 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Analysis of Adversarial Attacks against Spam Filters
May 04, 2025



Deep learning has revolutionized email filtering, which is critical to protect users from cyber threats such as spam, malware, and phishing. However, the increasing sophistication of adversarial attacks poses a significant challenge to the effectiveness of these filters. This study investigates the impact of adversarial attacks on deep learning-based spam detection systems using real-world datasets. Six prominent deep learning models are evaluated on these datasets, analyzing attacks at the word, character sentence, and AI-generated paragraph-levels. Novel scoring functions, including spam weights and attention weights, are introduced to improve attack effectiveness. This comprehensive analysis sheds light on the vulnerabilities of spam filters and contributes to efforts to improve their security against evolving adversarial threats.
Self-Attentive Constituency Parsing for UCCA-based Semantic Parsing
Oct 01, 2021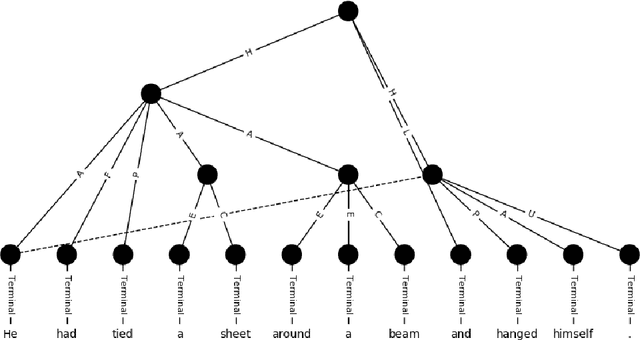

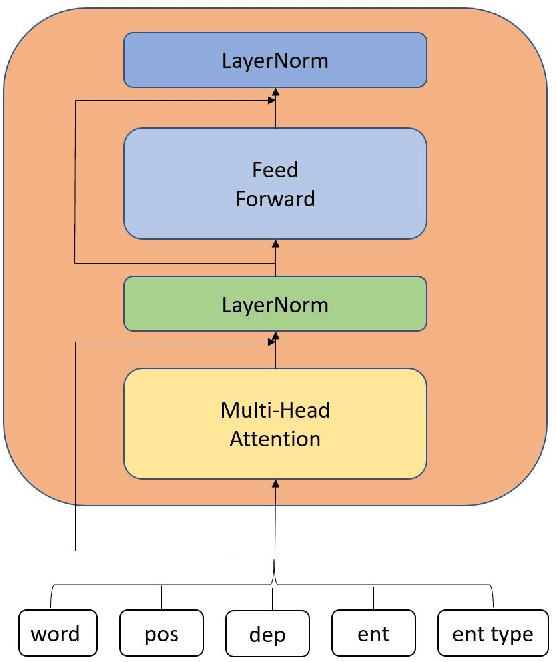
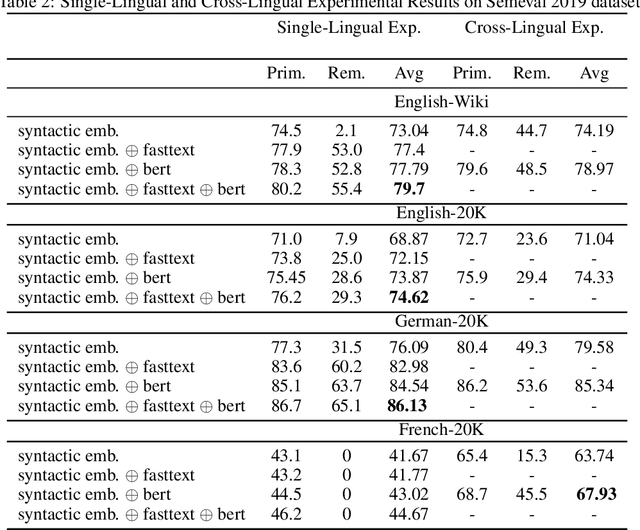
Semantic parsing provides a way to extract the semantic structure of a text that could be understood by machines. It is utilized in various NLP applications that require text comprehension such as summarization and question answering. Graph-based representation is one of the semantic representation approaches to express the semantic structure of a text. Such representations generate expressive and adequate graph-based target structures. In this paper, we focus primarily on UCCA graph-based semantic representation. The paper not only presents the existing approaches proposed for UCCA representation, but also proposes a novel self-attentive neural parsing model for the UCCA representation. We present the results for both single-lingual and cross-lingual tasks using zero-shot and few-shot learning for low-resource languages.
Android Security using NLP Techniques: A Review
Jul 07, 2021


