 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Personalization Misleads: Understanding and Mitigating Hallucinations in Personalized LLMs
Jan 16, 2026Personalized large language models (LLMs) adapt model behavior to individual users to enhance user satisfaction, yet personalization can inadvertently distort factual reasoning. We show that when personalized LLMs face factual queries, there exists a phenomenon where the model generates answers aligned with a user's prior history rather than the objective truth, resulting in personalization-induced hallucinations that degrade factual reliability and may propagate incorrect beliefs, due to representational entanglement between personalization and factual representations. To address this issue, we propose Factuality-Preserving Personalized Steering (FPPS), a lightweight inference-time approach that mitigates personalization-induced factual distortions while preserving personalized behavior. We further introduce PFQABench, the first benchmark designed to jointly evaluate factual and personalized question answering under personalization. Experiments across multiple LLM backbones and personalization methods show that FPPS substantially improves factual accuracy while maintaining personalized performance.
LLaDA-Rec: Discrete Diffusion for Parallel Semantic ID Generation in Generative Recommendation
Nov 09, 2025Generative recommendation represents each item as a semantic ID, i.e., a sequence of discrete tokens, and generates the next item through autoregressive decoding. While effective, existing autoregressive models face two intrinsic limitations: (1) unidirectional constraints, where causal attention restricts each token to attend only to its predecessors, hindering global semantic modeling; and (2) error accumulation, where the fixed left-to-right generation order causes prediction errors in early tokens to propagate to the predictions of subsequent token. To address these issues, we propose LLaDA-Rec, a discrete diffusion framework that reformulates recommendation as parallel semantic ID generation. By combining bidirectional attention with the adaptive generation order, the approach models inter-item and intra-item dependencies more effectively and alleviates error accumulation. Specifically, our approach comprises three key designs: (1) a parallel tokenization scheme that produces semantic IDs for bidirectional modeling, addressing the mismatch between residual quantization and bidirectional architectures; (2) two masking mechanisms at the user-history and next-item levels to capture both inter-item sequential dependencies and intra-item semantic relationships; and (3) an adapted beam search strategy for adaptive-order discrete diffusion decoding, resolving the incompatibility of standard beam search with diffusion-based generation. Experiments on three real-world datasets show that LLaDA-Rec consistently outperforms both ID-based and state-of-the-art generative recommenders, establishing discrete diffusion as a new paradigm for generative recommendation.
StyliTruth : Unlocking Stylized yet Truthful LLM Generation via Disentangled Steering
Aug 06, 2025Generating stylized large language model (LLM) responses via representation editing is a promising way for fine-grained output control. However, there exists an inherent trade-off: imposing a distinctive style often degrades truthfulness. Existing representation editing methods, by naively injecting style signals, overlook this collateral impact and frequently contaminate the model's core truthfulness representations, resulting in reduced answer correctness. We term this phenomenon stylization-induced truthfulness collapse. We attribute this issue to latent coupling between style and truth directions in certain key attention heads, and propose StyliTruth, a mechanism that preserves stylization while keeping truthfulness intact. StyliTruth separates the style-relevant and truth-relevant subspaces in the model's representation space via an orthogonal deflation process. This decomposition enables independent control of style and truth in their own subspaces, minimizing interference. By designing adaptive, token-level steering vectors within each subspace, we dynamically and precisely control the generation process to maintain both stylistic fidelity and truthfulness. We validate our method on multiple styles and languages. Extensive experiments and analyses show that StyliTruth significantly reduces stylization-induced truthfulness collapse and outperforms existing inference-time intervention methods in balancing style adherence with truthfulness.
Similarity = Value? Consultation Value Assessment and Alignment for Personalized Search
Jun 17, 2025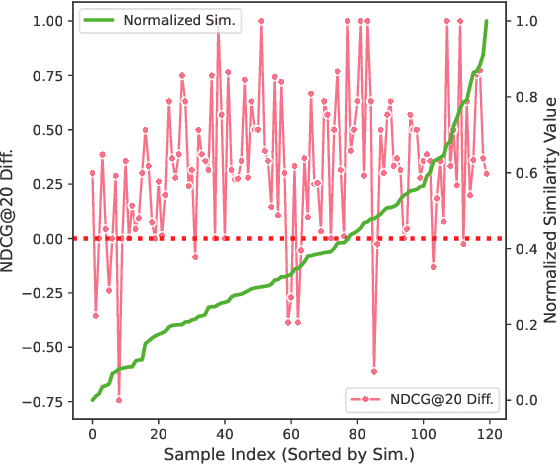
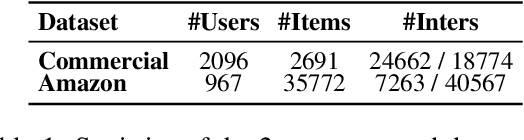

