 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRI-SA: A Multimodal Dataset for Online Assessment of Human Situational Awareness during Remote Human-Robot Teaming
Mar 18, 2026Maintaining situational awareness (SA) is critical in human-robot teams. Yet, under high workload and dynamic conditions, operators often experience SA gaps. Automated detection of SA gaps could provide timely assistance for operators. However, conventional SA measures either disrupt task flow or cannot capture real-time fluctuations, limiting their operational utility. To the best of our knowledge, no publicly available dataset currently supports the systematic evaluation of online human SA assessment in human-robot teaming. To advance the development of online SA assessment tools, we introduce HRI-SA, a multimodal dataset from 30 participants in a realistic search-and-rescue human-robot teaming context, incorporating eye movements, pupil diameter, biosignals, user interactions, and robot data. The experimental protocol included predefined events requiring timely operator assistance, with ground truth SA latency of two types (perceptual and comprehension) systematically obtained by measuring the time between assistance need onset and resolution. We illustrate the utility of this dataset by evaluating standard machine learning models for detecting perceptual SA latencies using generic eye-tracking features and contextual features. Results show that eye-tracking features alone effectively classified perceptual SA latency (recall=88.91%, F1=67.63%) using leave-one-group-out cross-validation, with performance improved through contextual data fusion (recall=91.51%, F1=80.38%). This paper contributes the first public dataset supporting the systematic evaluation of SA throughout a human-robot teaming mission, while also demonstrating the potential of generic eye-tracking features for continuous perceptual SA latency detection in remote human-robot teaming.
Multi-Sourced, Multi-Agent Evidence Retrieval for Fact-Checking
Feb 27, 2026Misinformation spreading over the Internet poses a significant threat to both societies and individuals, necessitating robust and scalable fact-checking that relies on retrieving accurate and trustworthy evidence. Previous methods rely on semantic and social-contextual patterns learned from training data, which limits their generalization to new data distributions. Recently, Retrieval Augmented Generation (RAG) based methods have been proposed to utilize the reasoning capability of LLMs with retrieved grounding evidence documents. However, these methods largely rely on textual similarity for evidence retrieval and struggle to retrieve evidence that captures multi-hop semantic relations within rich document contents. These limitations lead to overlooking subtle factual correlations between the evidence and the claims to be fact-checked during evidence retrieval, thus causing inaccurate veracity predictions. To address these issues, we propose WKGFC, which exploits authorized open knowledge graph as a core resource of evidence. LLM-enabled retrieval is designed to assess the claims and retrieve the most relevant knowledge subgraphs, forming structured evidence for fact verification. To augment the knowledge graph evidence, we retrieve web contents for completion. The above process is implemented as an automatic Markov Decision Process (MDP): A reasoning LLM agent decides what actions to take according to the current evidence and the claims. To adapt the MDP for fact-checking, we use prompt optimization to fine-tune the agentic LLM.
Influence of Operator Expertise on Robot Supervision and Intervention
Jan 21, 2026With increasing levels of robot autonomy, robots are increasingly being supervised by users with varying levels of robotics expertise. As the diversity of the user population increases, it is important to understand how users with different expertise levels approach the supervision task and how this impacts performance of the human-robot team. This exploratory study investigates how operators with varying expertise levels perceive information and make intervention decisions when supervising a remote robot. We conducted a user study (N=27) where participants supervised a robot autonomously exploring four unknown tunnel environments in a simulator, and provided waypoints to intervene when they believed the robot had encountered difficulties. By analyzing the interaction data and questionnaire responses, we identify differing patterns in intervention timing and decision-making strategies across novice, intermediate, and expert users.
Adversarial Attacks Against Automated Fact-Checking: A Survey
Sep 10, 2025In an era where misinformation spreads freely, fact-checking (FC) plays a crucial role in verifying claims and promoting reliable information. While automated fact-checking (AFC) has advanced significantly, existing systems remain vulnerable to adversarial attacks that manipulate or generate claims, evidence, or claim-evidence pairs. These attacks can distort the truth, mislead decision-makers, and ultimately undermine the reliability of FC models. Despite growing research interest in adversarial attacks against AFC systems, a comprehensive, holistic overview of key challenges remains lacking. These challenges include understanding attack strategies, assessing the resilience of current models, and identifying ways to enhance robustness. This survey provides the first in-depth review of adversarial attacks targeting FC, categorizing existing attack methodologies and evaluating their impact on AFC systems. Additionally, we examine recent advancements in adversary-aware defenses and highlight open research questions that require further exploration. Our findings underscore the urgent need for resilient FC frameworks capable of withstanding adversarial manipulations in pursuit of preserving high verification accuracy.
