 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation-Space Anchored Access Control for Multi-Class Permission Reasoning in Large Language Models
Jan 20, 2026Large language models (LLMs) are increasingly deployed over knowledge bases for efficient knowledge retrieval and question answering. However, LLMs can inadvertently answer beyond a user's permission scope, leaking sensitive content, thus making it difficult to deploy knowledge-base QA under fine-grained access control requirements. In this work, we identify a geometric regularity in intermediate activations: for the same query, representations induced by different permission scopes cluster distinctly and are readily separable. Building on this separability, we propose Activation-space Anchored Access Control (AAAC), a training-free framework for multi-class permission control. AAAC constructs an anchor bank, with one permission anchor per class, from a small offline sample set and requires no fine-tuning. At inference time, a multi-anchor steering mechanism redirects each query's activations toward the anchor-defined authorized region associated with the current user, thereby suppressing over-privileged generations by design. Finally, extensive experiments across three LLM families demonstrate that AAAC reduces permission violation rates by up to 86.5% and prompt-based attack success rates by 90.7%, while improving response usability with minor inference overhead compared to baselines.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
ICH-SCNet: Intracerebral Hemorrhage Segmentation and Prognosis Classification Network Using CLIP-guided SAM mechanism
Nov 07, 2024Intracerebral hemorrhage (ICH) is the most fatal subtype of stroke and is characterized by a high incidence of disability. Accurate segmentation of the ICH region and prognosis prediction are critically important for developing and refining treatment plans for post-ICH patients. However, existing approaches address these two tasks independently and predominantly focus on imaging data alone, thereby neglecting the intrinsic correlation between the tasks and modalities. This paper introduces a multi-task network, ICH-SCNet, designed for both ICH segmentation and prognosis classification. Specifically, we integrate a SAM-CLIP cross-modal interaction mechanism that combines medical text and segmentation auxiliary information with neuroimaging data to enhance cross-modal feature recognition. Additionally, we develop an effective feature fusion module and a multi-task loss function to improve performance further. Extensive experiments on an ICH dataset reveal that our approach surpasses other state-of-the-art methods. It excels in the overall performance of classification tasks and outperforms competing models in all segmentation task metrics.
Exact Conversion of In-Context Learning to Model Weights in Linearized-Attention Transformers
Jun 06, 2024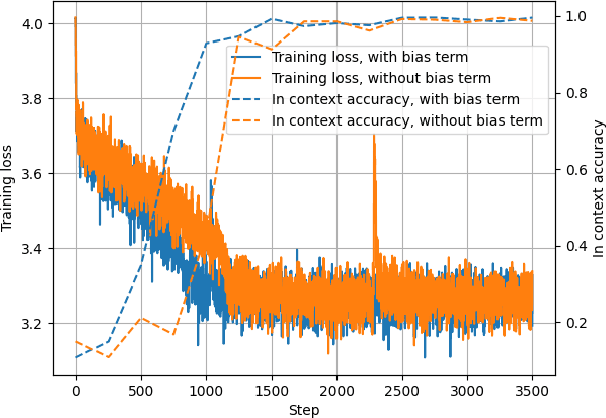
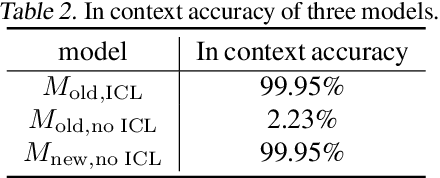

In-Context Learning (ICL) has been a powerful emergent property of large language models that has attracted increasing attention in recent years. In contrast to regular gradient-based learning, ICL is highly interpretable and does not require parameter updates. In this paper, we show that, for linearized transformer networks, ICL can be made explicit and permanent through the inclusion of bias terms. We mathematically demonstrate the equivalence between a model with ICL demonstration prompts and the same model with the additional bias terms. Our algorithm (ICLCA) allows for exact conversion in an inexpensive manner. Existing methods are not exact and require expensive parameter updates. We demonstrate the efficacy of our approach through experiments that show the exact incorporation of ICL tokens into a linear transformer. We further suggest how our method can be adapted to achieve cheap approximate conversion of ICL tokens, even in regular transformer networks that are not linearized. Our experiments on GPT-2 show that, even though the conversion is only approximate, the model still gains valuable context from the included bias terms.
