research related to music informatics, a large part of it focuses on signal processing techniques for music data, fostering a close relationship with the IEEE Audio and Acoustic Signal Processing Technical Commitee. In this paper, we reflect the main research achievements of MIR along the three EDICS related to music analysis, processing and generation. We then review a set of successful practices that fuel the rapid development of MIR research. One practice is the annual research benchmark, the Music Information Retrieval Evaluation eXchange, where participants compete on a set of research tasks. Another practice is the pursuit of reproducible and open research. The active engagement with industry research and products is another key factor for achieving large societal impacts and motivating younger generations of students to join the field. Last but not the least, the commitment to diversity, equity and inclusion ensures MIR to be a vibrant and open community where various ideas, methodologies, and career pathways collide. We finish by providing future challenges MIR will have to face.
RUMAA: Repeat-Aware Unified Music Audio Analysis for Score-Performance Alignment, Transcription, and Mistake Detection
Jul 16, 2025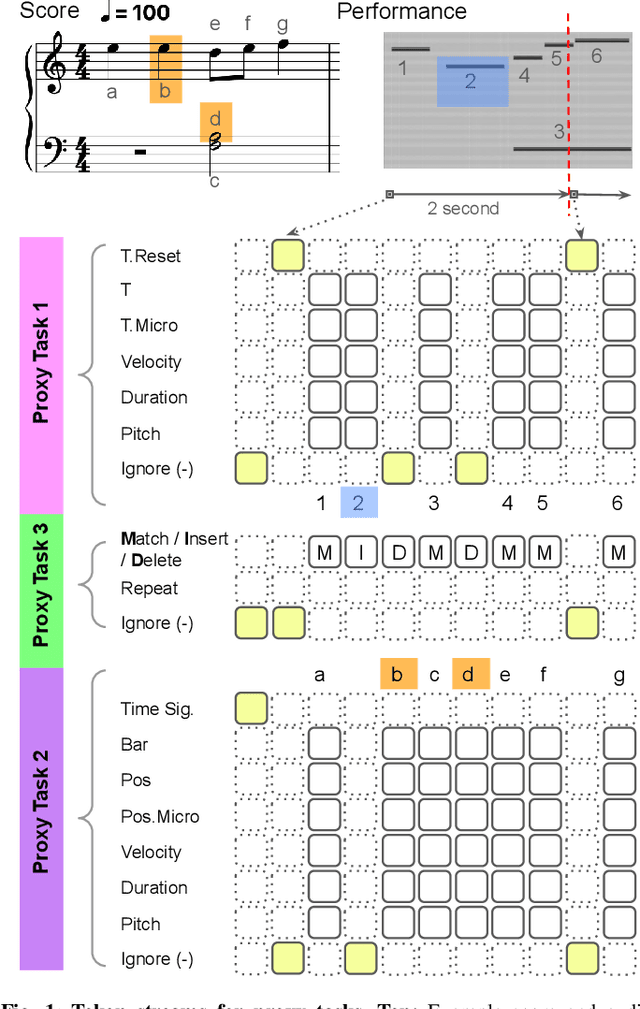



This study introduces RUMAA, a transformer-based framework for music performance analysis that unifies score-to-performance alignment, score-informed transcription, and mistake detection in a near end-to-end manner. Unlike prior methods addressing these tasks separately, RUMAA integrates them using pre-trained score and audio encoders and a novel tri-stream decoder capturing task interdependencies through proxy tasks. It aligns human-readable MusicXML scores with repeat symbols to full-length performance audio, overcoming traditional MIDI-based methods that rely on manually unfolded score-MIDI data with pre-specified repeat structures. RUMAA matches state-of-the-art alignment methods on non-repeated scores and outperforms them on scores with repeats in a public piano music dataset, while also delivering promising transcription and mistake detection results.
Refining music sample identification with a self-supervised graph neural network
Jun 17, 2025Automatic sample identification (ASID), the detection and identification of portions of audio recordings that have been reused in new musical works, is an essential but challenging task in the field of audio query-based retrieval. While a related task, audio fingerprinting, has made significant progress in accurately retrieving musical content under "real world" (noisy, reverberant) conditions, ASID systems struggle to identify samples that have undergone musical modifications. Thus, a system robust to common music production transformations such as time-stretching, pitch-shifting, effects processing, and underlying or overlaying music is an important open challenge. In this work, we propose a lightweight and scalable encoding architecture employing a Graph Neural Network within a contrastive learning framework. Our model uses only 9% of the trainable parameters compared to the current state-of-the-art system while achieving comparable performance, reaching a mean average precision (mAP) of 44.2%. To enhance retrieval quality, we introduce a two-stage approach consisting of an initial coarse similarity search for candidate selection, followed by a cross-attention classifier that rejects irrelevant matches and refines the ranking of retrieved candidates - an essential capability absent in prior models. In addition, because queries in real-world applications are often short in duration, we benchmark our system for short queries using new fine-grained annotations for the Sample100 dataset, which we publish as part of this work.