Android is among the most targeted platform by attackers. While attackers are improving their techniques, traditional solutions based on static and dynamic analysis have been also evolving. In addition to the application code, Android applications have some metadata that could be useful for security analysis of applications. Unlike traditional application distribution mechanisms, Android applications are distributed centrally in mobile markets. Therefore, beside application packages, such markets contain app information provided by app developers and app users. The availability of such useful textual data together with the advancement in Natural Language Processing (NLP) that is used to process and understand textual data has encouraged researchers to investigate the use of NLP techniques in Android security. Especially, security solutions based on NLP have accelerated in the last 5 years and proven to be useful. This study reviews these proposals and aim to explore possible research directions for future studies by presenting state-of-the-art in this domain. We mainly focus on NLP-based solutions under four categories: description-to-behaviour fidelity, description generation, privacy and malware detection.
Joint PoS Tagging and Stemming for Agglutinative Languages
May 24, 2017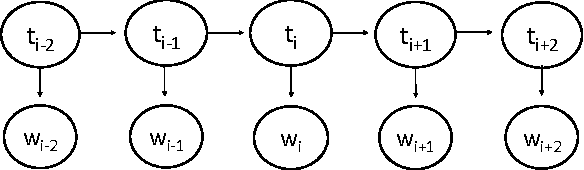


The number of word forms in agglutinative languages is theoretically infinite and this variety in word forms introduces sparsity in many natural language processing tasks. Part-of-speech tagging (PoS tagging) is one of these tasks that often suffers from sparsity. In this paper, we present an unsupervised Bayesian model using Hidden Markov Models (HMMs) for joint PoS tagging and stemming for agglutinative languages. We use stemming to reduce sparsity in PoS tagging. Two tasks are jointly performed to provide a mutual benefit in both tasks. Our results show that joint POS tagging and stemming improves PoS tagging scores. We present results for Turkish and Finnish as agglutinative languages and English as a morphologically poor language.
* 12 pages with 3 figures, accepted and presented at the CICLING 2017 - 18th International Conference on Intelligent Text Processing and Computational Linguistics
Building Morphological Chains for Agglutinative Languages
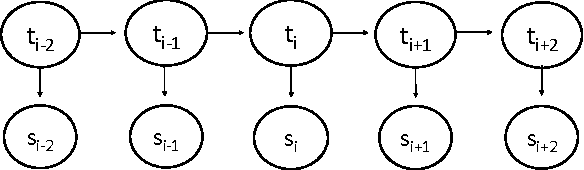
May 05, 2017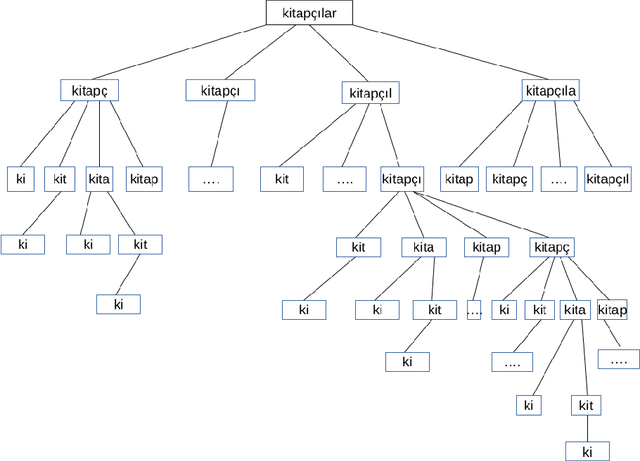

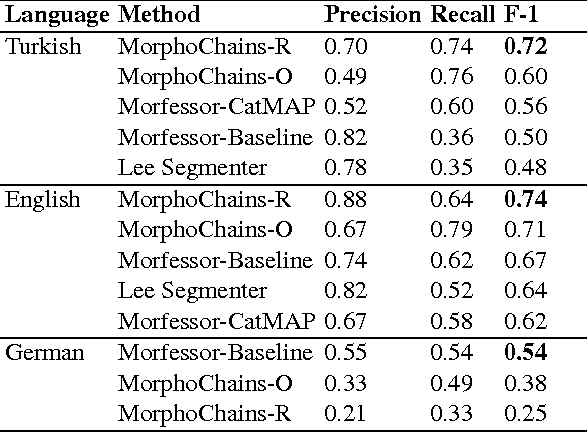
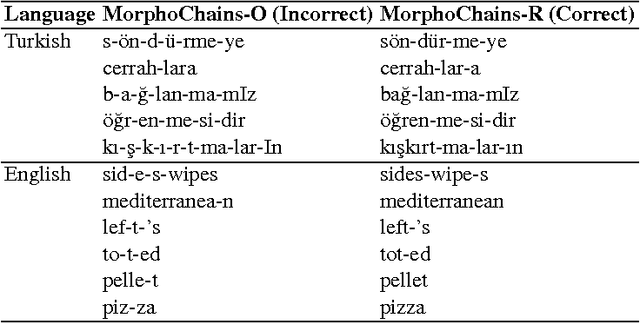
In this paper, we build morphological chains for agglutinative languages by using a log-linear model for the morphological segmentation task. The model is based on the unsupervised morphological segmentation system called MorphoChains. We extend MorphoChains log linear model by expanding the candidate space recursively to cover more split points for agglutinative languages such as Turkish, whereas in the original model candidates are generated by considering only binary segmentation of each word. The results show that we improve the state-of-art Turkish scores by 12% having a F-measure of 72% and we improve the English scores by 3% having a F-measure of 74%. Eventually, the system outperforms both MorphoChains and other well-known unsupervised morphological segmentation systems. The results indicate that candidate generation plays an important role in such an unsupervised log-linear model that is learned using contrastive estimation with negative samples.
A Trie-Structured Bayesian Model for Unsupervised Morphological Segmentation
Apr 24, 2017

