 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanar Symmetric Pattern Generation
Jun 01, 2026Generating objects with specific symmetries is essential in various real-world scenarios. However, adapting existing 2D continuous representations to enforce planar group symmetry remains a challenge, as the transformation of non-reflective group elements may disrupt continuity. To overcome this limitation, we propose a symmetrization framework for arbitrary planar groups. Our method transforms any 2D continuous representation into a symmetric one while preserving continuity. We provide the mathematical formulation of this representation, demonstrate its approximation capability for symmetric functions, and detail the construction methodology. We validate our approach through three visual design tasks (pattern design, paper-cutting design and stylized topology design) and one material design task. Experiments confirm that our representation enables effective symmetry control and demonstrate its broader applicability.
minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models
May 28, 2026Recent video diffusion foundation models have achieved remarkable progress in high-quality video generation, yet turning them into real-time interactive video world models remains challenging. Interactive world models require controllable, causal, and low-latency rollout, which in practice demands a full pipeline spanning data construction, controllable fine-tuning, autoregressive training, few-step distillation, and streaming inference. In this work, we present minWM, a full-stack open-source framework for building real-time interactive video world models. minWM provides an end-to-end pipeline that converts existing bidirectional T2V/TI2V video foundation models into camera-controllable few-step autoregressive world models. Specifically, minWM first fine-tunes a bidirectional video diffusion model with camera control, and then applies the Causal Forcing / Causal Forcing++ pipeline, including AR diffusion training, causal ODE or causal consistency distillation, and asymmetric DMD, to distill it into a few-step autoregressive generator for low-latency rollout. The framework is modular and architecture-extensible: we instantiate it on representative open backbones, including Wan2.1-T2V-1.3B and HY1.5-TI2V-8B, covering both cross-attention-based condition injection and MMDiT-style architectures. minWM also supports adapting existing video world models, such as HY-WorldPlay, to new data distributions, training recipes, and latency targets. Beyond releasing runnable scripts, checkpoints, documentation, and inference code, we provide practical ablations on camera trajectory quality, controllability training steps, and minimal batch-size requirements. We hope minWM serves as a reproducible and extensible recipe for building and adapting real-time interactive video world models. Project Page: [https://github.com/shengshu-ai/minWM](https://github.com/shengshu-ai/minWM)
Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation
May 14, 2026Real-time interactive video generation requires low-latency, streaming, and controllable rollout. Existing autoregressive (AR) diffusion distillation methods have achieved strong results in the chunk-wise 4-step regime by distilling bidirectional base models into few-step AR students, but they remain limited by coarse response granularity and non-negligible sampling latency. In this paper, we study a more aggressive setting: frame-wise autoregression with only 1--2 sampling steps. In this regime, we identify the initialization of a few-step AR student as the key bottleneck: existing strategies are either target-misaligned, incapable of few-step generation, or too costly to scale. We propose \textbf{Causal Forcing++}, a principled and scalable pipeline that uses \emph{causal consistency distillation} (causal CD) for few-step AR initialization. The core idea is that causal CD learns the same AR-conditional flow map as causal ODE distillation, but obtains supervision from a single online teacher ODE step between adjacent timesteps, avoiding the need to precompute and store full PF-ODE trajectories. This makes the initialization both more efficient and easier to optimize. The resulting pipeline, \ours, surpasses the SOTA 4-step chunk-wise Causal Forcing under the \textit{\textbf{frame-wise 2-step setting}} by 0.1 in VBench Total, 0.3 in VBench Quality, and 0.335 in VisionReward, while reducing first-frame latency by 50\% and Stage 2 training cost by $\sim$$4\times$. We further extend the pipeline to action-conditioned world model generation in the spirit of Genie3. Project Page: https://github.com/thu-ml/Causal-Forcing and https://github.com/shengshu-ai/minWM .
LLaDA-o: An Effective and Length-Adaptive Omni Diffusion Model
Mar 01, 2026We present \textbf{LLaDA-o}, an effective and length-adaptive omni diffusion model for multimodal understanding and generation. LLaDA-o is built on a Mixture of Diffusion (MoD) framework that decouples discrete masked diffusion for text understanding and continuous diffusion for visual generation, while coupling them through a shared, simple, and efficient attention backbone that reduces redundant computation for fixed conditions. Building on MoD, we further introduce a data-centric length adaptation strategy that enables flexible-length decoding in multimodal settings without architectural changes. Extensive experiments show that LLaDA-o achieves state-of-the-art performance among omni-diffusion models on multimodal understanding and generation benchmarks, and reaches 87.04 on DPG-Bench for text-to-image generation, supporting the effectiveness of unified omni diffusion modeling. Code is available at https://github.com/ML-GSAI/LLaDA-o.
