 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of Spontaneous and Scripted Speech for Multilingual Audio
Dec 16, 2024



Distinguishing scripted from spontaneous speech is an essential tool for better understanding how speech styles influence speech processing research. It can also improve recommendation systems and discovery experiences for media users through better segmentation of large recorded speech catalogues. This paper addresses the challenge of building a classifier that generalises well across different formats and languages. We systematically evaluate models ranging from traditional, handcrafted acoustic and prosodic features to advanced audio transformers, utilising a large, multilingual proprietary podcast dataset for training and validation. We break down the performance of each model across 11 language groups to evaluate cross-lingual biases. Our experimental analysis extends to publicly available datasets to assess the models' generalisability to non-podcast domains. Our results indicate that transformer-based models consistently outperform traditional feature-based techniques, achieving state-of-the-art performance in distinguishing between scripted and spontaneous speech across various languages.
Link Me Baby One More Time: Social Music Discovery on Spotify
Jan 16, 2024



We explore the social and contextual factors that influence the outcome of person-to-person music recommendations and discovery. Specifically, we use data from Spotify to investigate how a link sent from one user to another results in the receiver engaging with the music of the shared artist. We consider several factors that may influence this process, such as the strength of the sender-receiver relationship, the user's role in the Spotify social network, their music social cohesion, and how similar the new artist is to the receiver's taste. We find that the receiver of a link is more likely to engage with a new artist when (1) they have similar music taste to the sender and the shared track is a good fit for their taste, (2) they have a stronger and more intimate tie with the sender, and (3) the shared artist is popular with the receiver's connections. Finally, we use these findings to build a Random Forest