 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Structural Origin of Attention Sink: Variance Discrepancy, Super Neurons, and Dimension Disparity
May 07, 2026Despite the prevalence of the attention sink phenomenon in Large Language Models (LLMs), where initial tokens disproportionately monopolize attention scores, its structural origins remain elusive. This work provides a \textit{mechanistic explanation} for this phenomenon. First, we trace its root to the value aggregation process inherent in self-attention, which induces a systematic variance discrepancy. We further demonstrate that this discrepancy is drastically amplified by the activation of super neurons within Feed-Forward Network (FFN) layers. Specifically, the channel-sparse down-projections trigger a dimension disparity of the first-token representation, necessitating the formation of attention sinks as a structural anchor. Then, we validate this causal chain through two controlled interventions: (i) isolating the aggregation effect via attention mask modifications and (ii) amplifying the variance of targeted token representations. Both interventions can replicate attention sinks at arbitrary positions. Our mechanistic understanding offers a foundation for the systematic control of sink formation. Finally, as a proof of concept, we propose \textit{head-wise RMSNorm}, an architectural modification that stabilizes value aggregation outputs during pre-training. Our experiments demonstrate that restoring statistical parity across positions significantly accelerates convergence.
Towards Instance Segmentation with Polygon Detection Transformers
Mar 10, 2026One of the bottlenecks for instance segmentation today lies in the conflicting requirements of high-resolution inputs and lightweight, real-time inference. To address this bottleneck, we present a Polygon Detection Transformer (Poly-DETR) to reformulate instance segmentation as sparse vertex regression via Polar Representation, thereby eliminating the reliance on dense pixel-wise mask prediction. Considering the box-to-polygon reference shift in Detection Transformers, we propose Polar Deformable Attention and Position-Aware Training Scheme to dynamically update supervision and focus attention on boundary cues. Compared with state-of-the-art polar-based methods, Poly-DETR achieves a 4.7 mAP improvement on MS COCO test-dev. Moreover, we construct a parallel mask-based counterpart to support a systematic comparison between polar and mask representations. Experimental results show that Poly-DETR is more lightweight in high-resolution scenarios, reducing memory consumption by almost half on Cityscapes dataset. Notably, on PanNuke (cell segmentation) and SpaceNet (building footprints) datasets, Poly-DETR surpasses its mask-based counterpart on all metrics, which validates its advantage on regular-shaped instances in domain-specific settings.
FVG-PT: Adaptive Foreground View-Guided Prompt Tuning for Vision-Language Models
Mar 09, 2026CLIP-based prompt tuning enables pretrained Vision-Language Models (VLMs) to efficiently adapt to downstream tasks. Although existing studies have made significant progress, they pay limited attention to changes in the internal attention representations of VLMs during the tuning process. In this paper, we attribute the failure modes of prompt tuning predictions to shifts in foreground attention of the visual encoder, and propose Foreground View-Guided Prompt Tuning (FVG-PT), an adaptive plug-and-play foreground attention guidance module, to alleviate the shifts. Concretely, FVG-PT introduces a learnable Foreground Reliability Gate to automatically enhance the foreground view quality, applies a Foreground Distillation Compensation module to guide visual attention toward the foreground, and further introduces a Prior Calibration module to mitigate generalization degradation caused by excessive focus on the foreground. Experiments on multiple backbone models and datasets show the effectiveness and compatibility of FVG-PT. Codes are available at: https://github.com/JREion/FVG-PT
AHAP: Reconstructing Arbitrary Humans from Arbitrary Perspectives with Geometric Priors
Feb 27, 2026Reconstructing 3D humans from images captured at multiple perspectives typically requires pre-calibration, like using checkerboards or MVS algorithms, which limits scalability and applicability in diverse real-world scenarios. In this work, we present \textbf{AHAP} (Reconstructing \textbf{A}rbitrary \textbf{H}umans from \textbf{A}rbitrary \textbf{P}erspectives), a feed-forward framework for reconstructing arbitrary humans from arbitrary camera perspectives without requiring camera calibration. Our core lies in the effective fusion of multi-view geometry to assist human association, reconstruction and localization. Specifically, we use a Cross-View Identity Association module through learnable person queries and soft assignment, supervised by contrastive learning to resolve cross-view human identity association. A Human Head fuses cross-view features and scene context for SMPL prediction, guided by cross-view reprojection losses to enforce body pose consistency. Additionally, multi-view geometry eliminates the depth ambiguity inherent in monocular methods, providing more precise 3D human localization through multi-view triangulation. Experiments on EgoHumans and EgoExo4D demonstrate that AHAP achieves competitive performance on both world-space human reconstruction and camera pose estimation, while being 180$\times$ faster than optimization-based approaches.