Spectral Condition for $μ$P under Width-Depth Scaling
Feb 28, 2026Generative foundation models are increasingly scaled in both width and depth, posing significant challenges for stable feature learning and reliable hyperparameter (HP) transfer across model sizes. While maximal update parameterization ($μ$P) has provided a principled solution to both problems for width scaling, existing extensions to the joint width-depth scaling regime remain fragmented, architecture- and optimizer-specific, and often rely on technically involved theories. In this work, we develop a simple and unified spectral framework for $μ$P under joint width-depth scaling. Considering residual networks of varying block depths, we first introduce a spectral $μ$P condition that precisely characterizes how the norms of weights and their per-step updates should scale with width and depth, unifying previously disparate $μ$P formulations as special cases. Building on this condition, we then derive a general recipe for implementing $μ$P across a broad class of optimizers by mapping the spectral constraints to concrete HP parameterizations. This approach not only recovers existing $μ$P formulations (e.g., for SGD and AdamW) but also naturally extends to a wider range of optimizers. Finally, experiments on GPT-2 style language models demonstrate that the proposed spectral $μ$P condition preserves stable feature learning and enables robust HP transfer under width-depth scaling.
DLLM-Searcher: Adapting Diffusion Large Language Model for Search Agents
Feb 03, 2026Recently, Diffusion Large Language Models (dLLMs) have demonstrated unique efficiency advantages, enabled by their inherently parallel decoding mechanism and flexible generation paradigm. Meanwhile, despite the rapid advancement of Search Agents, their practical deployment is constrained by a fundamental limitation, termed as 1) Latency Challenge: the serial execution of multi-round reasoning, tool calling, and tool response waiting under the ReAct agent paradigm induces severe end-to-end latency. Intuitively, dLLMs can leverage their distinctive strengths to optimize the operational efficiency of agents under the ReAct agent paradigm. Practically, existing dLLM backbones face the 2) Agent Ability Challenge. That is, existing dLLMs exhibit remarkably weak reasoning and tool-calling capabilities, preventing these advantages from being effectively realized in practice. In this paper, we propose DLLM-Searcher, an optimization framework for dLLM-based Search Agents. To solve the Agent Ability Challenge, we design a two-stage post-training pipeline encompassing Agentic Supervised Fine-Tuning (Agentic SFT) and Agentic Variance-Reduced Preference Optimization Agentic VRPO, which enhances the backbone dLLM's information seeking and reasoning capabilities. To mitigate the Latency Challenge, we leverage the flexible generation mechanism of dLLMs and propose a novel agent paradigm termed Parallel-Reasoning and Acting P-ReAct. P-ReAct guides the model to prioritize decoding tool_call instructions, thereby allowing the model to keep thinking while waiting for the tool's return. Experimental results demonstrate that DLLM-Searcher achieves performance comparable to mainstream LLM-based search agents and P-ReAct delivers approximately 15% inference acceleration. Our code is available at https://anonymous.4open.science/r/DLLM-Searcher-553C
Optimization and Generation in Aerodynamics Inverse Design
Feb 03, 2026Inverse design with physics-based objectives is challenging because it couples high-dimensional geometry with expensive simulations, as exemplified by aerodynamic shape optimization for drag reduction. We revisit inverse design through two canonical solutions, the optimal design point and the optimal design distribution, and relate them to optimization and guided generation. Building on this view, we propose a new training loss for cost predictors and a density-gradient optimization method that improves objectives while preserving plausible shapes. We further unify existing training-free guided generation methods. To address their inability to approximate conditional covariance in high dimensions, we develop a time- and memory-efficient algorithm for approximate covariance estimation. Experiments on a controlled 2D study and high-fidelity 3D aerodynamic benchmarks (car and aircraft), validated by OpenFOAM simulations and miniature wind-tunnel tests with 3D-printed prototypes, demonstrate consistent gains in both optimization and guided generation. Additional offline RL results further support the generality of our approach.