CMI-Bench: A Comprehensive Benchmark for Evaluating Music Instruction Following
Jun 14, 2025Recent advances in audio-text large language models (LLMs) have opened new possibilities for music understanding and generation. However, existing benchmarks are limited in scope, often relying on simplified tasks or multi-choice evaluations that fail to reflect the complexity of real-world music analysis. We reinterpret a broad range of traditional MIR annotations as instruction-following formats and introduce CMI-Bench, a comprehensive music instruction following benchmark designed to evaluate audio-text LLMs on a diverse set of music information retrieval (MIR) tasks. These include genre classification, emotion regression, emotion tagging, instrument classification, pitch estimation, key detection, lyrics transcription, melody extraction, vocal technique recognition, instrument performance technique detection, music tagging, music captioning, and (down)beat tracking: reflecting core challenges in MIR research. Unlike previous benchmarks, CMI-Bench adopts standardized evaluation metrics consistent with previous state-of-the-art MIR models, ensuring direct comparability with supervised approaches. We provide an evaluation toolkit supporting all open-source audio-textual LLMs, including LTU, Qwen-audio, SALMONN, MusiLingo, etc. Experiment results reveal significant performance gaps between LLMs and supervised models, along with their culture, chronological and gender bias, highlighting the potential and limitations of current models in addressing MIR tasks. CMI-Bench establishes a unified foundation for evaluating music instruction following, driving progress in music-aware LLMs.
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix
May 19, 2025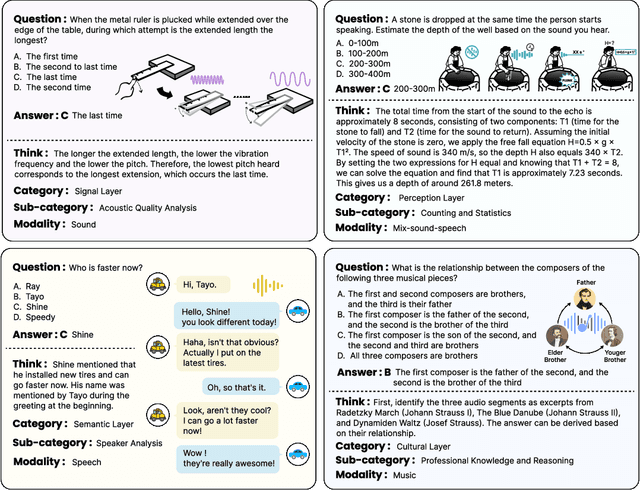

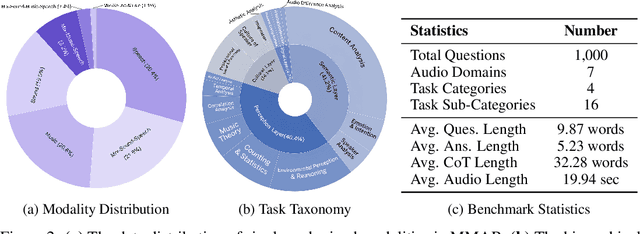
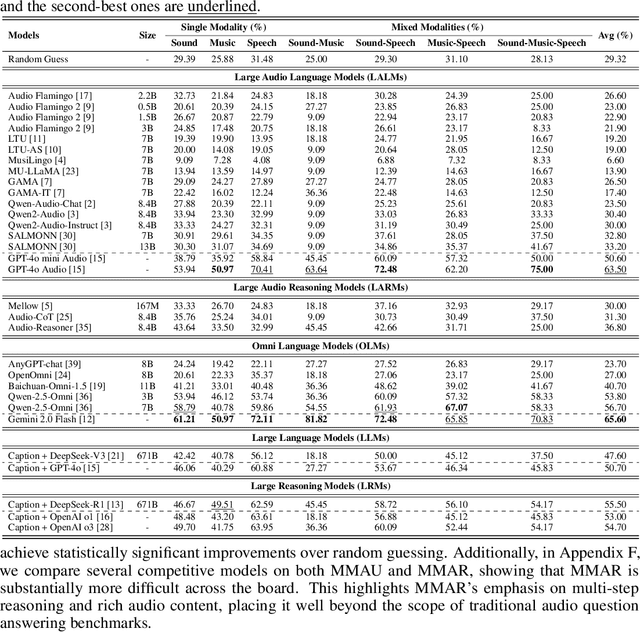
We introduce MMAR, a new benchmark designed to evaluate the deep reasoning capabilities of Audio-Language Models (ALMs) across massive multi-disciplinary tasks. MMAR comprises 1,000 meticulously curated audio-question-answer triplets, collected from real-world internet videos and refined through iterative error corrections and quality checks to ensure high quality. Unlike existing benchmarks that are limited to specific domains of sound, music, or speech, MMAR extends them to a broad spectrum of real-world audio scenarios, including mixed-modality combinations of sound, music, and speech. Each question in MMAR is hierarchically categorized across four reasoning layers: Signal, Perception, Semantic, and Cultural, with additional sub-categories within each layer to reflect task diversity and complexity. To further foster research in this area, we annotate every question with a Chain-of-Thought (CoT) rationale to promote future advancements in audio reasoning. Each item in the benchmark demands multi-step deep reasoning beyond surface-level understanding. Moreover, a part of the questions requires graduate-level perceptual and domain-specific knowledge, elevating the benchmark's difficulty and depth. We evaluate MMAR using a broad set of models, including Large Audio-Language Models (LALMs), Large Audio Reasoning Models (LARMs), Omni Language Models (OLMs), Large Language Models (LLMs), and Large Reasoning Models (LRMs), with audio caption inputs. The performance of these models on MMAR highlights the benchmark's challenging nature, and our analysis further reveals critical limitations of understanding and reasoning capabilities among current models. We hope MMAR will serve as a catalyst for future advances in this important but little-explored area.