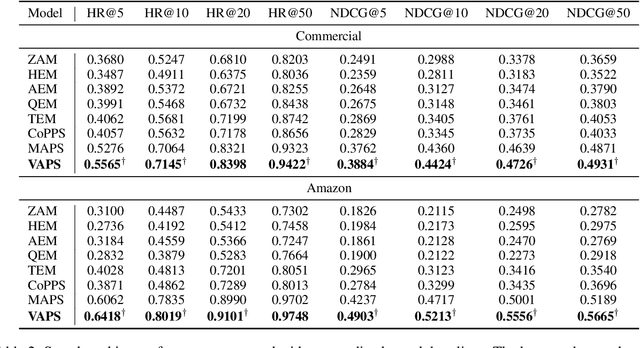
Personalized search systems in e-commerce platforms increasingly involve user interactions with AI assistants, where users consult about products, usage scenarios, and more. Leveraging consultation to personalize search services is trending. Existing methods typically rely on semantic similarity to align historical consultations with current queries due to the absence of 'value' labels, but we observe that semantic similarity alone often fails to capture the true value of consultation for personalization. To address this, we propose a consultation value assessment framework that evaluates historical consultations from three novel perspectives: (1) Scenario Scope Value, (2) Posterior Action Value, and (3) Time Decay Value. Based on this, we introduce VAPS, a value-aware personalized search model that selectively incorporates high-value consultations through a consultation-user action interaction module and an explicit objective that aligns consultations with user actions. Experiments on both public and commercial datasets show that VAPS consistently outperforms baselines in both retrieval and ranking tasks.
MAPS: Motivation-Aware Personalized Search via LLM-Driven Consultation Alignment
Mar 05, 2025Personalized product search aims to retrieve and rank items that match users' preferences and search intent. Despite their effectiveness, existing approaches typically assume that users' query fully captures their real motivation. However, our analysis of a real-world e-commerce platform reveals that users often engage in relevant consultations before searching, indicating they refine intents through consultations based on motivation and need. The implied motivation in consultations is a key enhancing factor for personalized search. This unexplored area comes with new challenges including aligning contextual motivations with concise queries, bridging the category-text gap, and filtering noise within sequence history. To address these, we propose a Motivation-Aware Personalized Search (MAPS) method. It embeds queries and consultations into a unified semantic space via LLMs, utilizes a Mixture of Attention Experts (MoAE) to prioritize critical semantics, and introduces dual alignment: (1) contrastive learning aligns consultations, reviews, and product features; (2) bidirectional attention integrates motivation-aware embeddings with user preferences. Extensive experiments on real and synthetic data show MAPS outperforms existing methods in both retrieval and ranking tasks.
Generating Model Parameters for Controlling: Parameter Diffusion for Controllable Multi-Task Recommendation
Oct 14, 2024



Commercial recommender systems face the challenge that task requirements from platforms or users often change dynamically (e.g., varying preferences for accuracy or diversity). Ideally, the model should be re-trained after resetting a new objective function, adapting to these changes in task requirements. However, in practice, the high computational costs associated with retraining make this process impractical for models already deployed to online environments. This raises a new challenging problem: how to efficiently adapt the learning model to different task requirements by controlling model parameters after deployment, without the need for retraining. To address this issue, we propose a novel controllable learning approach via Parameter Diffusion for controllable multi-task Recommendation (PaDiRec), which allows the customization and adaptation of recommendation model parameters to new task requirements without retraining. Specifically, we first obtain the optimized model parameters through adapter tunning based on the feasible task requirements. Then, we utilize the diffusion model as a parameter generator, employing classifier-free guidance in conditional training to learn the distribution of optimized model parameters under various task requirements. Finally, the diffusion model is applied to effectively generate model parameters in a test-time adaptation manner given task requirements. As a model-agnostic approach, PaDiRec can leverage existing recommendation models as backbones to enhance their controllability. Extensive experiments on public datasets and a dataset from a commercial app, indicate that PaDiRec can effectively enhance controllability through efficient model parameter generation. The code is released at https://anonymous.4open.science/r/PaDiRec-DD13.
Enhancing Sequential Recommendations through Multi-Perspective Reflections and Iteration
Sep 10, 2024