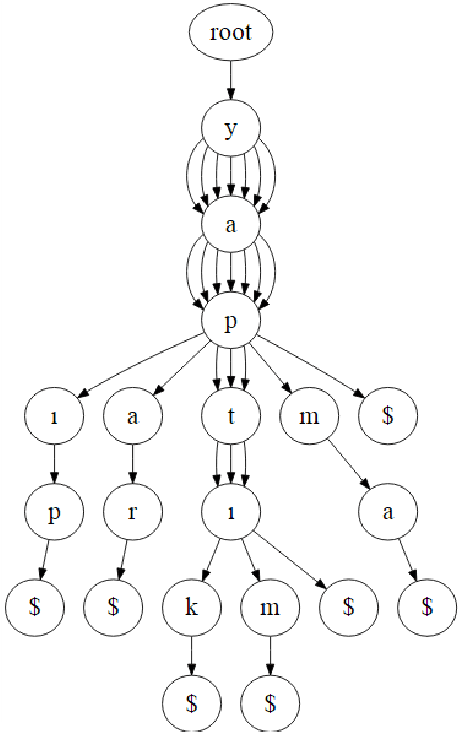

In this paper, we introduce a trie-structured Bayesian model for unsupervised morphological segmentation. We adopt prior information from different sources in the model. We use neural word embeddings to discover words that are morphologically derived from each other and thereby that are semantically similar. We use letter successor variety counts obtained from tries that are built by neural word embeddings. Our results show that using different information sources such as neural word embeddings and letter successor variety as prior information improves morphological segmentation in a Bayesian model. Our model outperforms other unsupervised morphological segmentation models on Turkish and gives promising results on English and German for scarce resources.
Turkish PoS Tagging by Reducing Sparsity with Morpheme Tags in Small Datasets
Mar 10, 2017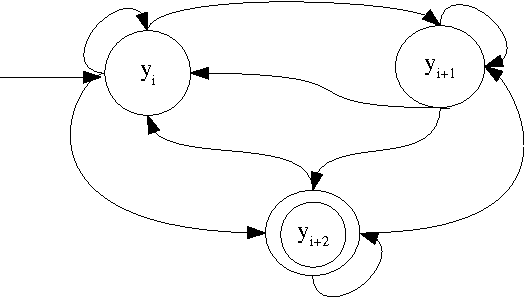


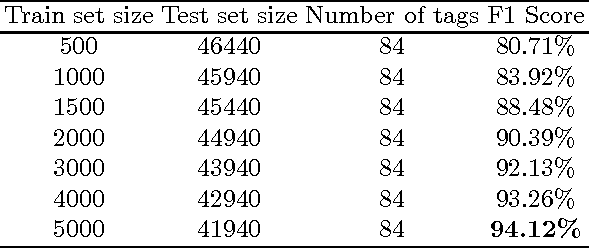
Sparsity is one of the major problems in natural language processing. The problem becomes even more severe in agglutinating languages that are highly prone to be inflected. We deal with sparsity in Turkish by adopting morphological features for part-of-speech tagging. We learn inflectional and derivational morpheme tags in Turkish by using conditional random fields (CRF) and we employ the morpheme tags in part-of-speech (PoS) tagging by using hidden Markov models (HMMs) to mitigate sparsity. Results show that using morpheme tags in PoS tagging helps alleviate the sparsity in emission probabilities. Our model outperforms other hidden Markov model based PoS tagging models for small training datasets in Turkish. We obtain an accuracy of 94.1% in morpheme tagging and 89.2% in PoS tagging on a 5K training dataset.