classifier to predict whether a shared music track will result in the receiver's engagement with the shared artist. This model elucidates which type of social and contextual features are most predictive, although peak performance is achieved when a diverse set of features are included. These findings provide new insights into the multifaceted mechanisms underpinning the interplay between music discovery and social processes.
Topological fingerprints for audio identification
Sep 07, 2023We present a topological audio fingerprinting approach for robustly identifying duplicate audio tracks. Our method applies persistent homology on local spectral decompositions of audio signals, using filtered cubical complexes computed from mel-spectrograms. By encoding the audio content in terms of local Betti curves, our topological audio fingerprints enable accurate detection of time-aligned audio matchings. Experimental results demonstrate the accuracy of our algorithm in the detection of tracks with the same audio content, even when subjected to various obfuscations. Our approach outperforms existing methods in scenarios involving topological distortions, such as time stretching and pitch shifting.
Thematic recommendations on knowledge graphs using multilayer networks
May 12, 2021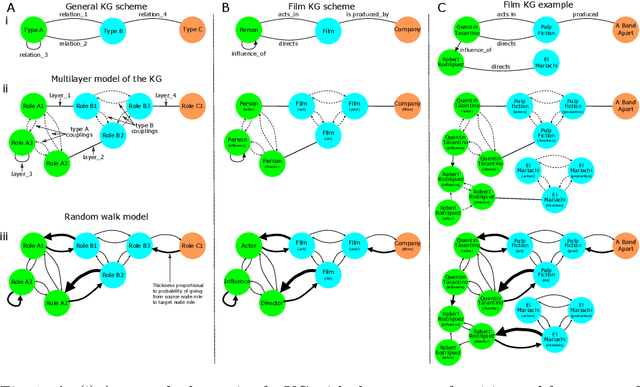
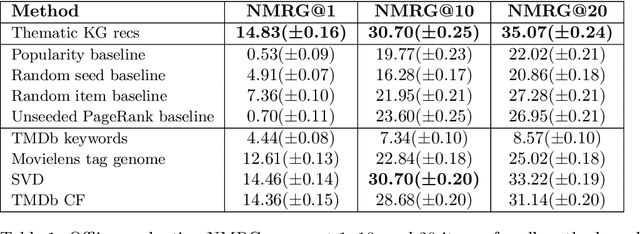
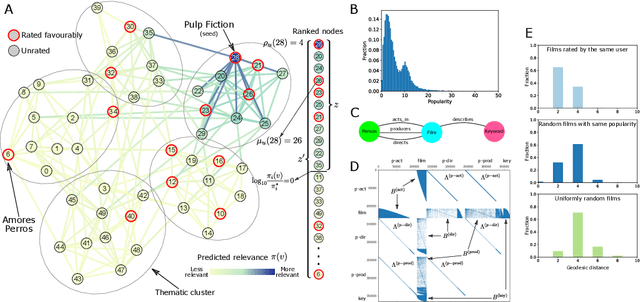

We present a framework to generate and evaluate thematic recommendations based on multilayer network representations of knowledge graphs (KGs). In this representation, each layer encodes a different type of relationship in the KG, and directed interlayer couplings connect the same entity in different roles. The relative importance of different types of connections is captured by an intuitive salience matrix that can be estimated from data, tuned to incorporate domain knowledge, address different use cases, or respect business logic. We apply an adaptation of the personalised PageRank algorithm to multilayer models of KGs to generate item-item recommendations. These recommendations reflect the knowledge we hold about the content and are suitable for thematic and/or cold-start recommendation settings. Evaluating thematic