 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLemon Agent Technical Report
Feb 06, 2026Recent advanced LLM-powered agent systems have exhibited their remarkable capabilities in tackling complex, long-horizon tasks. Nevertheless, they still suffer from inherent limitations in resource efficiency, context management, and multimodal perception. Based on these observations, Lemon Agent is introduced, a multi-agent orchestrator-worker system built on a newly proposed AgentCortex framework, which formalizes the classic Planner-Executor-Memory paradigm through an adaptive task execution mechanism. Our system integrates a hierarchical self-adaptive scheduling mechanism that operates at both the overall orchestrator layer and workers layer. This mechanism can dynamically adjust computational intensity based on task complexity. It enables orchestrator to allocate one or more workers for parallel subtask execution, while workers can further improve operational efficiency by invoking tools concurrently. By virtue of this two-tier architecture, the system achieves synergistic balance between global task coordination and local task execution, thereby optimizing resource utilization and task processing efficiency in complex scenarios. To reduce context redundancy and increase information density during parallel steps, we adopt a three-tier progressive context management strategy. To make fuller use of historical information, we propose a self-evolving memory system, which can extract multi-dimensional valid information from all historical experiences to assist in completing similar tasks. Furthermore, we provide an enhanced MCP toolset. Empirical evaluations on authoritative benchmarks demonstrate that our Lemon Agent can achieve a state-of-the-art 91.36% overall accuracy on GAIA and secures the top position on the xbench-DeepSearch leaderboard with a score of 77+.
Discovering autonomous quantum error correction via deep reinforcement learning
Nov 16, 2025Quantum error correction is essential for fault-tolerant quantum computing. However, standard methods relying on active measurements may introduce additional errors. Autonomous quantum error correction (AQEC) circumvents this by utilizing engineered dissipation and drives in bosonic systems, but identifying practical encoding remains challenging due to stringent Knill-Laflamme conditions. In this work, we utilize curriculum learning enabled deep reinforcement learning to discover Bosonic codes under approximate AQEC framework to resist both single-photon and double-photon losses. We present an analytical solution of solving the master equation under approximation conditions, which can significantly accelerate the training process of reinforcement learning. The agent first identifies an encoded subspace surpassing the breakeven point through rapid exploration within a constrained evolutionary time-frame, then strategically fine-tunes its policy to sustain this performance advantage over extended temporal horizons. We find that the two-phase trained agent can discover the optimal set of codewords, i.e., the Fock states $\ket{4}$ and $\ket{7}$ considering the effect of both single-photon and double-photon loss. We identify that the discovered code surpasses the breakeven threshold over a longer evolution time and achieve the state-of-art performance. We also analyze the robustness of the code against the phase damping and amplitude damping noise. Our work highlights the potential of curriculum learning enabled deep reinforcement learning in discovering the optimal quantum error correct code especially in early fault-tolerant quantum systems.
ReInAgent: A Context-Aware GUI Agent Enabling Human-in-the-Loop Mobile Task Navigation
Oct 09, 2025



Mobile GUI agents exhibit substantial potential to facilitate and automate the execution of user tasks on mobile phones. However, exist mobile GUI agents predominantly privilege autonomous operation and neglect the necessity of active user engagement during task execution. This omission undermines their adaptability to information dilemmas including ambiguous, dynamically evolving, and conflicting task scenarios, leading to execution outcomes that deviate from genuine user requirements and preferences. To address these shortcomings, we propose ReInAgent, a context-aware multi-agent framework that leverages dynamic information management to enable human-in-the-loop mobile task navigation. ReInAgent integrates three specialized agents around a shared memory module: an information-managing agent for slot-based information management and proactive interaction with the user, a decision-making agent for conflict-aware planning, and a reflecting agent for task reflection and information consistency validation. Through continuous contextual information analysis and sustained user-agent collaboration, ReInAgent overcomes the limitation of existing approaches that rely on clear and static task assumptions. Consequently, it enables more adaptive and reliable mobile task navigation in complex, real-world scenarios. Experimental results demonstrate that ReInAgent effectively resolves information dilemmas and produces outcomes that are more closely aligned with genuine user preferences. Notably, on complex tasks involving information dilemmas, ReInAgent achieves a 25% higher success rate than Mobile-Agent-v2.
