 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Sourced, Multi-Agent Evidence Retrieval for Fact-Checking
Feb 27, 2026Misinformation spreading over the Internet poses a significant threat to both societies and individuals, necessitating robust and scalable fact-checking that relies on retrieving accurate and trustworthy evidence. Previous methods rely on semantic and social-contextual patterns learned from training data, which limits their generalization to new data distributions. Recently, Retrieval Augmented Generation (RAG) based methods have been proposed to utilize the reasoning capability of LLMs with retrieved grounding evidence documents. However, these methods largely rely on textual similarity for evidence retrieval and struggle to retrieve evidence that captures multi-hop semantic relations within rich document contents. These limitations lead to overlooking subtle factual correlations between the evidence and the claims to be fact-checked during evidence retrieval, thus causing inaccurate veracity predictions. To address these issues, we propose WKGFC, which exploits authorized open knowledge graph as a core resource of evidence. LLM-enabled retrieval is designed to assess the claims and retrieve the most relevant knowledge subgraphs, forming structured evidence for fact verification. To augment the knowledge graph evidence, we retrieve web contents for completion. The above process is implemented as an automatic Markov Decision Process (MDP): A reasoning LLM agent decides what actions to take according to the current evidence and the claims. To adapt the MDP for fact-checking, we use prompt optimization to fine-tune the agentic LLM.
Evidential Trust-Aware Model Personalization in Decentralized Federated Learning for Wearable IoT
Dec 22, 2025Decentralized federated learning (DFL) enables collaborative model training across edge devices without centralized coordination, offering resilience against single points of failure. However, statistical heterogeneity arising from non-identically distributed local data creates a fundamental challenge: nodes must learn personalized models adapted to their local distributions while selectively collaborating with compatible peers. Existing approaches either enforce a single global model that fits no one well, or rely on heuristic peer selection mechanisms that cannot distinguish between peers with genuinely incompatible data distributions and those with valuable complementary knowledge. We present Murmura, a framework that leverages evidential deep learning to enable trust-aware model personalization in DFL. Our key insight is that epistemic uncertainty from Dirichlet-based evidential models directly indicates peer compatibility: high epistemic uncertainty when a peer's model evaluates local data reveals distributional mismatch, enabling nodes to exclude incompatible influence while maintaining personalized models through selective collaboration. Murmura introduces a trust-aware aggregation mechanism that computes peer compatibility scores through cross-evaluation on local validation samples and personalizes model aggregation based on evidential trust with adaptive thresholds. Evaluation on three wearable IoT datasets (UCI HAR, PAMAP2, PPG-DaLiA) demonstrates that Murmura reduces performance degradation from IID to non-IID conditions compared to baseline (0.9% vs. 19.3%), achieves 7.4$\times$ faster convergence, and maintains stable accuracy across hyperparameter choices. These results establish evidential uncertainty as a principled foundation for compatibility-aware personalization in decentralized heterogeneous environments.
SketchGuard: Scaling Byzantine-Robust Decentralized Federated Learning via Sketch-Based Screening
Oct 09, 2025Decentralized Federated Learning (DFL) enables privacy-preserving collaborative training without centralized servers, but remains vulnerable to Byzantine attacks where malicious clients submit corrupted model updates. Existing Byzantine-robust DFL defenses rely on similarity-based neighbor screening that requires every client to exchange and compare complete high-dimensional model vectors with all neighbors in each training round, creating prohibitive communication and computational costs that prevent deployment at web scale. We propose SketchGuard, a general framework that decouples Byzantine filtering from model aggregation through sketch-based neighbor screening. SketchGuard compresses $d$-dimensional models to $k$-dimensional sketches ($k \ll d$) using Count Sketch for similarity comparisons, then selectively fetches full models only from accepted neighbors, reducing per-round communication complexity from $O(d|N_i|)$ to $O(k|N_i| + d|S_i|)$, where $|N_i|$ is the neighbor count and $|S_i| \le |N_i|$ is the accepted neighbor count. We establish rigorous convergence guarantees in both strongly convex and non-convex settings, proving that Count Sketch compression preserves Byzantine resilience with controlled degradation bounds where approximation errors introduce only a $(1+O(\epsilon))$ factor in the effective threshold parameter. Comprehensive experiments across multiple datasets, network topologies, and attack scenarios demonstrate that SketchGuard maintains identical robustness to state-of-the-art methods while reducing computation time by up to 82% and communication overhead by 50-70% depending on filtering effectiveness, with benefits scaling multiplicatively with model dimensionality and network connectivity. These results establish the viability of sketch-based compression as a fundamental enabler of robust DFL at web scale.