ViewMask-1-to-3: Multi-View Consistent Image Generation via Multimodal Diffusion Models
Dec 16, 2025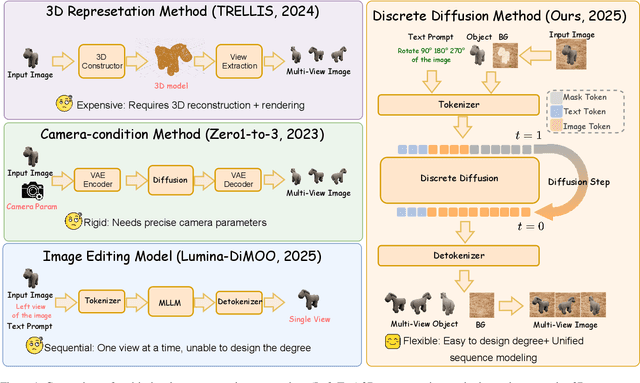
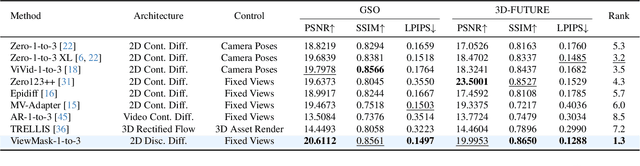
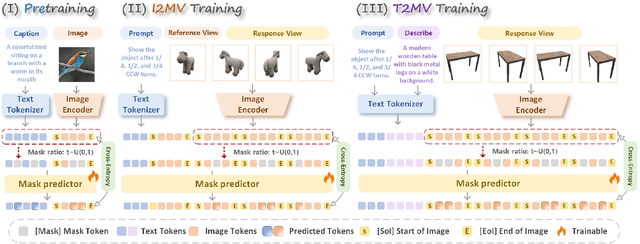
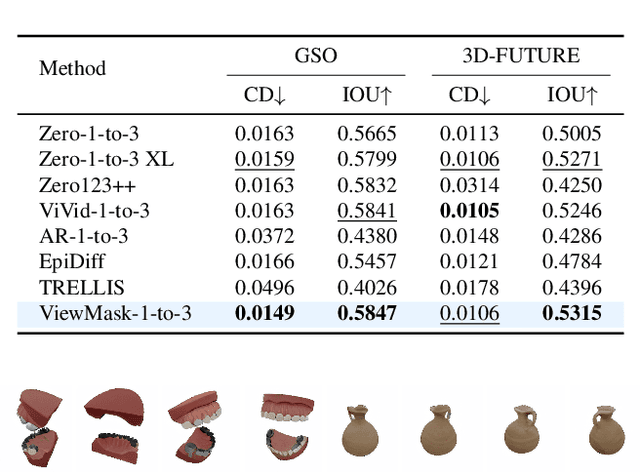
Multi-view image generation from a single image and text description remains challenging due to the difficulty of maintaining geometric consistency across different viewpoints. Existing approaches typically rely on 3D-aware architectures or specialized diffusion models that require extensive multi-view training data and complex geometric priors. In this work, we introduce ViewMask-1-to-3, a pioneering approach to apply discrete diffusion models to multi-view image generation. Unlike continuous diffusion methods that operate in latent spaces, ViewMask-1-to-3 formulates multi-view synthesis as a discrete sequence modeling problem, where each viewpoint is represented as visual tokens obtained through MAGVIT-v2 tokenization. By unifying language and vision through masked token prediction, our approach enables progressive generation of multiple viewpoints through iterative token unmasking with text input. ViewMask-1-to-3 achieves cross-view consistency through simple random masking combined with self-attention, eliminating the requirement for complex 3D geometric constraints or specialized attention architectures. Our approach demonstrates that discrete diffusion provides a viable and simple alternative to existing multi-view generation methods, ranking first on average across GSO and 3D-FUTURE datasets in terms of PSNR, SSIM, and LPIPS, while maintaining architectural simplicity.