Towards Understanding How Transformer Perform Multi-step Reasoning with Matching Operation
May 24, 2024
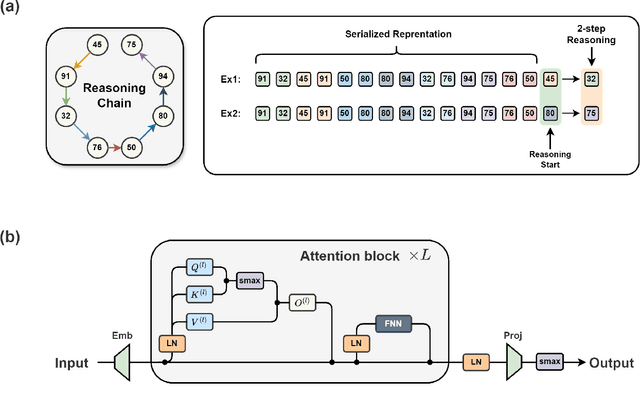
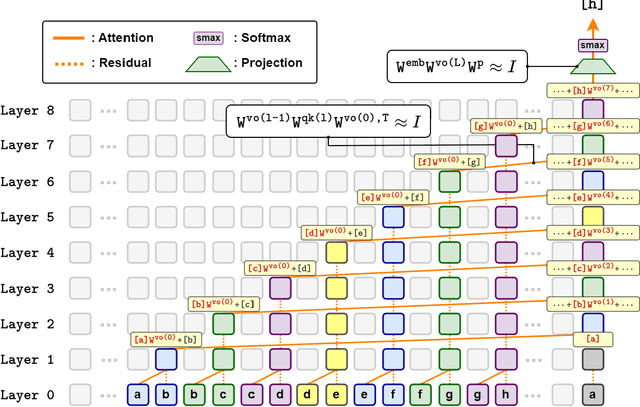
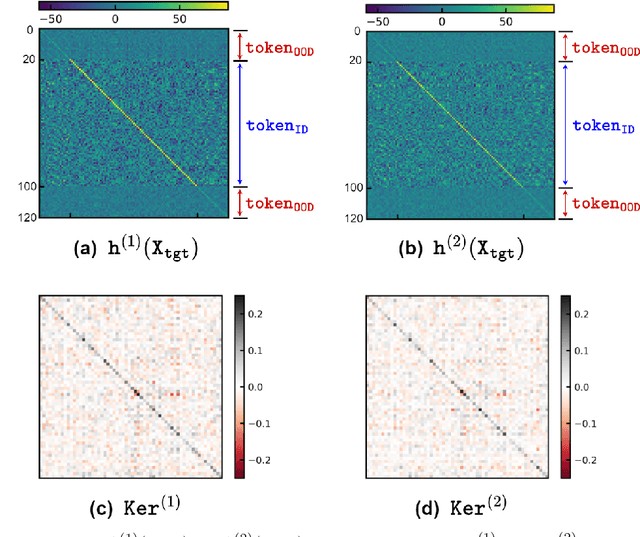
Large language models have consistently struggled with complex reasoning tasks, such as mathematical problem-solving. Investigating the internal reasoning mechanisms of these models can help us design better model architectures and training strategies, ultimately enhancing their reasoning capabilities. In this study, we examine the matching mechanism employed by Transformer for multi-step reasoning on a constructed dataset. We investigate factors that influence the model's matching mechanism and discover that small initialization and post-LayerNorm can facilitate the formation of the matching mechanism, thereby enhancing the model's reasoning ability. Moreover, we propose a method to improve the model's reasoning capability by adding orthogonal noise. Finally, we investigate the parallel reasoning mechanism of Transformers and propose a conjecture on the upper bound of the model's reasoning ability based on this phenomenon. These insights contribute to a deeper understanding of the reasoning processes in large language models and guide designing more effective reasoning architectures and training strategies.
Characterizing the Spectrum of the NTK via a Power Series Expansion
Nov 15, 2022Under mild conditions on the network initialization we derive a power series expansion for the Neural Tangent Kernel (NTK) of arbitrarily deep feedforward networks in the infinite width limit. We provide expressions for the coefficients of this power series which depend on both the Hermite coefficients of the activation function as well as the depth of the network. We observe faster decay of the Hermite coefficients leads to faster decay in the NTK coefficients. Using this series, first we relate the effective rank of the NTK to the effective rank of the input-data Gram. Second, for data drawn uniformly on the sphere we derive an explicit formula for the eigenvalues of the NTK, which shows faster decay in the NTK coefficients implies a faster decay in its spectrum. From this we recover existing results on eigenvalue asymptotics for ReLU networks and comment on how the activation function influences the RKHS. Finally, for generic data and activation functions with sufficiently fast Hermite coefficient decay, we derive an asymptotic upper bound on the spectrum of the NTK.
Learning curves for Gaussian process regression with power-law priors and targets
Oct 23, 2021
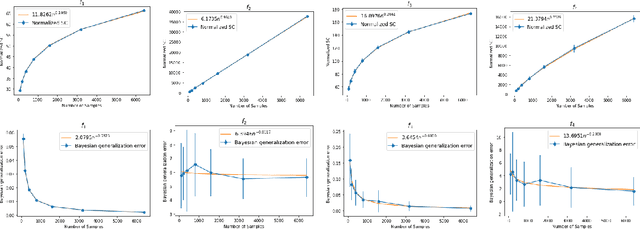
We study the power-law asymptotics of learning curves for Gaussian process regression (GPR). When the eigenspectrum of the prior decays with rate $\alpha$ and the eigenexpansion coefficients of the target function decay with rate $\beta$, we show that the generalization error behaves as $\tilde O(n^{\max\{\frac{1}{\alpha}-1, \frac{1-2\beta}{\alpha}\}})$ with high probability over the draw of $n$ input samples. Under similar assumptions, we show that the generalization error of kernel ridge regression (KRR) has the same asymptotics. Infinitely wide neural networks can be related to KRR with respect to the neural tangent kernel (NTK), which in several cases is known to have a power-law spectrum. Hence our methods can be applied to study the generalization error of infinitely wide neural networks. We present toy experiments demonstrating the theory.
Implicit bias of gradient descent for mean squared error regression with wide neural networks
Jun 12, 2020
We investigate gradient descent training of wide neural networks and the corresponding implicit bias in function space. Focusing on 1D regression, we show that the solution of training a width-$n$ shallow ReLU network is within $n^{- 1/2}$ of the function which fits the training data and whose difference from initialization has smallest 2-norm of the second derivative weighted by $1/\zeta$. The curvature penalty function $1/\zeta$ is expressed in terms of the probability distribution that is utilized to initialize the network parameters, and we compute it explicitly for various common initialization procedures. For instance, asymmetric initialization with a uniform distribution yields a constant curvature penalty, and thence the solution function is the natural cubic spline interpolation of the training data. The statement generalizes to the training trajectories, which in turn are captured by trajectories of spatially adaptive smoothing splines with decreasing regularization strength.