 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLLM-Searcher: Adapting Diffusion Large Language Model for Search Agents
Feb 03, 2026Recently, Diffusion Large Language Models (dLLMs) have demonstrated unique efficiency advantages, enabled by their inherently parallel decoding mechanism and flexible generation paradigm. Meanwhile, despite the rapid advancement of Search Agents, their practical deployment is constrained by a fundamental limitation, termed as 1) Latency Challenge: the serial execution of multi-round reasoning, tool calling, and tool response waiting under the ReAct agent paradigm induces severe end-to-end latency. Intuitively, dLLMs can leverage their distinctive strengths to optimize the operational efficiency of agents under the ReAct agent paradigm. Practically, existing dLLM backbones face the 2) Agent Ability Challenge. That is, existing dLLMs exhibit remarkably weak reasoning and tool-calling capabilities, preventing these advantages from being effectively realized in practice. In this paper, we propose DLLM-Searcher, an optimization framework for dLLM-based Search Agents. To solve the Agent Ability Challenge, we design a two-stage post-training pipeline encompassing Agentic Supervised Fine-Tuning (Agentic SFT) and Agentic Variance-Reduced Preference Optimization Agentic VRPO, which enhances the backbone dLLM's information seeking and reasoning capabilities. To mitigate the Latency Challenge, we leverage the flexible generation mechanism of dLLMs and propose a novel agent paradigm termed Parallel-Reasoning and Acting P-ReAct. P-ReAct guides the model to prioritize decoding tool_call instructions, thereby allowing the model to keep thinking while waiting for the tool's return. Experimental results demonstrate that DLLM-Searcher achieves performance comparable to mainstream LLM-based search agents and P-ReAct delivers approximately 15% inference acceleration. Our code is available at https://anonymous.4open.science/r/DLLM-Searcher-553C
Effective and Efficient Masked Image Generation Models
Mar 10, 2025Although masked image generation models and masked diffusion models are designed with different motivations and objectives, we observe that they can be unified within a single framework. Building upon this insight, we carefully explore the design space of training and sampling, identifying key factors that contribute to both performance and efficiency. Based on the improvements observed during this exploration, we develop our model, referred to as eMIGM. Empirically, eMIGM demonstrates strong performance on ImageNet generation, as measured by Fr\'echet Inception Distance (FID). In particular, on ImageNet 256x256, with similar number of function evaluations (NFEs) and model parameters, eMIGM outperforms the seminal VAR. Moreover, as NFE and model parameters increase, eMIGM achieves performance comparable to the state-of-the-art continuous diffusion models while requiring less than 40% of the NFE. Additionally, on ImageNet 512x512, with only about 60% of the NFE, eMIGM outperforms the state-of-the-art continuous diffusion models.
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
Jun 06, 2024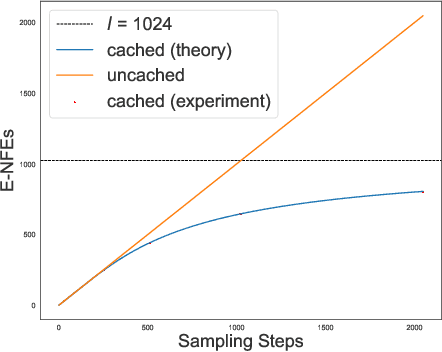
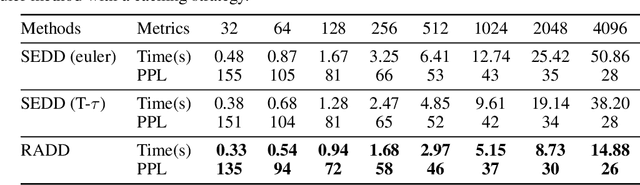
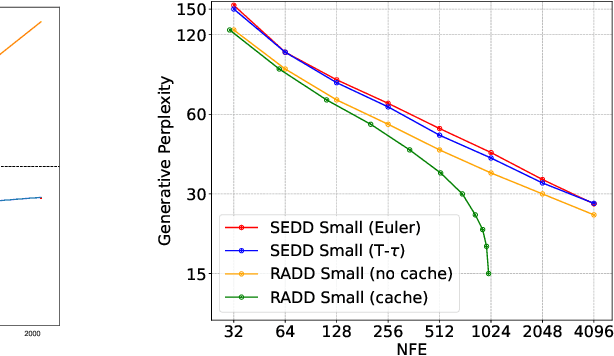
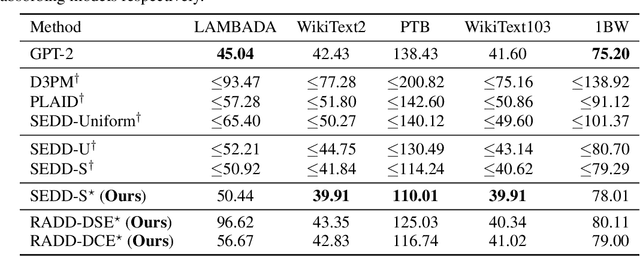
Discrete diffusion models with absorbing processes have shown promise in language modeling. The key quantities to be estimated are the ratios between the marginal probabilities of two transitive states at all timesteps, called the concrete score. In this paper, we reveal that the concrete score in absorbing diffusion can be expressed as conditional probabilities of clean data, multiplied by a time-dependent scalar in an analytic form. Motivated by the finding, we propose reparameterized absorbing discrete diffusion (RADD), a dedicated diffusion model that characterizes the time-independent conditional probabilities. Besides its simplicity, RADD can reduce the number of function evaluations (NFEs) by caching the output of the time-independent network when the noisy sample remains unchanged in a sampling interval. Empirically, RADD is up to 3.5 times faster while consistently achieving a better performance than the strongest baseline. Built upon the new factorization of the concrete score, we further prove a surprising result that the exact likelihood of absorbing diffusion can be rewritten to a simple form (named denoising cross-entropy) and then estimated efficiently by the Monte Carlo method. The resulting approach also applies to the original parameterization of the concrete score. It significantly advances the state-of-the-art discrete diffusion on 5 zero-shot language modeling benchmarks (measured by perplexity) at the GPT-2 scale.