Masked Diffusion Models as Energy Minimization
Sep 17, 2025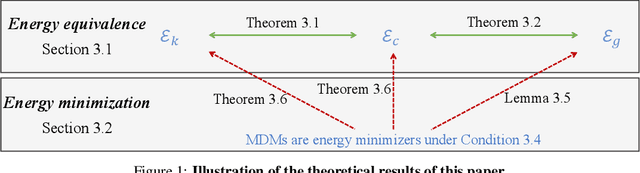
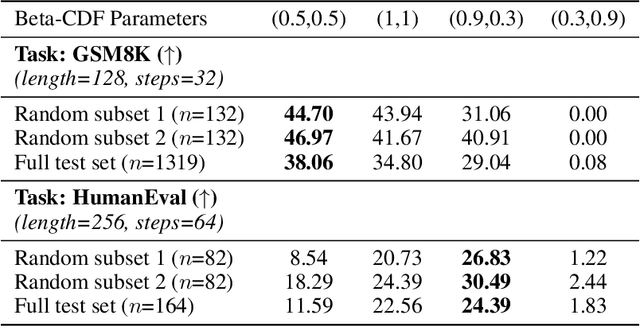
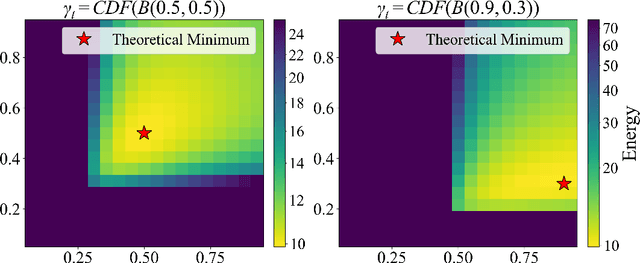
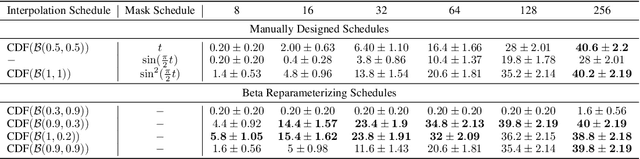
We present a systematic theoretical framework that interprets masked diffusion models (MDMs) as solutions to energy minimization problems in discrete optimal transport. Specifically, we prove that three distinct energy formulations--kinetic, conditional kinetic, and geodesic energy--are mathematically equivalent under the structure of MDMs, and that MDMs minimize all three when the mask schedule satisfies a closed-form optimality condition. This unification not only clarifies the theoretical foundations of MDMs, but also motivates practical improvements in sampling. By parameterizing interpolation schedules via Beta distributions, we reduce the schedule design space to a tractable 2D search, enabling efficient post-training tuning without model modification. Experiments on synthetic and real-world benchmarks demonstrate that our energy-inspired schedules outperform hand-crafted baselines, particularly in low-step sampling settings.
Mathesis: Towards Formal Theorem Proving from Natural Languages
Jun 08, 2025



Recent advances in large language models show strong promise for formal reasoning. However, most LLM-based theorem provers have long been constrained by the need for expert-written formal statements as inputs, limiting their applicability to real-world problems expressed in natural language. We tackle this gap with Mathesis, the first end-to-end theorem proving pipeline processing informal problem statements. It contributes Mathesis-Autoformalizer, the first autoformalizer using reinforcement learning to enhance the formalization ability of natural language problems, aided by our novel LeanScorer framework for nuanced formalization quality assessment. It also proposes a Mathesis-Prover, which generates formal proofs from the formalized statements. To evaluate the real-world applicability of end-to-end formal theorem proving, we introduce Gaokao-Formal, a benchmark of 488 complex problems from China's national college entrance exam. Our approach is carefully designed, with a thorough study of each component. Experiments demonstrate Mathesis's effectiveness, with the autoformalizer outperforming the best baseline by 22% in pass-rate on Gaokao-Formal. The full system surpasses other model combinations, achieving 64% accuracy on MiniF2F with pass@32 and a state-of-the-art 18% on Gaokao-Formal.
FUDOKI: Discrete Flow-based Unified Understanding and Generation via Kinetic-Optimal Velocities
May 26, 2025The rapid progress of large language models (LLMs) has catalyzed the emergence of multimodal large language models (MLLMs) that unify visual understanding and image generation within a single framework. However, most existing MLLMs rely on autoregressive (AR) architectures, which impose inherent limitations on future development, such as the raster-scan order in image generation and restricted reasoning abilities in causal context modeling. In this work, we challenge the dominance of AR-based approaches by introducing FUDOKI, a unified multimodal model purely based on discrete flow matching, as an alternative to conventional AR paradigms. By leveraging metric-induced probability paths with kinetic optimal velocities, our framework goes beyond the previous masking-based corruption process, enabling iterative refinement with self-correction capability and richer bidirectional context integration during generation. To mitigate the high cost of training from scratch, we initialize FUDOKI from pre-trained AR-based MLLMs and adaptively transition to the discrete flow matching paradigm. Experimental results show that FUDOKI achieves performance comparable to state-of-the-art AR-based MLLMs across both visual understanding and image generation tasks, highlighting its potential as a foundation for next-generation unified multimodal models. Furthermore, we show that applying test-time scaling techniques to FUDOKI yields significant performance gains, further underscoring its promise for future enhancement through reinforcement learning.