Network Structures as an Attack Surface: Topology-Based Privacy Leakage in Federated Learning
Jun 24, 2025Federated learning systems increasingly rely on diverse network topologies to address scalability and organizational constraints. While existing privacy research focuses on gradient-based attacks, the privacy implications of network topology knowledge remain critically understudied. We conduct the first comprehensive analysis of topology-based privacy leakage across realistic adversarial knowledge scenarios, demonstrating that adversaries with varying degrees of structural knowledge can infer sensitive data distribution patterns even under strong differential privacy guarantees. Through systematic evaluation of 4,720 attack instances, we analyze six distinct adversarial knowledge scenarios: complete topology knowledge and five partial knowledge configurations reflecting real-world deployment constraints. We propose three complementary attack vectors: communication pattern analysis, parameter magnitude profiling, and structural position correlation, achieving success rates of 84.1%, 65.0%, and 47.2% under complete knowledge conditions. Critically, we find that 80% of realistic partial knowledge scenarios maintain attack effectiveness above security thresholds, with certain partial knowledge configurations achieving performance superior to the baseline complete knowledge scenario. To address these vulnerabilities, we propose and empirically validate structural noise injection as a complementary defense mechanism across 808 configurations, demonstrating up to 51.4% additional attack reduction when properly layered with existing privacy techniques. These results establish that network topology represents a fundamental privacy vulnerability in federated learning systems while providing practical pathways for mitigation through topology-aware defense mechanisms.
Less is More: Unseen Domain Fake News Detection via Causal Propagation Substructures
Nov 14, 2024The spread of fake news on social media poses significant threats to individuals and society. Text-based and graph-based models have been employed for fake news detection by analysing news content and propagation networks, showing promising results in specific scenarios. However, these data-driven models heavily rely on pre-existing in-distribution data for training, limiting their performance when confronted with fake news from emerging or previously unseen domains, known as out-of-distribution (OOD) data. Tackling OOD fake news is a challenging yet critical task. In this paper, we introduce the Causal Subgraph-oriented Domain Adaptive Fake News Detection (CSDA) model, designed to enhance zero-shot fake news detection by extracting causal substructures from propagation graphs using in-distribution data and generalising this approach to OOD data. The model employs a graph neural network based mask generation process to identify dominant nodes and edges within the propagation graph, using these substructures for fake news detection. Additionally, the performance of CSDA is further improved through contrastive learning in few-shot scenarios, where a limited amount of OOD data is available for training. Extensive experiments on public social media datasets demonstrate that CSDA effectively handles OOD fake news detection, achieving a 7 to 16 percents accuracy improvement over other state-of-the-art models.
Fake News Detection Through Graph-based Neural Networks: A Survey
Jul 24, 2023The popularity of online social networks has enabled rapid dissemination of information. People now can share and consume information much more rapidly than ever before. However, low-quality and/or accidentally/deliberately fake information can also spread rapidly. This can lead to considerable and negative impacts on society. Identifying, labelling and debunking online misinformation as early as possible has become an increasingly urgent problem. Many methods have been proposed to detect fake news including many deep learning and graph-based approaches. In recent years, graph-based methods have yielded strong results, as they can closely model the social context and propagation process of online news. In this paper, we present a systematic review of fake news detection studies based on graph-based and deep learning-based techniques. We classify existing graph-based methods into knowledge-driven methods, propagation-based methods, and heterogeneous social context-based methods, depending on how a graph structure is constructed to model news related information flows. We further discuss the challenges and open problems in graph-based fake news detection and identify future research directions.
Multi-Agent Patrolling with Battery Constraints through Deep Reinforcement Learning
Dec 16, 2022



Autonomous vehicles are suited for continuous area patrolling problems. However, finding an optimal patrolling strategy can be challenging for many reasons. Firstly, patrolling environments are often complex and can include unknown and evolving environmental factors. Secondly, autonomous vehicles can have failures or hardware constraints such as limited battery lives. Importantly, patrolling large areas often requires multiple agents that need to collectively coordinate their actions. In this work, we consider these limitations and propose an approach based on a distributed, model-free deep reinforcement learning based multi-agent patrolling strategy. In this approach, agents make decisions locally based on their own environmental observations and on shared information. In addition, agents are trained to automatically recharge themselves when required to support continuous collective patrolling. A homogeneous multi-agent architecture is proposed, where all patrolling agents have an identical policy. This architecture provides a robust patrolling system that can tolerate agent failures and allow supplementary agents to be added to replace failed agents or to increase the overall patrol performance. This performance is validated through experiments from multiple perspectives, including the overall patrol performance, the efficiency of the battery recharging strategy, the overall robustness of the system, and the agents' ability to adapt to environment dynamics.
