 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLemon Agent Technical Report
Feb 06, 2026Recent advanced LLM-powered agent systems have exhibited their remarkable capabilities in tackling complex, long-horizon tasks. Nevertheless, they still suffer from inherent limitations in resource efficiency, context management, and multimodal perception. Based on these observations, Lemon Agent is introduced, a multi-agent orchestrator-worker system built on a newly proposed AgentCortex framework, which formalizes the classic Planner-Executor-Memory paradigm through an adaptive task execution mechanism. Our system integrates a hierarchical self-adaptive scheduling mechanism that operates at both the overall orchestrator layer and workers layer. This mechanism can dynamically adjust computational intensity based on task complexity. It enables orchestrator to allocate one or more workers for parallel subtask execution, while workers can further improve operational efficiency by invoking tools concurrently. By virtue of this two-tier architecture, the system achieves synergistic balance between global task coordination and local task execution, thereby optimizing resource utilization and task processing efficiency in complex scenarios. To reduce context redundancy and increase information density during parallel steps, we adopt a three-tier progressive context management strategy. To make fuller use of historical information, we propose a self-evolving memory system, which can extract multi-dimensional valid information from all historical experiences to assist in completing similar tasks. Furthermore, we provide an enhanced MCP toolset. Empirical evaluations on authoritative benchmarks demonstrate that our Lemon Agent can achieve a state-of-the-art 91.36% overall accuracy on GAIA and secures the top position on the xbench-DeepSearch leaderboard with a score of 77+.
Collaborative Knowledge Fusion: A Novel Approach for Multi-task Recommender Systems via LLMs
Oct 28, 2024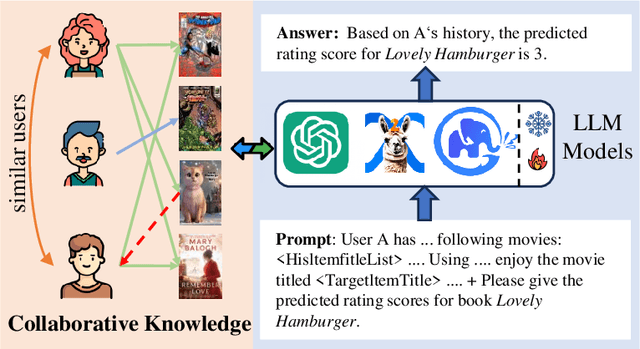
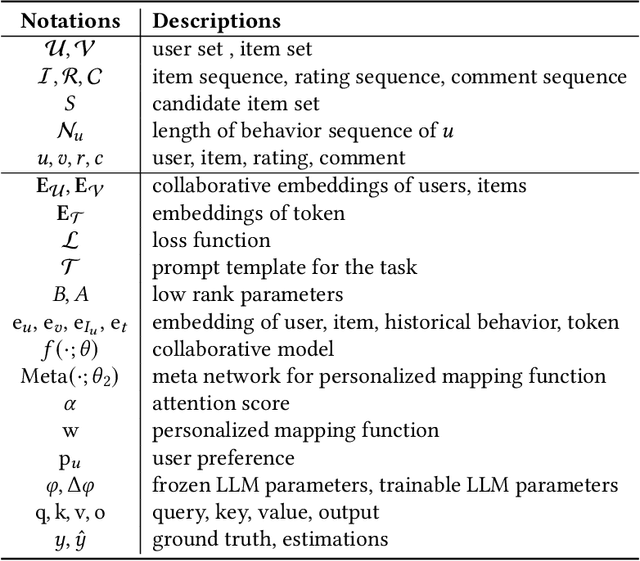
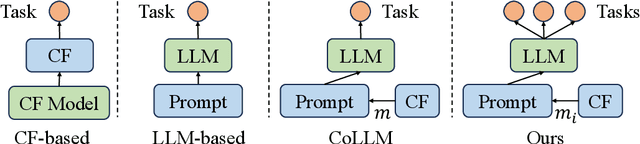

Owing to the impressive general intelligence of large language models (LLMs), there has been a growing trend to integrate them into recommender systems to gain a more profound insight into human interests and intentions. Existing LLMs-based recommender systems primarily leverage item attributes and user interaction histories in textual format, improving the single task like rating prediction or explainable recommendation. Nevertheless, these approaches overlook the crucial contribution of traditional collaborative signals in discerning users' profound intentions and disregard the interrelatedness among tasks. To address these limitations, we introduce a novel framework known as CKF, specifically developed to boost multi-task recommendations via personalized collaborative knowledge fusion into LLMs. Specifically, our method synergizes traditional collaborative filtering models to produce collaborative embeddings, subsequently employing the meta-network to construct personalized mapping bridges tailored for each