Unseen Fake News Detection Through Casual Debiasing
Mar 06, 2025The widespread dissemination of fake news on social media poses significant risks, necessitating timely and accurate detection. However, existing methods struggle with unseen news due to their reliance on training data from past events and domains, leaving the challenge of detecting novel fake news largely unresolved. To address this, we identify biases in training data tied to specific domains and propose a debiasing solution FNDCD. Originating from causal analysis, FNDCD employs a reweighting strategy based on classification confidence and propagation structure regularization to reduce the influence of domain-specific biases, enhancing the detection of unseen fake news. Experiments on real-world datasets with non-overlapping news domains demonstrate FNDCD's effectiveness in improving generalization across domains.
Can AI Extract Antecedent Factors of Human Trust in AI? An Application of Information Extraction for Scientific Literature in Behavioural and Computer Sciences
Dec 16, 2024



Information extraction from the scientific literature is one of the main techniques to transform unstructured knowledge hidden in the text into structured data which can then be used for decision-making in down-stream tasks. One such area is Trust in AI, where factors contributing to human trust in artificial intelligence applications are studied. The relationships of these factors with human trust in such applications are complex. We hence explore this space from the lens of information extraction where, with the input of domain experts, we carefully design annotation guidelines, create the first annotated English dataset in this domain, investigate an LLM-guided annotation, and benchmark it with state-of-the-art methods using large language models in named entity and relation extraction. Our results indicate that this problem requires supervised learning which may not be currently feasible with prompt-based LLMs.
Less is More: Unseen Domain Fake News Detection via Causal Propagation Substructures
Nov 14, 2024The spread of fake news on social media poses significant threats to individuals and society. Text-based and graph-based models have been employed for fake news detection by analysing news content and propagation networks, showing promising results in specific scenarios. However, these data-driven models heavily rely on pre-existing in-distribution data for training, limiting their performance when confronted with fake news from emerging or previously unseen domains, known as out-of-distribution (OOD) data. Tackling OOD fake news is a challenging yet critical task. In this paper, we introduce the Causal Subgraph-oriented Domain Adaptive Fake News Detection (CSDA) model, designed to enhance zero-shot fake news detection by extracting causal substructures from propagation graphs using in-distribution data and generalising this approach to OOD data. The model employs a graph neural network based mask generation process to identify dominant nodes and edges within the propagation graph, using these substructures for fake news detection. Additionally, the performance of CSDA is further improved through contrastive learning in few-shot scenarios, where a limited amount of OOD data is available for training. Extensive experiments on public social media datasets demonstrate that CSDA effectively handles OOD fake news detection, achieving a 7 to 16 percents accuracy improvement over other state-of-the-art models.
Do Text-to-Vis Benchmarks Test Real Use of Visualisations?
Jul 29, 2024



Large language models are able to generate code for visualisations in response to user requests. This is a useful application, and an appealing one for NLP research because plots of data provide grounding for language. However, there are relatively few benchmarks, and it is unknown whether those that exist are representative of what people do in practice. This paper aims to answer that question through an empirical study comparing benchmark datasets and code from public repositories. Our findings reveal a substantial gap in datasets, with evaluations not testing the same distribution of chart types, attributes, and the number of actions. The only representative dataset requires modification to become an end-to-end and practical benchmark. This shows that new, more benchmarks are needed to support the development of systems that truly address users' visualisation needs. These observations will guide future data creation, highlighting which features hold genuine significance for users.