Variational Autoencoding Discrete Diffusion with Enhanced Dimensional Correlations Modeling
May 23, 2025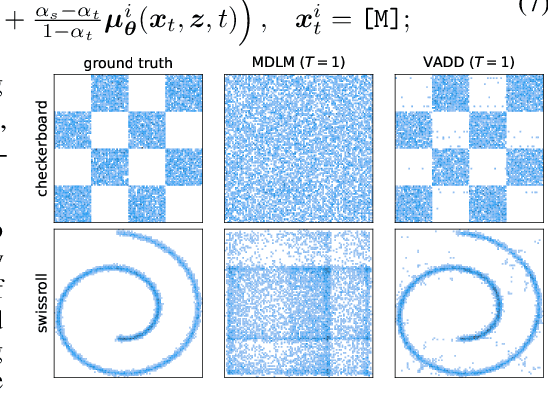
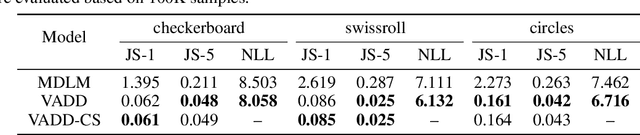
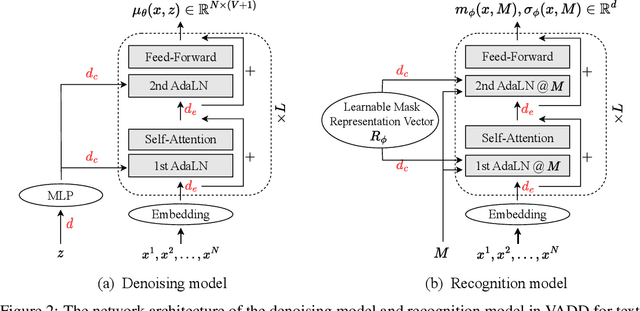

Discrete diffusion models have recently shown great promise for modeling complex discrete data, with masked diffusion models (MDMs) offering a compelling trade-off between quality and generation speed. MDMs denoise by progressively unmasking multiple dimensions from an all-masked input, but their performance can degrade when using few denoising steps due to limited modeling of inter-dimensional dependencies. In this paper, we propose Variational Autoencoding Discrete Diffusion (VADD), a novel framework that enhances discrete diffusion with latent variable modeling to implicitly capture correlations among dimensions. By introducing an auxiliary recognition model, VADD enables stable training via variational lower bounds maximization and amortized inference over the training set. Our approach retains the efficiency of traditional MDMs while significantly improving sample quality, especially when the number of denoising steps is small. Empirical results on 2D toy data, pixel-level image generation, and text generation demonstrate that VADD consistently outperforms MDM baselines.
Learning Few-Step Diffusion Models by Trajectory Distribution Matching
Mar 09, 2025Accelerating diffusion model sampling is crucial for efficient AIGC deployment. While diffusion distillation methods -- based on distribution matching and trajectory matching -- reduce sampling to as few as one step, they fall short on complex tasks like text-to-image generation. Few-step generation offers a better balance between speed and quality, but existing approaches face a persistent trade-off: distribution matching lacks flexibility for multi-step sampling, while trajectory matching often yields suboptimal image quality. To bridge this gap, we propose learning few-step diffusion models by Trajectory Distribution Matching (TDM), a unified distillation paradigm that combines the strengths of distribution and trajectory matching. Our method introduces a data-free score distillation objective, aligning the student's trajectory with the teacher's at the distribution level. Further, we develop a sampling-steps-aware objective that decouples learning targets across different steps, enabling more adjustable sampling. This approach supports both deterministic sampling for superior image quality and flexible multi-step adaptation, achieving state-of-the-art performance with remarkable efficiency. Our model, TDM, outperforms existing methods on various backbones, such as SDXL and PixArt-$\alpha$, delivering superior quality and significantly reduced training costs. In particular, our method distills PixArt-$\alpha$ into a 4-step generator that outperforms its teacher on real user preference at 1024 resolution. This is accomplished with 500 iterations and 2 A800 hours -- a mere 0.01% of the teacher's training cost. In addition, our proposed TDM can be extended to accelerate text-to-video diffusion. Notably, TDM can outperform its teacher model (CogVideoX-2B) by using only 4 NFE on VBench, improving the total score from 80.91 to 81.65. Project page: https://tdm-t2x.github.io/