Machine Learning-based Classification of Birds through Birdsong
Dec 09, 2022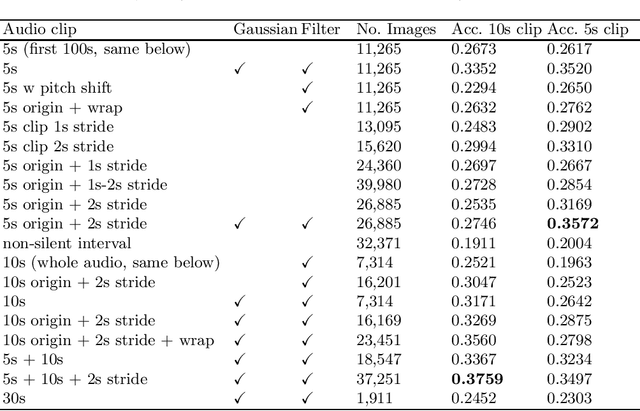
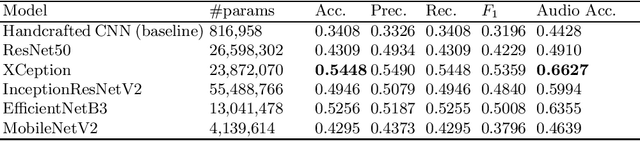

Audio sound recognition and classification is used for many tasks and applications including human voice recognition, music recognition and audio tagging. In this paper we apply Mel Frequency Cepstral Coefficients (MFCC) in combination with a range of machine learning models to identify (Australian) birds from publicly available audio files of their birdsong. We present approaches used for data processing and augmentation and compare the results of various state of the art machine learning models. We achieve an overall accuracy of 91% for the top-5 birds from the 30 selected as the case study. Applying the models to more challenging and diverse audio files comprising 152 bird species, we achieve an accuracy of 58%
A Survey of Automated Data Augmentation Algorithms for Deep Learning-based Image Classication Tasks
Jun 14, 2022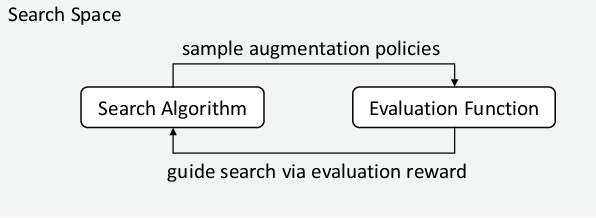
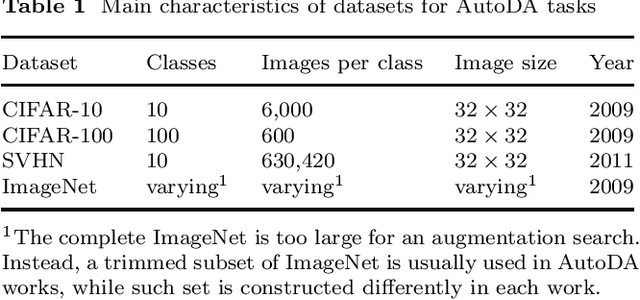
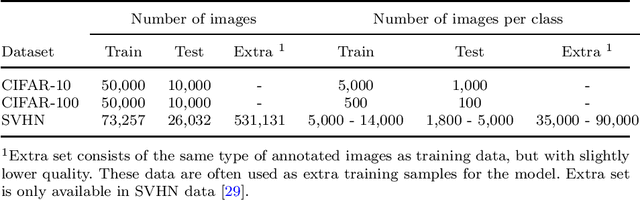
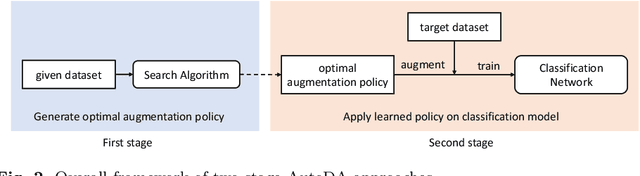
In recent years, one of the most popular techniques in the computer vision community has been the deep learning technique. As a data-driven technique, deep model requires enormous amounts of accurately labelled training data, which is often inaccessible in many real-world applications. A data-space solution is Data Augmentation (DA), that can artificially generate new images out of original samples. Image augmentation strategies can vary by dataset, as different data types might require different augmentations to facilitate model training. However, the design of DA policies has been largely decided by the human experts with domain knowledge, which is considered to be highly subjective and error-prone. To mitigate such problem, a novel direction is to automatically learn the image augmentation policies from the given dataset using Automated Data Augmentation (AutoDA) techniques. The goal of AutoDA models is to find the optimal DA policies that can maximize the model performance gains. This survey discusses the underlying reasons of the emergence of AutoDA technology from the perspective of image classification. We identify three key components of a standard AutoDA model: a search space, a search algorithm and an evaluation function. Based on their architecture, we provide a systematic taxonomy of existing image AutoDA approaches. This paper presents the major works in AutoDA field, discussing their pros and cons, and proposing several potential directions for future improvements.