recommendations from user data presents unique challenges that we address by developing a method to evaluate recommendations relying on user-item ratings, yet respecting their thematic nature. We also show that the salience matrix can be estimated from user data. We demonstrate the utility of our methods by significantly improving consumption metrics in an AB test where collaborative filtering delivered subpar performance. We also apply our approach to movie recommendation using publicly-available data to ensure the reproducibility of our results. We demonstrate that our approach outperforms existing thematic recommendation methods and is even competitive with collaborative filtering approaches.
Tensor clustering with algebraic constraints gives interpretable groups of crosstalk mechanisms in breast cancer
Apr 28, 2017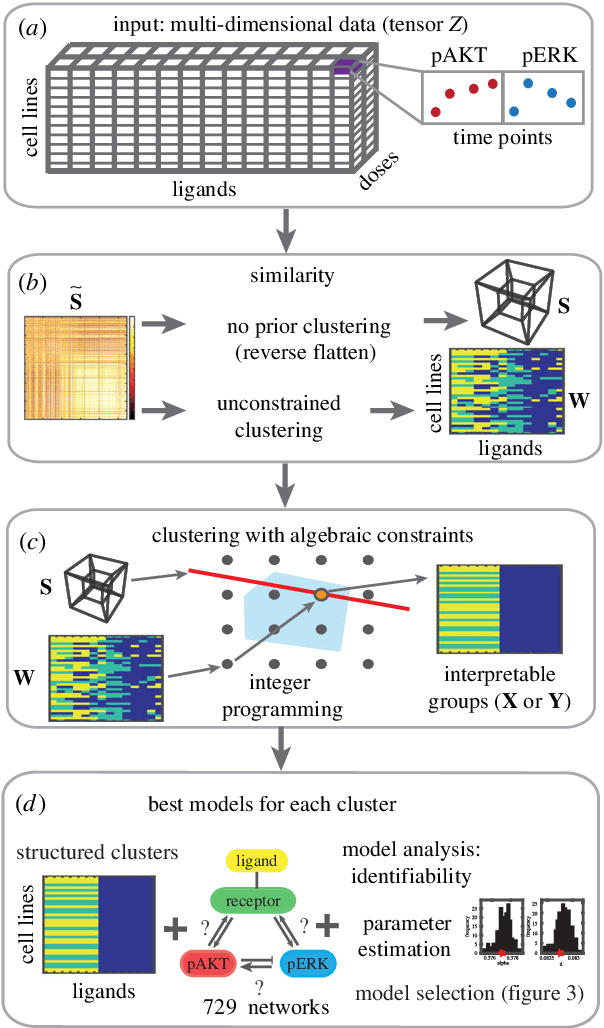
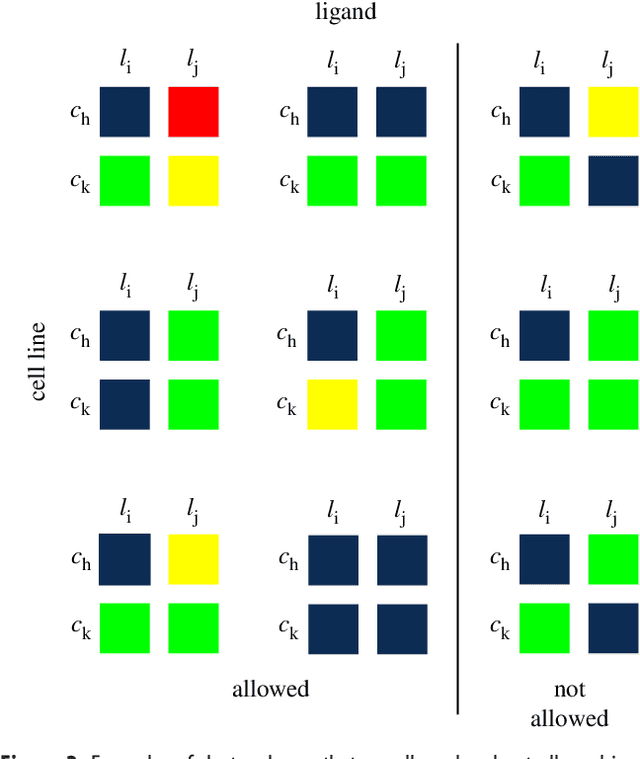
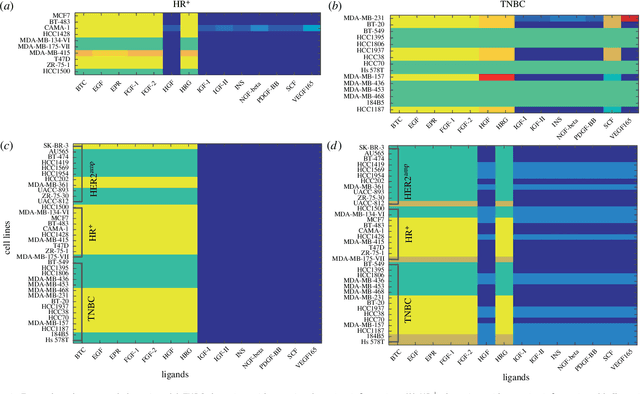
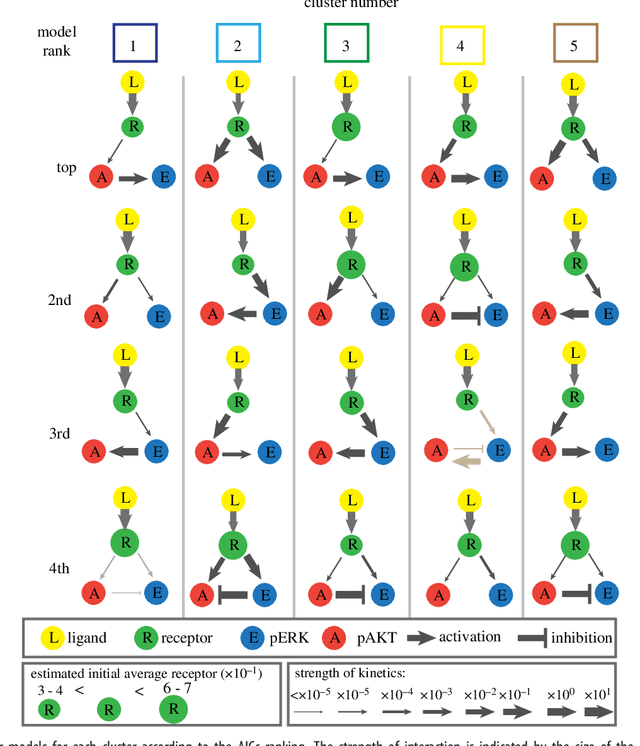
We introduce a tensor-based clustering method to extract sparse, low-dimensional structure from high-dimensional, multi-indexed datasets. Specifically, this framework is designed to enable detection of clusters of data in the presence of structural requirements which we encode as algebraic constraints in a linear program. We illustrate our method on a collection of experiments measuring the response of genetically diverse breast cancer cell lines to an array of ligands. Each experiment consists of a cell line-ligand combination, and contains time-course measurements of the early-signalling kinases MAPK and AKT at two different ligand dose levels. By imposing appropriate structural constraints and respecting the multi-indexed structure of the data, our clustering analysis can be optimized for biological interpretation and therapeutic understanding. We then perform a systematic, large-scale exploration of mechanistic models of MAPK-AKT crosstalk for each cluster. This analysis allows us to quantify the heterogeneity of breast cancer cell subtypes, and leads to hypotheses about the mechanisms by which cell lines respond to ligands. Our clustering method is general and can be tailored to a variety of applications in science and industry.
