 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Value Function Semi-Algebraic Set in Partially Observable Markov Decision Processes
Jun 02, 2026We study the geometry of feasible value functions in infinite-horizon partially observable Markov decision processes (POMDPs) under memoryless stochastic policies. Our main contribution is a characterization of the feasible set of value functions as a semi-algebraic set, defined by explicit polynomial inequalities determined by the transition dynamics, observation kernel, and reward structure of the POMDP. This result extends prior work for fully observable Markov decision processes, where the feasible set is known to be a polytope, to the substantially more intricate partially observable setting. In contrast to the polyhedral structure arising in MDPs, partial observability induces fundamentally nonlinear constraints, leading to a richer and more complex geometric structure. Our geometric characterization provides new insight into the landscape of policy optimization in both MDPs and POMDPs, and reveals qualitative phenomena unique to partial observability, including the emergence of isolated local maximizers of the long-term reward and their dependence on the initial state distribution.
* 39 pages, 5 figures
Implicit Bias of Mirror Flow in Homogeneous Neural Networks: Sparse and Dense Feature Learning
May 19, 2026We study the max-margin solutions reached by mirror flow in deep neural networks with homogeneous activation functions. Extending classical results on gradient flow, we derive a novel balance equation for mirror flow from convex duality, enabling a characterization of the horizon function governing the induced margin. We further establish max-margin characterizations together with convergence rates and norm growth estimates. Finally, we support our theory through experiments on synthetic datasets and standard vision tasks. Concretely, we show that: (1) distinct non-homogeneous mirror maps can induce the same max-margin solution; (2) convergence can be extremely slow, including exponentially slow regimes; and (3) although all considered mirror maps exhibit feature learning, they can produce markedly different representations, ranging from sparse to dense neuron activations. Together, these results provide a unified perspective on sparse and dense feature learning in homogeneous neural networks, highlighting how mirror maps shape both optimization dynamics and the geometry of the learned classifiers.
Harmful Overfitting in Sobolev Spaces
Jan 31, 2026Motivated by recent work on benign overfitting in overparameterized machine learning, we study the generalization behavior of functions in Sobolev spaces $W^{k, p}(\mathbb{R}^d)$ that perfectly fit a noisy training data set. Under assumptions of label noise and sufficient regularity in the data distribution, we show that approximately norm-minimizing interpolators, which are canonical solutions selected by smoothness bias, exhibit harmful overfitting: even as the training sample size $n \to \infty$, the generalization error remains bounded below by a positive constant with high probability. Our results hold for arbitrary values of $p \in [1, \infty)$, in contrast to prior results studying the Hilbert space case ($p = 2$) using kernel methods. Our proof uses a geometric argument which identifies harmful neighborhoods of the training data using Sobolev inequalities.
Zero-Shot Context Generalization in Reinforcement Learning from Few Training Contexts
Jul 10, 2025



Deep reinforcement learning (DRL) has achieved remarkable success across multiple domains, including competitive games, natural language processing, and robotics. Despite these advancements, policies trained via DRL often struggle to generalize to evaluation environments with different parameters. This challenge is typically addressed by training with multiple contexts and/or by leveraging additional structure in the problem. However, obtaining sufficient training data across diverse contexts can be impractical in real-world applications. In this work, we consider contextual Markov decision processes (CMDPs) with transition and reward functions that exhibit regularity in context parameters. We introduce the context-enhanced Bellman equation (CEBE) to improve generalization when training on a single context. We prove both analytically and empirically that the CEBE yields a first-order approximation to the Q-function trained across multiple contexts. We then derive context sample enhancement (CSE) as an efficient data augmentation method for approximating the CEBE in deterministic control environments. We numerically validate the performance of CSE in simulation environments, showcasing its potential to improve generalization in DRL.
