 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor-based second-order causal discovery
Jun 16, 2026Causal discovery seeks to uncover the causal dependencies among variables. For this purpose, we propose an algorithm called Tensor-based Second-order Causal Discovery (TSCD). Its input is a tensor obtained from the covariance matrices of observational and interventional data. Assuming the causal dependencies follow a linear structural equation model on a directed acyclic graph (DAG), TSCD outputs the DAG and the functions on its edges, requiring only that the noise variables are uncorrelated. We also implement a version of the approach for nonlinear models. Our focus on second-order statistics (via the covariance matrices) is motivated by their statistical and computational efficiency relative to higher-order moments, their identifiability relative to first-order statistics, and that they work regardless of whether the variables are Gaussian. We show that TSCD has identifiable causal order and parameters from a number of interventions that is logarithmic in the number of variables. Experiments show that TSCD is robust to noise, competitive with existing methods, and scales to hundreds of variables.
Causal discovery under mean independence and linearity
May 06, 2026Causal discovery methods such as LiNGAM identify causal structure from observational data by assuming mutually independent disturbances. This assumption is fragile: shared volatility, common scale effects, or other forms of dependence can cause the methods to recover the wrong causal order, even with infinite data. We introduce the Linear Mean-Independent Acyclic Model (LiMIAM), which replaces full independence with weaker one-sided mean-independence restrictions on the disturbances. Under finite-order consequences of these restrictions, source nodes are generically identifiable, and hence a compatible causal order can be recovered recursively. Our proof is constructive and leads to DirectLiMIAM, a sequential residual-based algorithm for causal discovery under dependent noise. In simulations with mean-independent but dependent disturbances, DirectLiMIAM outperforms LiNGAM methods. A large-scale empirical application to the oil market highlights the implausibility of the independence assumption and the ability of DirectLiMIAM to recover a realistic causal ordering, from policy to production and from prices to inflation.
Multi-context principal component analysis
Jan 21, 2026Principal component analysis (PCA) is a tool to capture factors that explain variation in data. Across domains, data are now collected across multiple contexts (for example, individuals with different diseases, cells of different types, or words across texts). While the factors explaining variation in data are undoubtedly shared across subsets of contexts, no tools currently exist to systematically recover such factors. We develop multi-context principal component analysis (MCPCA), a theoretical and algorithmic framework that decomposes data into factors shared across subsets of contexts. Applied to gene expression, MCPCA reveals axes of variation shared across subsets of cancer types and an axis whose variability in tumor cells, but not mean, is associated with lung cancer progression. Applied to contextualized word embeddings from language models, MCPCA maps stages of a debate on human nature, revealing a discussion between science and fiction over decades. These axes are not found by combining data across contexts or by restricting to individual contexts. MCPCA is a principled generalization of PCA to address the challenge of understanding factors underlying data across contexts.
Linear causal disentanglement via higher-order cumulants
Jul 05, 2024Linear causal disentanglement is a recent method in causal representation learning to describe a collection of observed variables via latent variables with causal dependencies between them. It can be viewed as a generalization of both independent component analysis and linear structural equation models. We study the identifiability of linear causal disentanglement, assuming access to data under multiple contexts, each given by an intervention on a latent variable. We show that one perfect intervention on each latent variable is sufficient and in the worst case necessary to recover parameters under perfect interventions, generalizing previous work to allow more latent than observed variables. We give a constructive proof that computes parameters via a coupled tensor decomposition. For soft interventions, we find the equivalence class of latent graphs and parameters that are consistent with observed data, via the study of a system of polynomial equations. Our results hold assuming the existence of non-zero higher-order cumulants, which implies non-Gaussianity of variables.
Contrastive independent component analysis
Jul 02, 2024Visualizing data and finding patterns in data are ubiquitous problems in the sciences. Increasingly, applications seek signal and structure in a contrastive setting: a foreground dataset relative to a background dataset. For this purpose, we propose contrastive independent component analysis (cICA). This generalizes independent component analysis to independent latent variables across a foreground and background. We propose a hierarchical tensor decomposition algorithm for cICA. We study the identifiability of cICA and demonstrate its performance visualizing data and finding patterns in data, using synthetic and real-world datasets, comparing the approach to existing contrastive methods.
Supermodular Rank: Set Function Decomposition and Optimization
May 24, 2023We define the supermodular rank of a function on a lattice. This is the smallest number of terms needed to decompose it into a sum of supermodular functions. The supermodular summands are defined with respect to different partial orders. We characterize the maximum possible value of the supermodular rank and describe the functions with fixed supermodular rank. We analogously define the submodular rank. We use submodular decompositions to optimize set functions. Given a bound on the submodular rank of a set function, we formulate an algorithm that splits an optimization problem into submodular subproblems. We show that this method improves the approximation ratio guarantees of several algorithms for monotone set function maximization and ratio of set functions minimization, at a computation overhead that depends on the submodular rank.