Bridging Search and Recommendation through Latent Cross Reasoning
Aug 06, 2025Search and recommendation (S&R) are fundamental components of modern online platforms, yet effectively leveraging search behaviors to improve recommendation remains a challenging problem. User search histories often contain noisy or irrelevant signals that can even degrade recommendation performance, while existing approaches typically encode S&R histories either jointly or separately without explicitly identifying which search behaviors are truly useful. Inspired by the human decision-making process, where one first identifies recommendation intent and then reasons about relevant evidence, we design a latent cross reasoning framework that first encodes user S&R histories to capture global interests and then iteratively reasons over search behaviors to extract signals beneficial for recommendation. Contrastive learning is employed to align latent reasoning states with target items, and reinforcement learning is further introduced to directly optimize ranking performance. Extensive experiments on public benchmarks demonstrate consistent improvements over strong baselines, validating the importance of reasoning in enhancing search-aware recommendation.
Benefit from Rich: Tackling Search Interaction Sparsity in Search Enhanced Recommendation
Aug 06, 2025In modern online platforms, search and recommendation (S&R) often coexist, offering opportunities for performance improvement through search-enhanced approaches. Existing studies show that incorporating search signals boosts recommendation performance. However, the effectiveness of these methods relies heavily on rich search interactions. They primarily benefit a small subset of users with abundant search behavior, while offering limited improvements for the majority of users who exhibit only sparse search activity. To address the problem of sparse search data in search-enhanced recommendation, we face two key challenges: (1) how to learn useful search features for users with sparse search interactions, and (2) how to design effective training objectives under sparse conditions. Our idea is to leverage the features of users with rich search interactions to enhance those of users with sparse search interactions. Based on this idea, we propose GSERec, a method that utilizes message passing on the User-Code Graphs to alleviate data sparsity in Search-Enhanced Recommendation. Specifically, we utilize Large Language Models (LLMs) with vector quantization to generate discrete codes, which connect similar users and thereby construct the graph. Through message passing on this graph, embeddings of users with rich search data are propagated to enhance the embeddings of users with sparse interactions. To further ensure that the message passing captures meaningful information from truly similar users, we introduce a contrastive loss to better model user similarities. The enhanced user representations are then integrated into downstream search-enhanced recommendation models. Experiments on three real-world datasets show that GSERec consistently outperforms baselines, especially for users with sparse search behaviors.
Similarity = Value? Consultation Value Assessment and Alignment for Personalized Search
Jun 17, 2025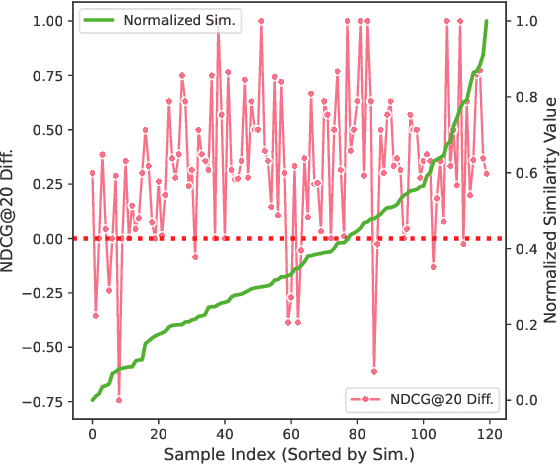
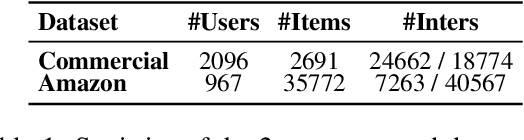

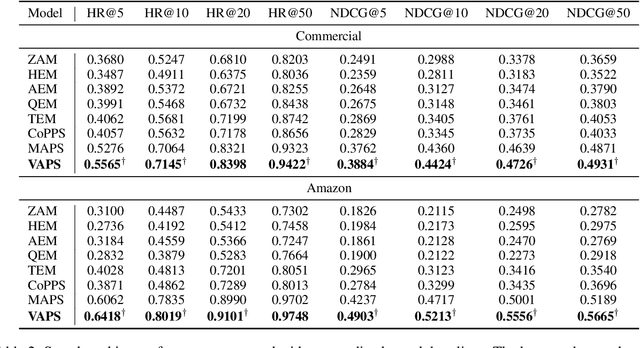
Personalized search systems in e-commerce platforms increasingly involve user interactions with AI assistants, where users consult about products, usage scenarios, and more. Leveraging consultation to personalize search services is trending. Existing methods typically rely on semantic similarity to align historical consultations with current queries due to the absence of 'value' labels, but we observe that semantic similarity alone often fails to capture the true value of consultation for personalization. To address this, we propose a consultation value assessment framework that evaluates historical consultations from three novel perspectives: (1) Scenario Scope Value, (2) Posterior Action Value, and (3) Time Decay Value. Based on this, we introduce VAPS, a value-aware personalized search model that selectively incorporates high-value consultations through a consultation-user action interaction module and an explicit objective that aligns consultations with user actions. Experiments on both public and commercial datasets show that VAPS consistently outperforms baselines in both retrieval and ranking tasks.