On the Local Complexity of Linear Regions in Deep ReLU Networks
Dec 24, 2024
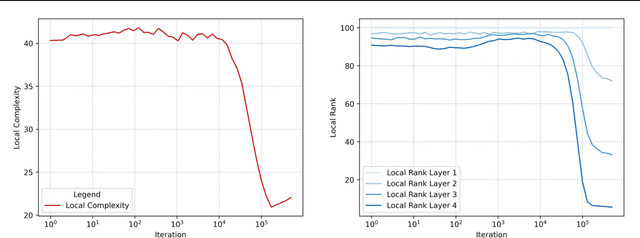
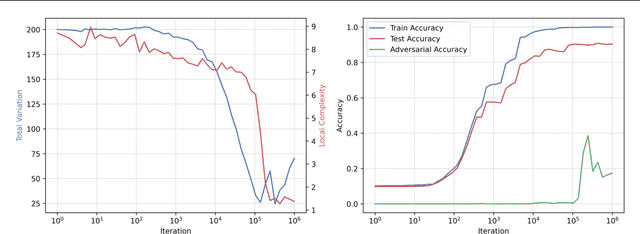

We define the local complexity of a neural network with continuous piecewise linear activations as a measure of the density of linear regions over an input data distribution. We show theoretically that ReLU networks that learn low-dimensional feature representations have a lower local complexity. This allows us to connect recent empirical observations on feature learning at the level of the weight matrices with concrete properties of the learned functions. In particular, we show that the local complexity serves as an upper bound on the total variation of the function over the input data distribution and thus that feature learning can be related to adversarial robustness. Lastly, we consider how optimization drives ReLU networks towards solutions with lower local complexity. Overall, this work contributes a theoretical framework towards relating geometric properties of ReLU networks to different aspects of learning such as feature learning and representation cost.
Supermodular Rank: Set Function Decomposition and Optimization
May 24, 2023We define the supermodular rank of a function on a lattice. This is the smallest number of terms needed to decompose it into a sum of supermodular functions. The supermodular summands are defined with respect to different partial orders. We characterize the maximum possible value of the supermodular rank and describe the functions with fixed supermodular rank. We analogously define the submodular rank. We use submodular decompositions to optimize set functions. Given a bound on the submodular rank of a set function, we formulate an algorithm that splits an optimization problem into submodular subproblems. We show that this method improves the approximation ratio guarantees of several algorithms for monotone set function maximization and ratio of set functions minimization, at a computation overhead that depends on the submodular rank.
Characterizing the Spectrum of the NTK via a Power Series Expansion
Nov 15, 2022Under mild conditions on the network initialization we derive a power series expansion for the Neural Tangent Kernel (NTK) of arbitrarily deep feedforward networks in the infinite width limit. We provide expressions for the coefficients of this power series which depend on both the Hermite coefficients of the activation function as well as the depth of the network. We observe faster decay of the Hermite coefficients leads to faster decay in the NTK coefficients. Using this series, first we relate the effective rank of the NTK to the effective rank of the input-data Gram. Second, for data drawn uniformly on the sphere we derive an explicit formula for the eigenvalues of the NTK, which shows faster decay in the NTK coefficients implies a faster decay in its spectrum. From this we recover existing results on eigenvalue asymptotics for ReLU networks and comment on how the activation function influences the RKHS. Finally, for generic data and activation functions with sufficiently fast Hermite coefficient decay, we derive an asymptotic upper bound on the spectrum of the NTK.
Spectral Bias Outside the Training Set for Deep Networks in the Kernel Regime
Jun 06, 2022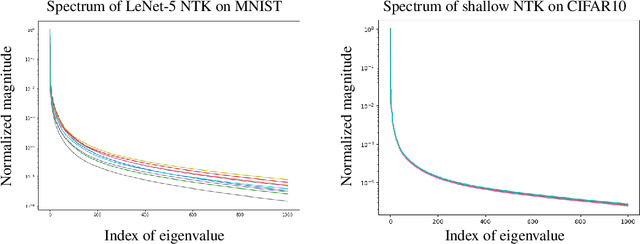
We provide quantitative bounds measuring the $L^2$ difference in function space between the trajectory of a finite-width network trained on finitely many samples from the idealized kernel dynamics of infinite width and infinite data. An implication of the bounds is that the network is biased to learn the top eigenfunctions of the Neural Tangent Kernel not just on the training set but over the entire input space. This bias depends on the model architecture and input distribution alone and thus does not depend on the target function which does not need to be in the RKHS of the kernel. The result is valid for deep architectures with fully connected, convolutional, and residual layers. Furthermore the width does not need to grow polynomially with the number of samples in order to obtain high probability bounds up to a stopping time. The proof exploits the low-effective-rank property of the Fisher Information Matrix at initialization, which implies a low effective dimension of the model (far smaller than the number of parameters). We conclude that local capacity control from the low effective rank of the Fisher Information Matrix is still underexplored theoretically.
