 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Preserving Neural Architectures on Manifolds with Boundary
Feb 03, 2026Preserving geometric structure is important in learning. We propose a unified class of geometry-aware architectures that interleave geometric updates between layers, where both projection layers and intrinsic exponential map updates arise as discretizations of projected dynamical systems on manifolds (with or without boundary). Within this framework, we establish universal approximation results for constrained neural ODEs. We also analyze architectures that enforce geometry only at the output, proving a separate universal approximation property that enables direct comparison to interleaved designs. When the constraint set is unknown, we learn projections via small-time heat-kernel limits, showing diffusion/flow-matching can be used as data-based projections. Experiments on dynamics over S^2 and SO(3), and diffusion on S^{d-1}-valued features demonstrate exact feasibility for analytic updates and strong performance for learned projections
Risk Phase Transitions in Spiked Regression: Alignment Driven Benign and Catastrophic Overfitting
Oct 01, 2025This paper analyzes the generalization error of minimum-norm interpolating solutions in linear regression using spiked covariance data models. The paper characterizes how varying spike strengths and target-spike alignments can affect risk, especially in overparameterized settings. The study presents an exact expression for the generalization error, leading to a comprehensive classification of benign, tempered, and catastrophic overfitting regimes based on spike strength, the aspect ratio $c=d/n$ (particularly as $c \to \infty$), and target alignment. Notably, in well-specified aligned problems, increasing spike strength can surprisingly induce catastrophic overfitting before achieving benign overfitting. The paper also reveals that target-spike alignment is not always advantageous, identifying specific, sometimes counterintuitive, conditions for its benefit or detriment. Alignment with the spike being detrimental is empirically demonstrated to persist in nonlinear models.
Generalization for Least Squares Regression With Simple Spiked Covariances
Oct 17, 2024


Random matrix theory has proven to be a valuable tool in analyzing the generalization of linear models. However, the generalization properties of even two-layer neural networks trained by gradient descent remain poorly understood. To understand the generalization performance of such networks, it is crucial to characterize the spectrum of the feature matrix at the hidden layer. Recent work has made progress in this direction by describing the spectrum after a single gradient step, revealing a spiked covariance structure. Yet, the generalization error for linear models with spiked covariances has not been previously determined. This paper addresses this gap by examining two simple models exhibiting spiked covariances. We derive their generalization error in the asymptotic proportional regime. Our analysis demonstrates that the eigenvector and eigenvalue corresponding to the spike significantly influence the generalization error.
On Regularization via Early Stopping for Least Squares Regression
Jun 06, 2024A fundamental problem in machine learning is understanding the effect of early stopping on the parameters obtained and the generalization capabilities of the model. Even for linear models, the effect is not fully understood for arbitrary learning rates and data. In this paper, we analyze the dynamics of discrete full batch gradient descent for linear regression. With minimal assumptions, we characterize the trajectory of the parameters and the expected excess risk. Using this characterization, we show that when training with a learning rate schedule $\eta_k$, and a finite time horizon $T$, the early stopped solution $\beta_T$ is equivalent to the minimum norm solution for a generalized ridge regularized problem. We also prove that early stopping is beneficial for generic data with arbitrary spectrum and for a wide variety of learning rate schedules. We provide an estimate for the optimal stopping time and empirically demonstrate the accuracy of our estimate.