Linear Causal Disentanglement via Interventions
Nov 29, 2022Causal disentanglement seeks a representation of data involving latent variables that relate to one another via a causal model. A representation is identifiable if both the latent model and the transformation from latent to observed variables are unique. In this paper, we study observed variables that are a linear transformation of a linear latent causal model. Data from interventions are necessary for identifiability: if one latent variable is missing an intervention, we show that there exist distinct models that cannot be distinguished. Conversely, we show that a single intervention on each latent variable is sufficient for identifiability. Our proof uses a generalization of the RQ decomposition of a matrix that replaces the usual orthogonal and upper triangular conditions with analogues depending on a partial order on the rows of the matrix, with partial order determined by a latent causal model. We corroborate our theoretical results with a method for causal disentanglement that accurately recovers a latent causal model.
Learning Paths from Signature Tensors
Sep 05, 2018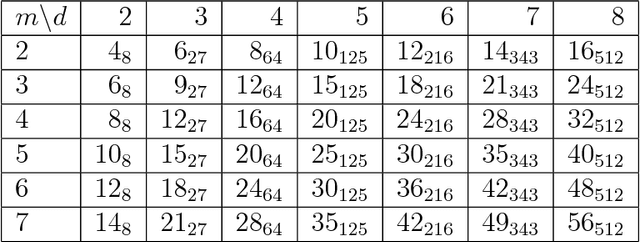
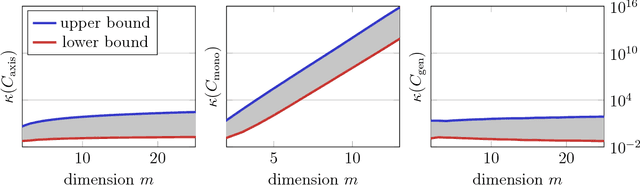
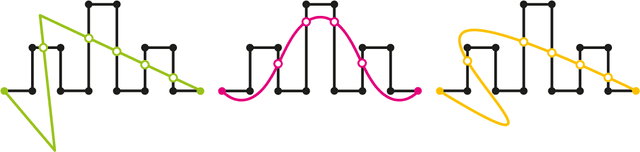
Matrix congruence extends naturally to the setting of tensors. We apply methods from tensor decomposition, algebraic geometry and numerical optimization to this group action. Given a tensor in the orbit of another tensor, we compute a matrix which transforms one to the other. Our primary application is an inverse problem from stochastic analysis: the recovery of paths from their signature tensors of order three. We establish identifiability results and recovery algorithms for piecewise linear paths, polynomial paths, and generic dictionaries. A detailed analysis of the relevant condition numbers is presented. We also compute the shortest path with a given signature tensor.
Duality of Graphical Models and Tensor Networks
Oct 04, 2017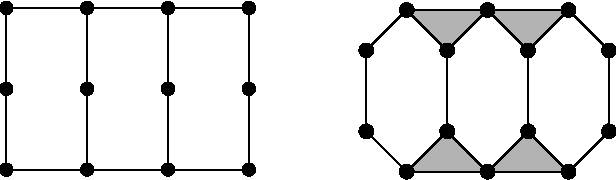


In this article we show the duality between tensor networks and undirected graphical models with discrete variables. We study tensor networks on hypergraphs, which we call tensor hypernetworks. We show that the tensor hypernetwork on a hypergraph exactly corresponds to the graphical model given by the dual hypergraph. We translate various notions under duality. For example, marginalization in a graphical model is dual to contraction in the tensor network. Algorithms also translate under duality. We show that belief propagation corresponds to a known algorithm for tensor network contraction. This article is a reminder that the research areas of graphical models and tensor networks can benefit from interaction.
Mixtures and products in two graphical models
Sep 15, 2017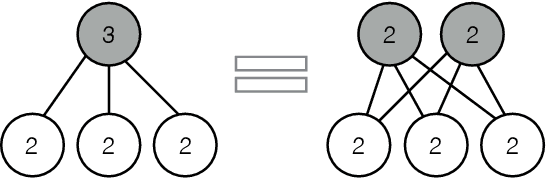
We compare two statistical models of three binary random variables. One is a mixture model and the other is a product of mixtures model called a restricted Boltzmann machine. Although the two models we study look different from their parametrizations, we show that they represent the same set of distributions on the interior of the probability simplex, and are equal up to closure. We give a semi-algebraic description of the model in terms of six binomial inequalities and obtain closed form expressions for the maximum likelihood estimates. We briefly discuss extensions to larger models.