Causal Forcing: Autoregressive Diffusion Distillation Done Right for High-Quality Real-Time Interactive Video Generation
Feb 02, 2026To achieve real-time interactive video generation, current methods distill pretrained bidirectional video diffusion models into few-step autoregressive (AR) models, facing an architectural gap when full attention is replaced by causal attention. However, existing approaches do not bridge this gap theoretically. They initialize the AR student via ODE distillation, which requires frame-level injectivity, where each noisy frame must map to a unique clean frame under the PF-ODE of an AR teacher. Distilling an AR student from a bidirectional teacher violates this condition, preventing recovery of the teacher's flow map and instead inducing a conditional-expectation solution, which degrades performance. To address this issue, we propose Causal Forcing that uses an AR teacher for ODE initialization, thereby bridging the architectural gap. Empirical results show that our method outperforms all baselines across all metrics, surpassing the SOTA Self Forcing by 19.3\% in Dynamic Degree, 8.7\% in VisionReward, and 16.7\% in Instruction Following. Project page and the code: \href{https://thu-ml.github.io/CausalForcing.github.io/}{https://thu-ml.github.io/CausalForcing.github.io/}
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
ReFusion: A Diffusion Large Language Model with Parallel Autoregressive Decoding
Dec 15, 2025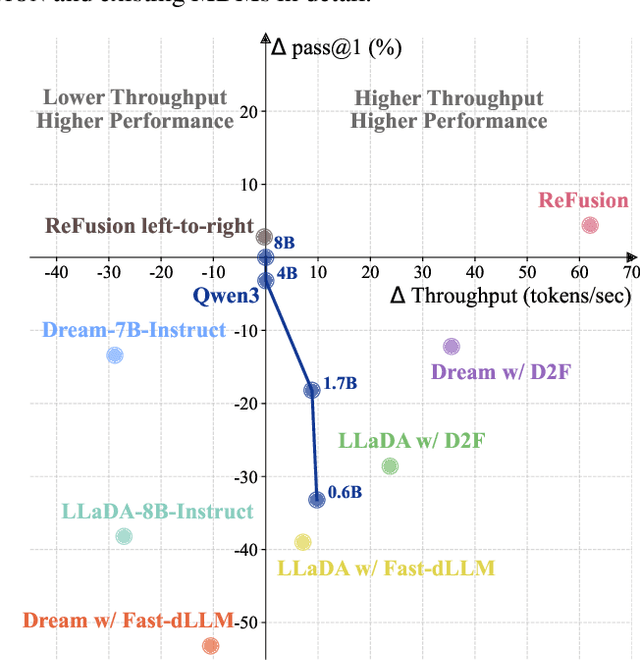
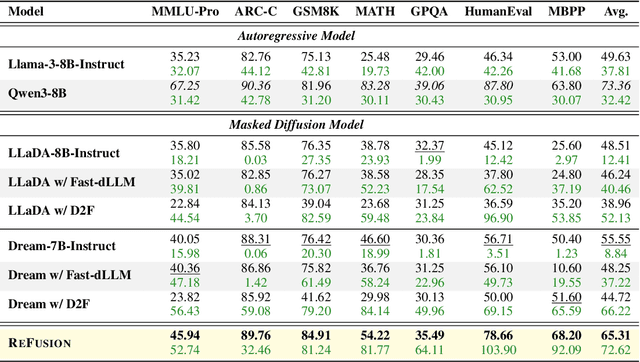
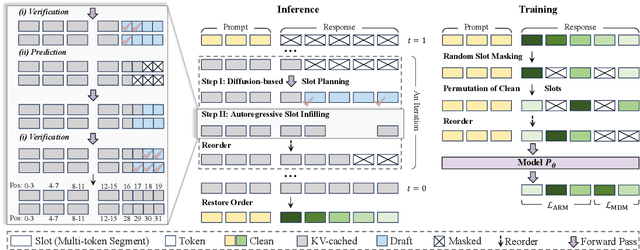
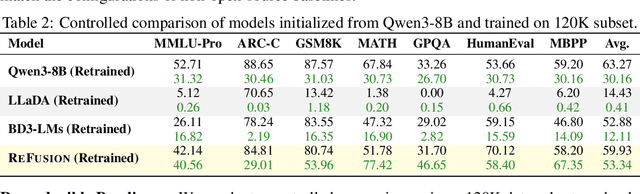
Autoregressive models (ARMs) are hindered by slow sequential inference. While masked diffusion models (MDMs) offer a parallel alternative, they suffer from critical drawbacks: high computational overhead from precluding Key-Value (KV) caching, and incoherent generation arising from learning dependencies over an intractable space of token combinations. To address these limitations, we introduce ReFusion, a novel masked diffusion model that achieves superior performance and efficiency by elevating parallel decoding from the token level to a higher slot level, where each slot is a fixed-length, contiguous sub-sequence. This is achieved through an iterative ``plan-and-infill'' decoding process: a diffusion-based planning step first identifies a set of weakly dependent slots, and an autoregressive infilling step then decodes these selected slots in parallel. The slot-based design simultaneously unlocks full KV cache reuse with a unified causal framework and reduces the learning complexity from the token combination space to a manageable slot-level permutation space. Extensive experiments on seven diverse benchmarks show that ReFusion not only overwhelmingly surpasses prior MDMs with 34% performance gains and an over 18$\times$ speedup on average, but also bridges the performance gap to strong ARMs while maintaining a 2.33$\times$ average speedup.