A Multi-Dimensional Constraint Framework for Evaluating and Improving Instruction Following in Large Language Models
May 12, 2025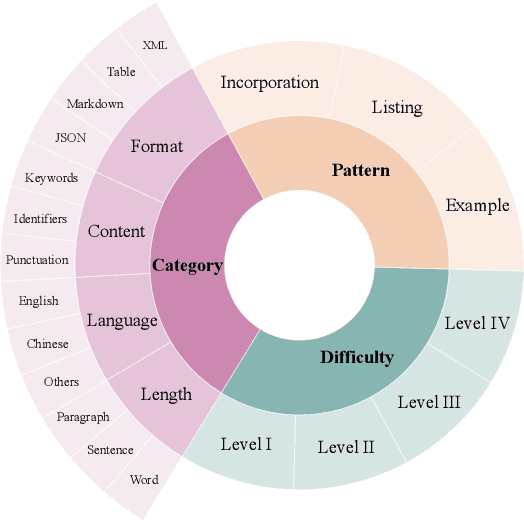

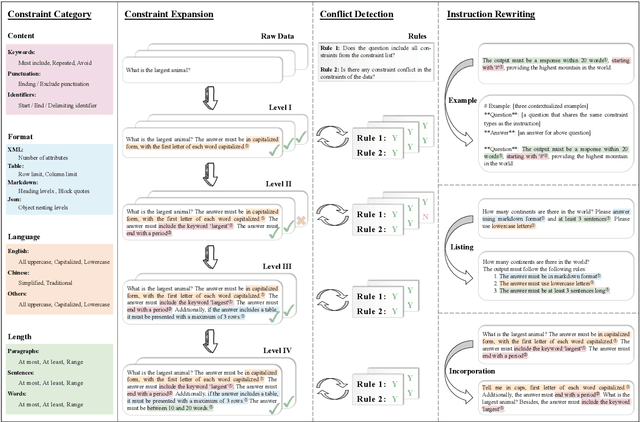
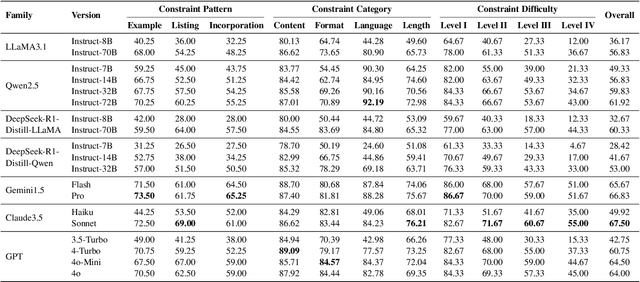
Instruction following evaluates large language models (LLMs) on their ability to generate outputs that adhere to user-defined constraints. However, existing benchmarks often rely on templated constraint prompts, which lack the diversity of real-world usage and limit fine-grained performance assessment. To fill this gap, we propose a multi-dimensional constraint framework encompassing three constraint patterns, four constraint categories, and four difficulty levels. Building on this framework, we develop an automated instruction generation pipeline that performs constraint expansion, conflict detection, and instruction rewriting, yielding 1,200 code-verifiable instruction-following test samples. We evaluate 19 LLMs across seven model families and uncover substantial variation in performance across constraint forms. For instance, average performance drops from 77.67% at Level I to 32.96% at Level IV. Furthermore, we demonstrate the utility of our approach by using it to generate data for reinforcement learning, achieving substantial gains in instruction following without degrading general performance. In-depth analysis indicates that these gains stem primarily from modifications in the model's attention modules parameters, which enhance constraint recognition and adherence. Code and data are available in https://github.com/Junjie-Ye/MulDimIF.
