 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaLead: A Comprehensive Human-Curated Leaderboard Dataset for Transparent Reporting of Machine Learning Experiments
Jan 30, 2026Leaderboards are crucial in the machine learning (ML) domain for benchmarking and tracking progress. However, creating leaderboards traditionally demands significant manual effort. In recent years, efforts have been made to automate leaderboard generation, but existing datasets for this purpose are limited by capturing only the best results from each paper and limited metadata. We present MetaLead, a fully human-annotated ML Leaderboard dataset that captures all experimental results for result transparency and contains extra metadata, such as the result experimental type: baseline, proposed method, or variation of proposed method for experiment-type guided comparisons, and explicitly separates train and test dataset for cross-domain assessment. This enriched structure makes MetaLead a powerful resource for more transparent and nuanced evaluations across ML research.
Can AI Extract Antecedent Factors of Human Trust in AI? An Application of Information Extraction for Scientific Literature in Behavioural and Computer Sciences
Dec 16, 2024



Information extraction from the scientific literature is one of the main techniques to transform unstructured knowledge hidden in the text into structured data which can then be used for decision-making in down-stream tasks. One such area is Trust in AI, where factors contributing to human trust in artificial intelligence applications are studied. The relationships of these factors with human trust in such applications are complex. We hence explore this space from the lens of information extraction where, with the input of domain experts, we carefully design annotation guidelines, create the first annotated English dataset in this domain, investigate an LLM-guided annotation, and benchmark it with state-of-the-art methods using large language models in named entity and relation extraction. Our results indicate that this problem requires supervised learning which may not be currently feasible with prompt-based LLMs.
Self-Attentive Constituency Parsing for UCCA-based Semantic Parsing
Oct 01, 2021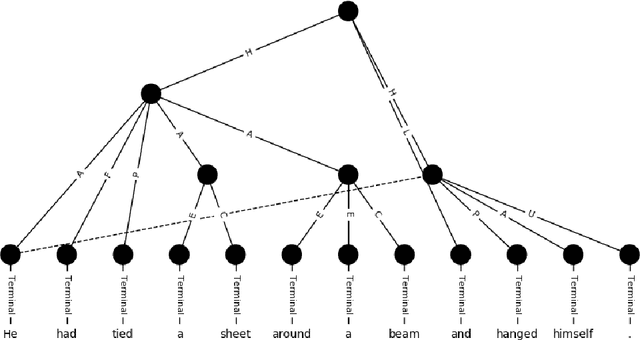

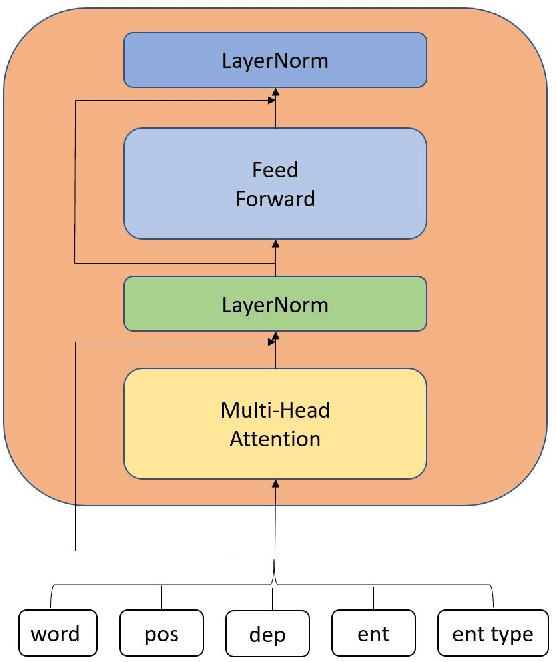
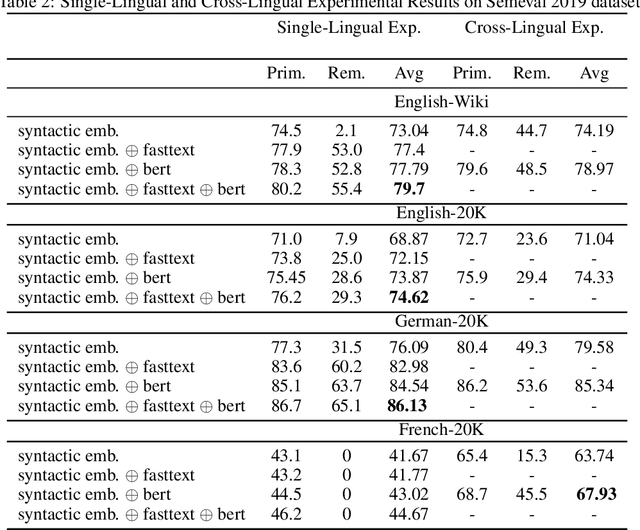
Semantic parsing provides a way to extract the semantic structure of a text that could be understood by machines. It is utilized in various NLP applications that require text comprehension such as summarization and question answering. Graph-based representation is one of the semantic representation approaches to express the semantic structure of a text. Such representations generate expressive and adequate graph-based target structures. In this paper, we focus primarily on UCCA graph-based semantic representation. The paper not only presents the existing approaches proposed for UCCA representation, but also proposes a novel self-attentive neural parsing model for the UCCA representation. We present the results for both single-lingual and cross-lingual tasks using zero-shot and few-shot learning for low-resource languages.
Joint PoS Tagging and Stemming for Agglutinative Languages
May 24, 2017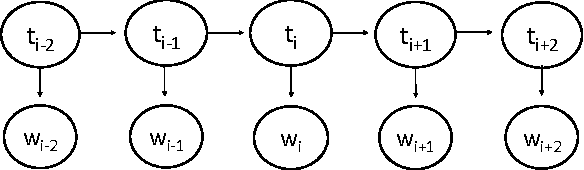

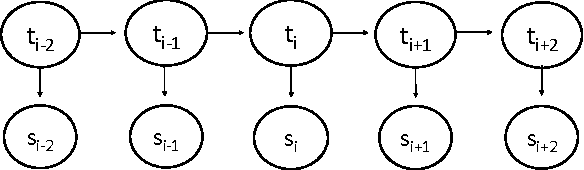

The number of word forms in agglutinative languages is theoretically infinite and this variety in word forms introduces sparsity in many natural language processing tasks. Part-of-speech tagging (PoS tagging) is one of these tasks that often suffers from sparsity. In this paper, we present an unsupervised Bayesian model using Hidden Markov Models (HMMs) for joint PoS tagging and stemming for agglutinative languages. We use stemming to reduce sparsity in PoS tagging. Two tasks are jointly performed to provide a mutual benefit in both tasks. Our results show that joint POS tagging and stemming improves PoS tagging scores. We present results for Turkish and Finnish as agglutinative languages and English as a morphologically poor language.
* 12 pages with 3 figures, accepted and presented at the CICLING 2017 - 18th International Conference on Intelligent Text Processing and Computational Linguistics