Discrete error dynamics of mini-batch gradient descent for least squares regression
Jun 06, 2024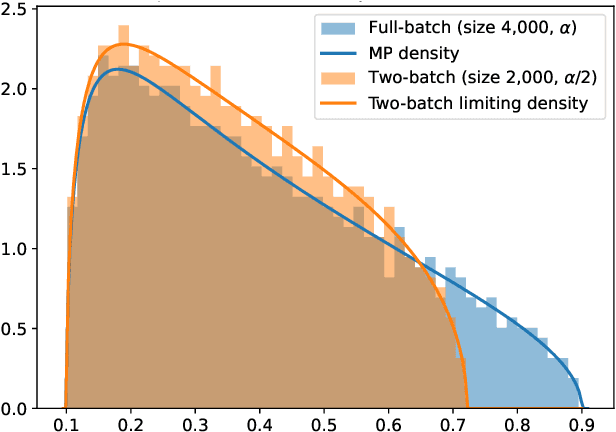
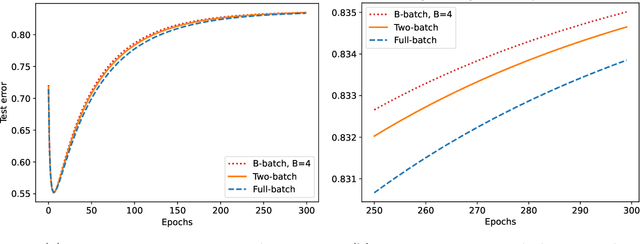
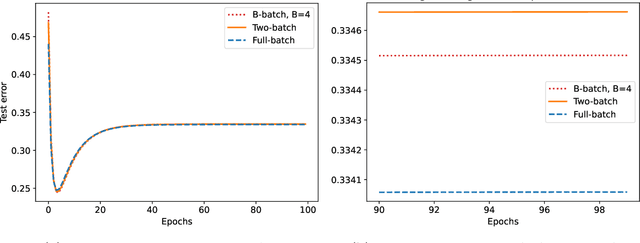
We study the discrete dynamics of mini-batch gradient descent for least squares regression when sampling without replacement. We show that the dynamics and generalization error of mini-batch gradient descent depends on a sample cross-covariance matrix $Z$ between the original features $X$ and a set of new features $\widetilde{X}$, in which each feature is modified by the mini-batches that appear before it during the learning process in an averaged way. Using this representation, we rigorously establish that the dynamics of mini-batch and full-batch gradient descent agree up to leading order with respect to the step size using the linear scaling rule. We also study discretization effects that a continuous-time gradient flow analysis cannot detect, and show that mini-batch gradient descent converges to a step-size dependent solution, in contrast with full-batch gradient descent. Finally, we investigate the effects of batching, assuming a random matrix model, by using tools from free probability theory to numerically compute the spectrum of $Z$.
Near-Interpolators: Rapid Norm Growth and the Trade-Off between Interpolation and Generalization
Mar 12, 2024We study the generalization capability of nearly-interpolating linear regressors: $\boldsymbol{\beta}$'s whose training error $\tau$ is positive but small, i.e., below the noise floor. Under a random matrix theoretic assumption on the data distribution and an eigendecay assumption on the data covariance matrix $\boldsymbol{\Sigma}$, we demonstrate that any near-interpolator exhibits rapid norm growth: for $\tau$ fixed, $\boldsymbol{\beta}$ has squared $\ell_2$-norm $\mathbb{E}[\|{\boldsymbol{\beta}}\|_{2}^{2}] = \Omega(n^{\alpha})$ where $n$ is the number of samples and $\alpha >1$ is the exponent of the eigendecay, i.e., $\lambda_i(\boldsymbol{\Sigma}) \sim i^{-\alpha}$. This implies that existing data-independent norm-based bounds are necessarily loose. On the other hand, in the same regime we precisely characterize the asymptotic trade-off between interpolation and generalization. Our characterization reveals that larger norm scaling exponents $\alpha$ correspond to worse trade-offs between interpolation and generalization. We verify empirically that a similar phenomenon holds for nearly-interpolating shallow neural networks.