Decoding Recommendation Behaviors of In-Context Learning LLMs Through Gradient Descent
Apr 06, 2025Recently, there has been a growing trend in utilizing large language models (LLMs) for recommender systems, referred to as LLMRec. A notable approach within this trend is not to fine-tune these models directly but instead to leverage In-Context Learning (ICL) methods tailored for LLMRec, denoted as LLM-ICL Rec. Many contemporary techniques focus on harnessing ICL content to enhance LLMRec performance. However, optimizing LLMRec with ICL content presents unresolved challenges. Specifically, two key issues stand out: (1) the limited understanding of why using a few demonstrations without model fine-tuning can lead to better performance compared to zero-shot recommendations. (2) the lack of evaluation metrics for demonstrations in LLM-ICL Rec and the absence of the theoretical analysis and practical design for optimizing the generation of ICL content for recommendation contexts. To address these two main issues, we propose a theoretical model, the LLM-ICL Recommendation Equivalent Gradient Descent model (LRGD) in this paper, which connects recommendation generation with gradient descent dynamics. We demonstrate that the ICL inference process in LLM aligns with the training procedure of its dual model, producing token predictions equivalent to the dual model's testing outputs. Building on these theoretical insights, we propose an evaluation metric for assessing demonstration quality. We integrate perturbations and regularizations in LRGD to enhance the robustness of the recommender system. To further improve demonstration effectiveness, prevent performance collapse, and ensure long-term adaptability, we also propose a two-stage optimization process in practice. Extensive experiments and detailed analysis on three Amazon datasets validate the theoretical equivalence and support the effectiveness of our theoretical analysis and practical module design.
MAPS: Motivation-Aware Personalized Search via LLM-Driven Consultation Alignment
Mar 05, 2025Personalized product search aims to retrieve and rank items that match users' preferences and search intent. Despite their effectiveness, existing approaches typically assume that users' query fully captures their real motivation. However, our analysis of a real-world e-commerce platform reveals that users often engage in relevant consultations before searching, indicating they refine intents through consultations based on motivation and need. The implied motivation in consultations is a key enhancing factor for personalized search. This unexplored area comes with new challenges including aligning contextual motivations with concise queries, bridging the category-text gap, and filtering noise within sequence history. To address these, we propose a Motivation-Aware Personalized Search (MAPS) method. It embeds queries and consultations into a unified semantic space via LLMs, utilizes a Mixture of Attention Experts (MoAE) to prioritize critical semantics, and introduces dual alignment: (1) contrastive learning aligns consultations, reviews, and product features; (2) bidirectional attention integrates motivation-aware embeddings with user preferences. Extensive experiments on real and synthetic data show MAPS outperforms existing methods in both retrieval and ranking tasks.
Towards Heisenberg limit without critical slowing down via quantum reinforcement learning
Mar 04, 2025Critical ground states of quantum many-body systems have emerged as vital resources for quantum-enhanced sensing. Traditional methods to prepare these states often rely on adiabatic evolution, which may diminish the quantum sensing advantage. In this work, we propose a quantum reinforcement learning (QRL)-enhanced critical sensing protocol for quantum many-body systems with exotic phase diagrams. Starting from product states and utilizing QRL-discovered gate sequences, we explore sensing accuracy in the presence of unknown external magnetic fields, covering both local and global regimes. Our results demonstrate that QRL-learned sequences reach the finite quantum speed limit and generalize effectively across systems of arbitrary size, ensuring accuracy regardless of preparation time. This method can robustly achieve Heisenberg and super-Heisenberg limits, even in noisy environments with practical Pauli measurements. Our study highlights the efficacy of QRL in enabling precise quantum state preparation, thereby advancing scalable, high-accuracy quantum critical sensing.