Integrating sentiment and social structure to determine preference alignments: The Irish Marriage Referendum
Feb 18, 2017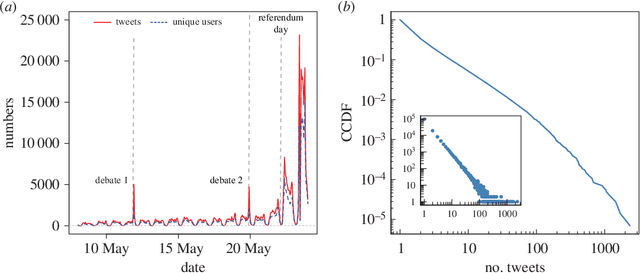
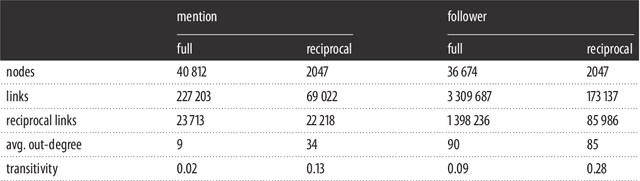
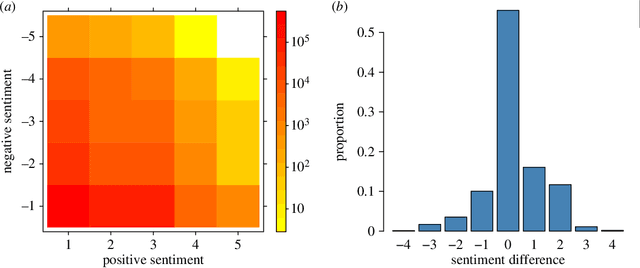
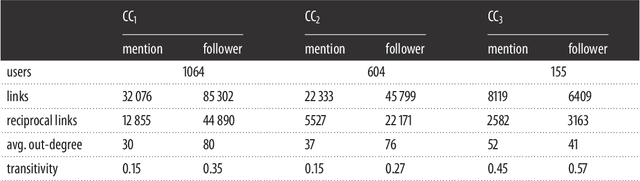
We examine the relationship between social structure and sentiment through the analysis of a large collection of tweets about the Irish Marriage Referendum of 2015. We obtain the sentiment of every tweet with the hashtags #marref and #marriageref that was posted in the days leading to the referendum, and construct networks to aggregate sentiment and use it to study the interactions among users. Our results show that the sentiment of mention tweets posted by users is correlated with the sentiment of received mentions, and there are significantly more connections between users with similar sentiment scores than among users with opposite scores in the mention and follower networks. We combine the community structure of the two networks with the activity level of the users and sentiment scores to find groups of users who support voting `yes' or `no' in the referendum. There were numerous conversations between users on opposing sides of the debate in the absence of follower connections, which suggests that there were efforts by some users to establish dialogue and debate across ideological divisions. Our analysis shows that social structure can be integrated successfully with sentiment to analyse and understand the disposition of social media users. These results have potential applications in the integration of data and meta-data to study opinion dynamics, public opinion modelling, and polling.
* 16 pages, 12 figures