Spectral Neural Networks: Approximation Theory and Optimization Landscape
Oct 01, 2023
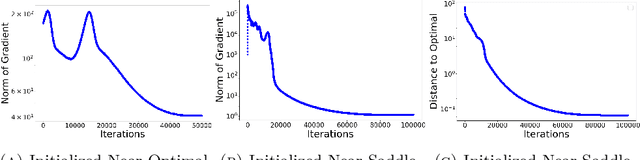
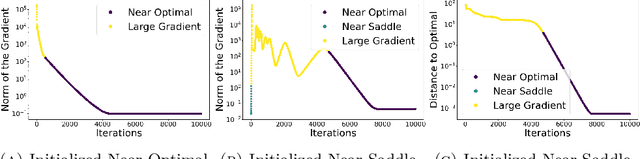
There is a large variety of machine learning methodologies that are based on the extraction of spectral geometric information from data. However, the implementations of many of these methods often depend on traditional eigensolvers, which present limitations when applied in practical online big data scenarios. To address some of these challenges, researchers have proposed different strategies for training neural networks as alternatives to traditional eigensolvers, with one such approach known as Spectral Neural Network (SNN). In this paper, we investigate key theoretical aspects of SNN. First, we present quantitative insights into the tradeoff between the number of neurons and the amount of spectral geometric information a neural network learns. Second, we initiate a theoretical exploration of the optimization landscape of SNN's objective to shed light on the training dynamics of SNN. Unlike typical studies of convergence to global solutions of NN training dynamics, SNN presents an additional complexity due to its non-convex ambient loss function.
Generalization Error without Independence: Denoising, Linear Regression, and Transfer Learning
May 26, 2023Studying the generalization abilities of linear models with real data is a central question in statistical learning. While there exist a limited number of prior important works (Loureiro et al. (2021A, 2021B), Wei et al. 2022) that do validate theoretical work with real data, these works have limitations due to technical assumptions. These assumptions include having a well-conditioned covariance matrix and having independent and identically distributed data. These assumptions are not necessarily valid for real data. Additionally, prior works that do address distributional shifts usually make technical assumptions on the joint distribution of the train and test data (Tripuraneni et al. 2021, Wu and Xu 2020), and do not test on real data. In an attempt to address these issues and better model real data, we look at data that is not I.I.D. but has a low-rank structure. Further, we address distributional shift by decoupling assumptions on the training and test distribution. We provide analytical formulas for the generalization error of the denoising problem that are asymptotically exact. These are used to derive theoretical results for linear regression, data augmentation, principal component regression, and transfer learning. We validate all of our theoretical results on real data and have a low relative mean squared error of around 1% between the empirical risk and our estimated risk.
Supermodular Rank: Set Function Decomposition and Optimization
May 24, 2023We define the supermodular rank of a function on a lattice. This is the smallest number of terms needed to decompose it into a sum of supermodular functions. The supermodular summands are defined with respect to different partial orders. We characterize the maximum possible value of the supermodular rank and describe the functions with fixed supermodular rank. We analogously define the submodular rank. We use submodular decompositions to optimize set functions. Given a bound on the submodular rank of a set function, we formulate an algorithm that splits an optimization problem into submodular subproblems. We show that this method improves the approximation ratio guarantees of several algorithms for monotone set function maximization and ratio of set functions minimization, at a computation overhead that depends on the submodular rank.
Under-Parameterized Double Descent for Ridge Regularized Least Squares Denoising of Data on a Line
May 24, 2023The relationship between the number of training data points, the number of parameters in a statistical model, and the generalization capabilities of the model has been widely studied. Previous work has shown that double descent can occur in the over-parameterized regime, and believe that the standard bias-variance trade-off holds in the under-parameterized regime. In this paper, we present a simple example that provably exhibits double descent in the under-parameterized regime. For simplicity, we look at the ridge regularized least squares denoising problem with data on a line embedded in high-dimension space. By deriving an asymptotically accurate formula for the generalization error, we observe sample-wise and parameter-wise double descent with the peak in the under-parameterized regime rather than at the interpolation point or in the over-parameterized regime. Further, the peak of the sample-wise double descent curve corresponds to a peak in the curve for the norm of the estimator, and adjusting $\mu$, the strength of the ridge regularization, shifts the location of the peak. We observe that parameter-wise double descent occurs for this model for small $\mu$. For larger values of $\mu$, we observe that the curve for the norm of the estimator has a peak but that this no longer translates to a peak in the generalization error. Moreover, we study the training error for this problem. The considered problem setup allows for studying the interaction between two regularizers. We provide empirical evidence that the model implicitly favors using the ridge regularizer over the input data noise regularizer. Thus, we show that even though both regularizers regularize the same quantity, i.e., the norm of the estimator, they are not equivalent.