MultiADE: A Multi-domain Benchmark for Adverse Drug Event Extraction
May 28, 2024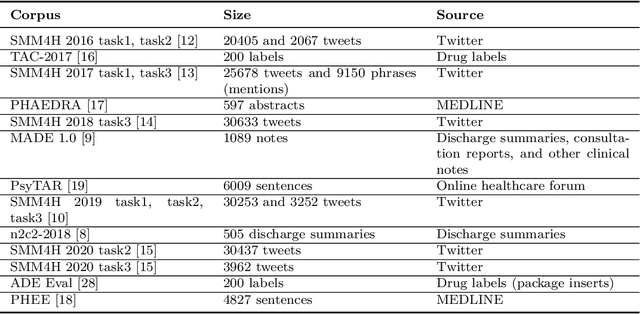
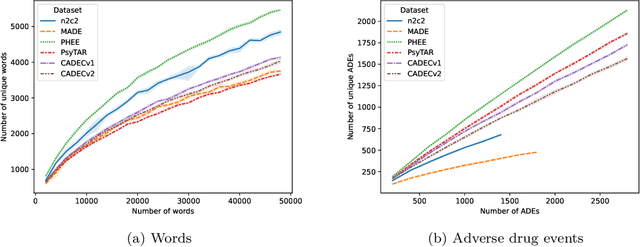
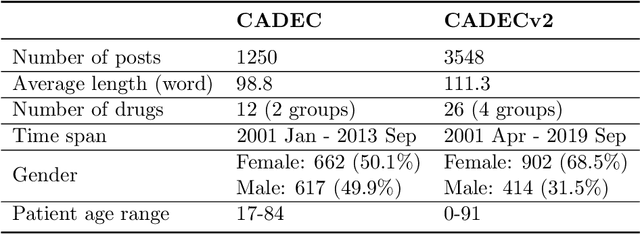
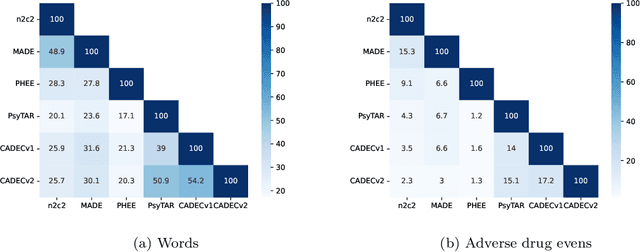
Objective. Active adverse event surveillance monitors Adverse Drug Events (ADE) from different data sources, such as electronic health records, medical literature, social media and search engine logs. Over years, many datasets are created, and shared tasks are organised to facilitate active adverse event surveillance. However, most-if not all-datasets or shared tasks focus on extracting ADEs from a particular type of text. Domain generalisation-the ability of a machine learning model to perform well on new, unseen domains (text types)-is under-explored. Given the rapid advancements in natural language processing, one unanswered question is how far we are from having a single ADE extraction model that are effective on various types of text, such as scientific literature and social media posts}. Methods. We contribute to answering this question by building a multi-domain benchmark for adverse drug event extraction, which we named MultiADE. The new benchmark comprises several existing datasets sampled from different text types and our newly created dataset-CADECv2, which is an extension of CADEC (Karimi, et al., 2015), covering online posts regarding more diverse drugs than CADEC. Our new dataset is carefully annotated by human annotators following detailed annotation guidelines. Conclusion. Our benchmark results show that the generalisation of the trained models is far from perfect, making it infeasible to be deployed to process different types of text. In addition, although intermediate transfer learning is a promising approach to utilising existing resources, further investigation is needed on methods of domain adaptation, particularly cost-effective methods to select useful training instances.
A2C: A Modular Multi-stage Collaborative Decision Framework for Human-AI Teams
Jan 25, 2024This paper introduces A2C, a multi-stage collaborative decision framework designed to enable robust decision-making within human-AI teams. Drawing inspiration from concepts such as rejection learning and learning to defer, A2C incorporates AI systems trained to recognise uncertainty in their decisions and defer to human experts when needed. Moreover, A2C caters to scenarios where even human experts encounter limitations, such as in incident detection and response in cyber Security Operations Centres (SOC). In such scenarios, A2C facilitates collaborative explorations, enabling collective resolution of complex challenges. With support for three distinct decision-making modes in human-AI teams: Automated, Augmented, and Collaborative, A2C offers a flexible platform for developing effective strategies for human-AI collaboration. By harnessing the strengths of both humans and AI, it significantly improves the efficiency and effectiveness of complex decision-making in dynamic and evolving environments. To validate A2C's capabilities, we conducted extensive simulative experiments using benchmark datasets. The results clearly demonstrate that all three modes of decision-making can be effectively supported by A2C. Most notably, collaborative exploration by (simulated) human experts and AI achieves superior performance compared to AI in isolation, underscoring the framework's potential to enhance decision-making within human-AI teams.