user. Upon mapped, the embeddings are incorporated into meticulously designed prompt templates and then fed into an advanced LLM to represent user interests. To investigate the intrinsic relationship among diverse recommendation tasks, we develop Multi-Lora, a new parameter-efficient approach for multi-task optimization, adept at distinctly segregating task-shared and task-specific information. This method forges a connection between LLMs and recommendation scenarios, while simultaneously enriching the supervisory signal through mutual knowledge transfer among various tasks. Extensive experiments and in-depth robustness analyses across four common recommendation tasks on four large public data sets substantiate the effectiveness and superiority of our framework.
FLiP: Privacy-Preserving Federated Learning based on the Principle of Least Privileg
Oct 25, 2024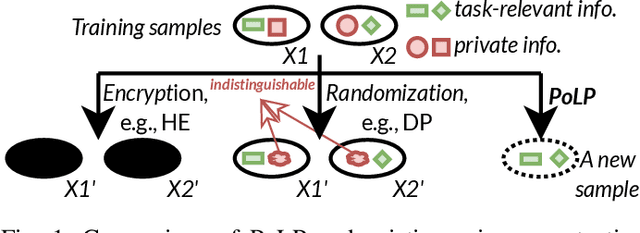
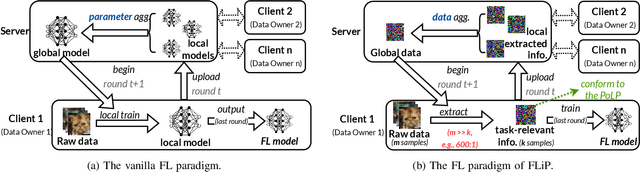
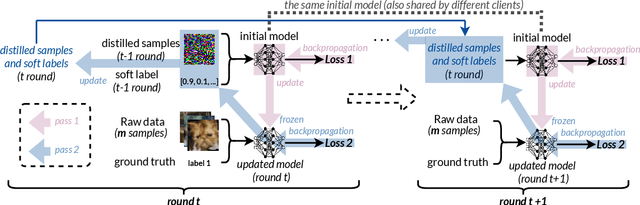

Federated Learning (FL) allows users to share knowledge instead of raw data to train a model with high accuracy. Unfortunately, during the training, users lose control over the knowledge shared, which causes serious data privacy issues. We hold that users are only willing and need to share the essential knowledge to the training task to obtain the FL model with high accuracy. However, existing efforts cannot help users minimize the shared knowledge according to the user intention in the FL training procedure. This work proposes FLiP, which aims to bring the principle of least privilege (PoLP) to FL training. The key design of FLiP is applying elaborate information reduction on the training data through a local-global dataset distillation design. We measure the privacy performance through attribute inference and membership inference attacks. Extensive experiments show that FLiP strikes a good balance between model accuracy and privacy protection.
Construction contract risk identification based on knowledge-augmented language model
Sep 22, 2023Contract review is an essential step in construction projects to prevent potential losses. However, the current methods for reviewing construction contracts lack effectiveness and reliability, leading to time-consuming and error-prone processes. While large language models (LLMs) have shown promise in revolutionizing natural language processing (NLP) tasks, they struggle with domain-specific knowledge and addressing specialized issues. This paper presents a novel approach that leverages LLMs with construction contract knowledge to emulate the process of contract review by human experts. Our tuning-free approach incorporates construction contract domain knowledge to enhance language models for identifying construction contract risks. The use of a natural language when building the domain knowledge base facilitates practical implementation. We evaluated our method on real construction contracts and achieved solid performance. Additionally, we investigated how large language models employ logical thinking during the task and provide insights and recommendations for future research.