Implicit Bias of MSE Gradient Optimization in Underparameterized Neural Networks
Jan 12, 2022We study the dynamics of a neural network in function space when optimizing the mean squared error via gradient flow. We show that in the underparameterized regime the network learns eigenfunctions of an integral operator $T_{K^\infty}$ determined by the Neural Tangent Kernel (NTK) at rates corresponding to their eigenvalues. For example, for uniformly distributed data on the sphere $S^{d - 1}$ and rotation invariant weight distributions, the eigenfunctions of $T_{K^\infty}$ are the spherical harmonics. Our results can be understood as describing a spectral bias in the underparameterized regime. The proofs use the concept of "Damped Deviations", where deviations of the NTK matter less for eigendirections with large eigenvalues due to the occurence of a damping factor. Aside from the underparameterized regime, the damped deviations point-of-view can be used to track the dynamics of the empirical risk in the overparameterized setting, allowing us to extend certain results in the literature. We conclude that damped deviations offers a simple and unifying perspective of the dynamics when optimizing the squared error.
How Framelets Enhance Graph Neural Networks
Feb 13, 2021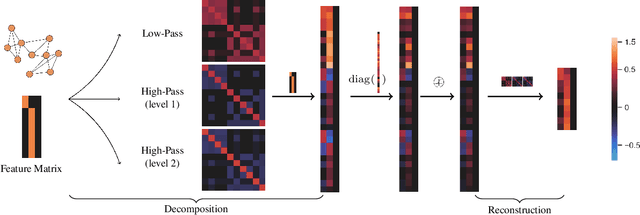
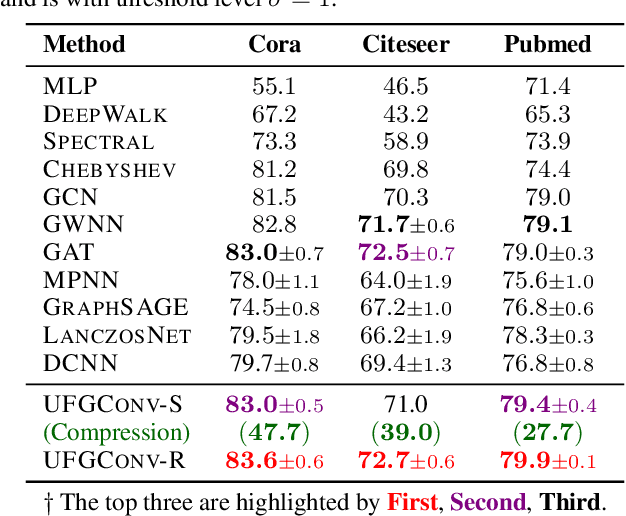
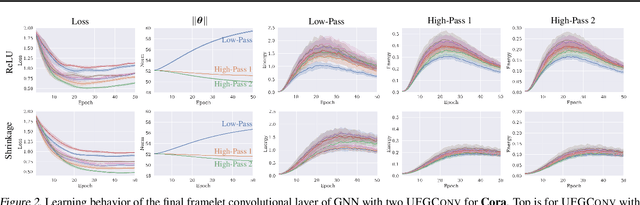
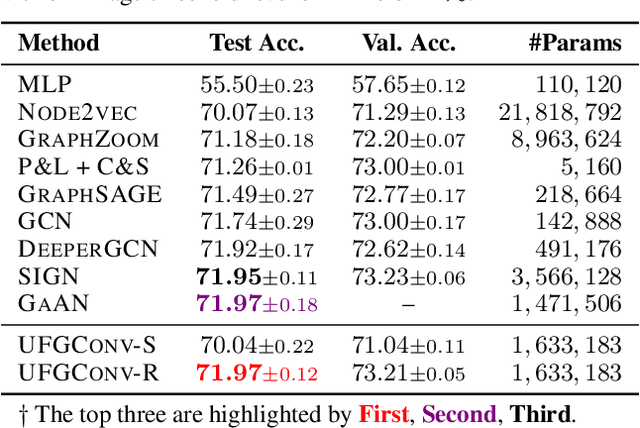
This paper presents a new approach for assembling graph neural networks based on framelet transforms. The latter provides a multi-scale representation for graph-structured data. With the framelet system, we can decompose the graph feature into low-pass and high-pass frequencies as extracted features for network training, which then defines a framelet-based graph convolution. The framelet decomposition naturally induces a graph pooling strategy by aggregating the graph feature into low-pass and high-pass spectra, which considers both the feature values and geometry of the graph data and conserves the total information. The graph neural networks with the proposed framelet convolution and pooling achieve state-of-the-art performance in many types of node and graph prediction tasks. Moreover, we propose shrinkage as a new activation for the framelet convolution, which thresholds the high-frequency information at different scales. Compared to ReLU, shrinkage in framelet convolution improves the graph neural network model in terms of denoising and signal compression: noises in both node and structure can be significantly reduced by accurately cutting off the high-pass coefficients from framelet decomposition, and the signal can be compressed to less than half its original size with the prediction performance well preserved.