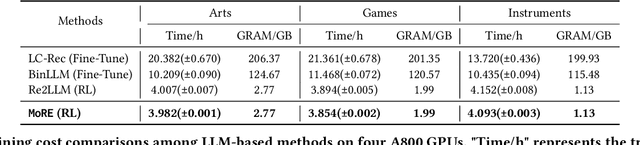
Sequence recommendation (SeqRec) aims to predict the next item a user will interact with by understanding user intentions and leveraging collaborative filtering information. Large language models (LLMs) have shown great promise in recommendation tasks through prompt-based, fixed reflection libraries, and fine-tuning techniques. However, these methods face challenges, including lack of supervision, inability to optimize reflection sources, inflexibility to diverse user needs, and high computational costs. Despite promising results, current studies primarily focus on reflections of users' explicit preferences (e.g., item titles) while neglecting implicit preferences (e.g., brands) and collaborative filtering information. This oversight hinders the capture of preference shifts and dynamic user behaviors. Additionally, existing approaches lack mechanisms for reflection evaluation and iteration, often leading to suboptimal recommendations. To address these issues, we propose the Mixture of REflectors (MoRE) framework, designed to model and learn dynamic user preferences in SeqRec. Specifically, MoRE introduces three reflectors for generating LLM-based reflections on explicit preferences, implicit preferences, and collaborative signals. Each reflector incorporates a self-improving strategy, termed refining-and-iteration, to evaluate and iteratively update reflections. Furthermore, a meta-reflector employs a contextual bandit algorithm to select the most suitable expert and corresponding reflections for each user's recommendation, effectively capturing dynamic preferences. Extensive experiments on three real-world datasets demonstrate that MoRE consistently outperforms state-of-the-art methods, requiring less training time and GPU memory compared to other LLM-based approaches in SeqRec.
A Survey of Controllable Learning: Methods and Applications in Information Retrieval
Jul 04, 2024


Controllable learning (CL) emerges as a critical component in trustworthy machine learning, ensuring that learners meet predefined targets and can adaptively adjust without retraining according to the changes in those targets. We provide a formal definition of CL, and discuss its applications in information retrieval (IR) where information needs are often complex and dynamic. The survey categorizes CL according to who controls (users or platforms), what is controllable (e.g., retrieval objectives, users' historical behaviors, controllable environmental adaptation), how control is implemented (e.g., rule-based method, Pareto optimization, Hypernetwork), and where to implement control (e.g.,pre-processing, in-processing, post-processing methods). Then, we identify challenges faced by CL across training, evaluation, task setting, and deployment in online environments. Additionally, we outline promising directions for CL in theoretical analysis, efficient computation, empowering large language models, application scenarios and evaluation frameworks in IR.
On the Decision-Making Abilities in Role-Playing using Large Language Models
Feb 29, 2024



Large language models (LLMs) are now increasingly utilized for role-playing tasks, especially in impersonating domain-specific experts, primarily through role-playing prompts. When interacting in real-world scenarios, the decision-making abilities of a role significantly shape its behavioral patterns. In this paper, we concentrate on evaluating the decision-making abilities of LLMs post role-playing thereby validating the efficacy of role-playing. Our goal is to provide metrics and guidance for enhancing the decision-making abilities of LLMs in role-playing tasks. Specifically, we first use LLMs to generate virtual role descriptions corresponding to the 16 personality types of Myers-Briggs Type Indicator (abbreviated as MBTI) representing a segmentation of the population. Then we design specific quantitative operations to evaluate the decision-making abilities of LLMs post role-playing from four aspects: adaptability, exploration$\&$exploitation trade-off ability, reasoning ability, and safety. Finally, we analyze the association between the performance of decision-making and the corresponding MBTI types through GPT-4. Extensive experiments demonstrate stable differences in the four aspects of decision-making abilities across distinct roles, signifying a robust correlation between decision-making abilities and the roles emulated by LLMs. These results underscore that LLMs can effectively impersonate varied roles while embodying their genuine sociological characteristics.
HyperBandit: Contextual Bandit with Hypernewtork for Time-Varying User Preferences in Streaming Recommendation
Aug 14, 2023


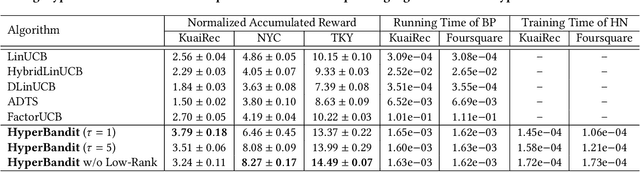
In real-world streaming recommender systems, user preferences often dynamically change over time (e.g., a user may have different preferences during weekdays and weekends). Existing bandit-based streaming recommendation models only consider time as a timestamp, without explicitly modeling the relationship between time variables and time-varying user preferences. This leads to recommendation models that cannot quickly adapt to dynamic scenarios. To address this issue, we propose a contextual bandit approach using hypernetwork, called HyperBandit, which takes time features as input and dynamically adjusts the recommendation model for time-varying user preferences. Specifically, HyperBandit maintains a neural network capable of generating the parameters for estimating time-varying rewards, taking into account the correlation between time features and user preferences. Using the estimated time-varying rewards, a bandit policy is employed to make online recommendations by learning the latent item contexts. To meet the real-time requirements in streaming recommendation scenarios, we have verified the existence of a low-rank structure in the parameter matrix and utilize low-rank factorization for efficient training. Theoretically, we demonstrate a sublinear regret upper bound against the best policy. Extensive experiments on real-world datasets show that the proposed HyperBandit consistently outperforms the state-of-the-art baselines in terms of accumulated rewards.