A knowledge representation approach for construction contract knowledge modeling
Sep 21, 2023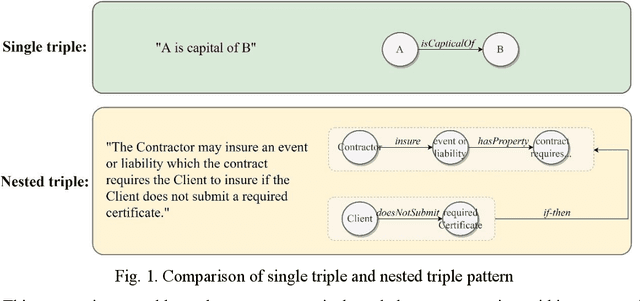
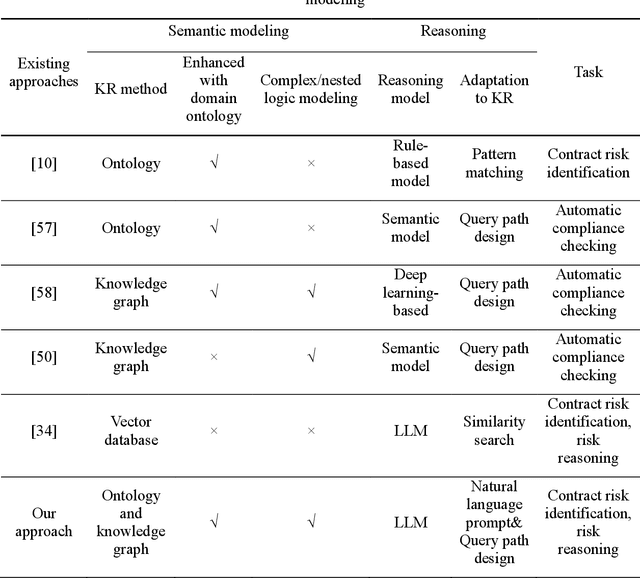
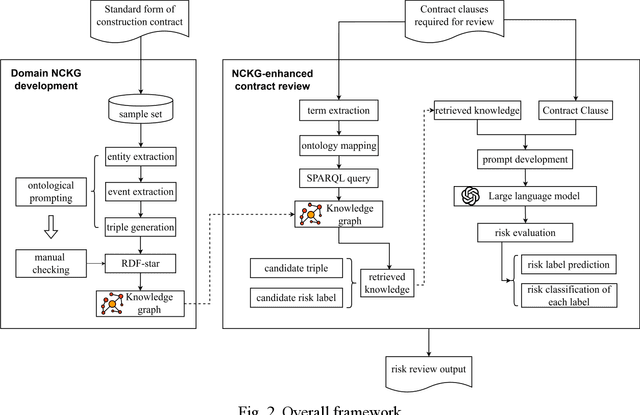

The emergence of large language models (LLMs) presents an unprecedented opportunity to automate construction contract management, reducing human errors and saving significant time and costs. However, LLMs may produce convincing yet inaccurate and misleading content due to a lack of domain expertise. To address this issue, expert-driven contract knowledge can be represented in a structured manner to constrain the automatic contract management process. This paper introduces the Nested Contract Knowledge Graph (NCKG), a knowledge representation approach that captures the complexity of contract knowledge using a nested structure. It includes a nested knowledge representation framework, a NCKG ontology built on the framework, and an implementation method. Furthermore, we present the LLM-assisted contract review pipeline enhanced with external knowledge in NCKG. Our pipeline achieves a promising performance in contract risk reviewing, shedding light on the combination of LLM and KG towards more reliable and interpretable contract management.
Heterogeneous Social Event Detection via Hyperbolic Graph Representations
Feb 20, 2023



Social events reflect the dynamics of society and, here, natural disasters and emergencies receive significant attention. The timely detection of these events can provide organisations and individuals with valuable information to reduce or avoid losses. However, due to the complex heterogeneities of the content and structure of social media, existing models can only learn limited information; large amounts of semantic and structural information are ignored. In addition, due to high labour costs, it is rare for social media datasets to include high-quality labels, which also makes it challenging for models to learn information from social media. In this study, we propose two hyperbolic graph representation-based methods for detecting social events from heterogeneous social media environments. For cases where a dataset has labels, we designed a Hyperbolic Social Event Detection (HSED) model that converts complex social information into a unified social message graph. This model addresses the heterogeneity of social media, and, with this graph, the information in social media can be used to capture structural information based on the properties of hyperbolic space. For cases where the dataset is unlabelled, we designed an Unsupervised Hyperbolic Social Event Detection (UHSED). This model is based on the HSED model but includes graph contrastive learning to make it work in unlabelled scenarios. Extensive experiments demonstrate the superiority of the proposed approaches.
Mining User-aware Multi-relations for Fake News Detection in Large Scale Online Social Networks
Jan 04, 2023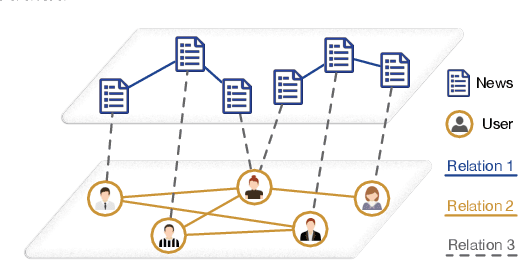
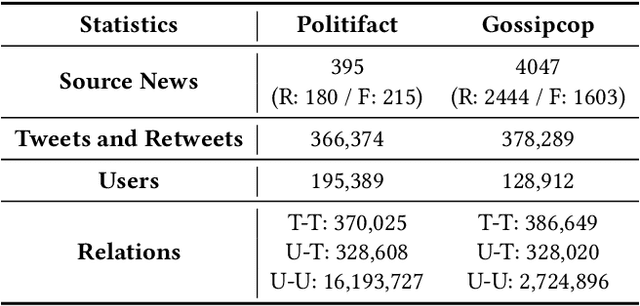
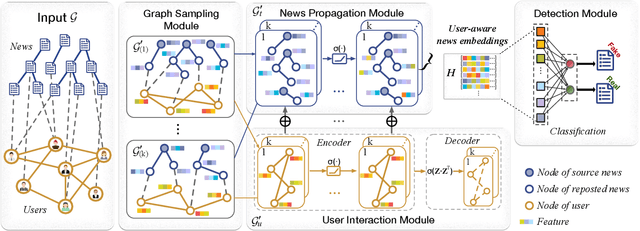
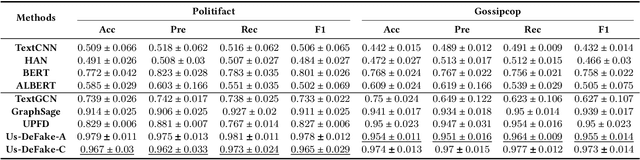
Users' involvement in creating and propagating news is a vital aspect of fake news detection in online social networks. Intuitively, credible users are more likely to share trustworthy news, while untrusted users have a higher probability of spreading untrustworthy news. In this paper, we construct a dual-layer graph (i.e., the news layer and the user layer) to extract multiple relations of news and users in social networks to derive rich information for detecting fake news. Based on the dual-layer graph, we propose a fake news detection model named Us-DeFake. It learns the propagation features of news in the news layer and the interaction features of users in the user layer. Through the inter-layer in the graph, Us-DeFake fuses the user signals that contain credibility information into the news features, to provide distinctive user-aware embeddings of news for fake news detection. The training process conducts on multiple dual-layer subgraphs obtained by a graph sampler to scale Us-DeFake in large scale social networks. Extensive experiments on real-world datasets illustrate the superiority of Us-DeFake which outperforms all baselines, and the users' credibility signals learned by interaction relation can notably improve the performance of our model.
A Comprehensive Survey on Community Detection with Deep Learning
May 26, 2021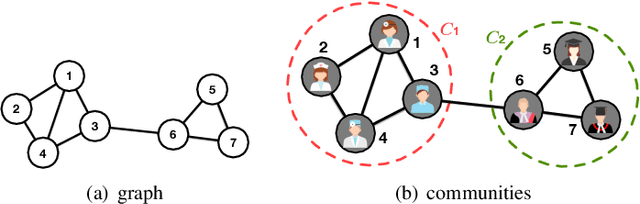
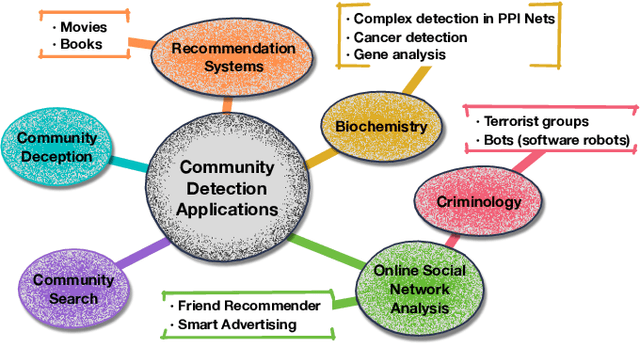
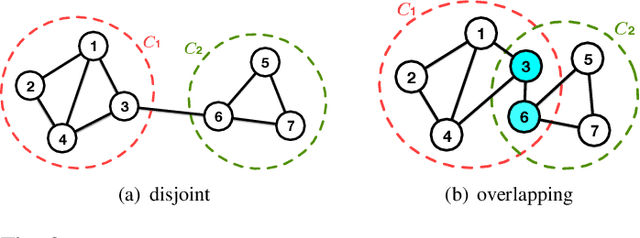
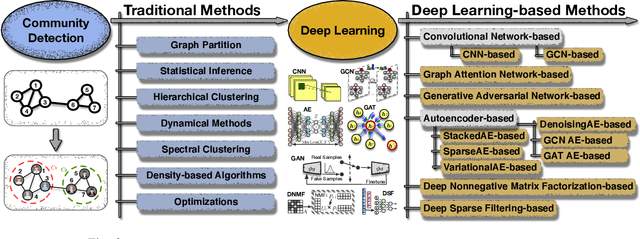
A community reveals the features and connections of its members that are different from those in other communities in a network. Detecting communities is of great significance in network analysis. Despite the classical spectral clustering and statistical inference methods, we notice a significant development of deep learning techniques for community detection in recent years with their advantages in handling high dimensional network data. Hence, a comprehensive overview of community detection's latest progress through deep learning is timely to both academics and practitioners. This survey devises and proposes a new taxonomy covering different categories of the state-of-the-art methods, including deep learning-based models upon deep neural networks, deep nonnegative matrix factorization and deep sparse filtering. The main category, i.e., deep neural networks, is further divided into convolutional networks, graph attention networks, generative adversarial networks and autoencoders. The survey also summarizes the popular benchmark data sets, model evaluation metrics, and open-source implementations to address experimentation settings. We then discuss the practical applications of community detection in various domains and point to implementation scenarios. Finally, we outline future directions by suggesting challenging topics in this fast-growing deep learning field.
The 4th International Workshop on Smart Simulation and Modelling for Complex Systems
Feb 01, 2021Computer-based modelling and simulation have become useful tools to facilitate humans to understand systems in different domains, such as physics, astrophysics, chemistry, biology, economics, engineering and social science. A complex system is featured with a large number of interacting components (agents, processes, etc.), whose aggregate activities are nonlinear and self-organized. Complex systems are hard to be simulated or modelled by using traditional computational approaches due to complex relationships among system components, distributed features of resources, and dynamics of environments. Meanwhile, smart systems such as multi-agent systems have demonstrated advantages and great potentials in modelling and simulating complex systems.