 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Patrolling with Battery Constraints through Deep Reinforcement Learning
Dec 16, 2022



Autonomous vehicles are suited for continuous area patrolling problems. However, finding an optimal patrolling strategy can be challenging for many reasons. Firstly, patrolling environments are often complex and can include unknown and evolving environmental factors. Secondly, autonomous vehicles can have failures or hardware constraints such as limited battery lives. Importantly, patrolling large areas often requires multiple agents that need to collectively coordinate their actions. In this work, we consider these limitations and propose an approach based on a distributed, model-free deep reinforcement learning based multi-agent patrolling strategy. In this approach, agents make decisions locally based on their own environmental observations and on shared information. In addition, agents are trained to automatically recharge themselves when required to support continuous collective patrolling. A homogeneous multi-agent architecture is proposed, where all patrolling agents have an identical policy. This architecture provides a robust patrolling system that can tolerate agent failures and allow supplementary agents to be added to replace failed agents or to increase the overall patrol performance. This performance is validated through experiments from multiple perspectives, including the overall patrol performance, the efficiency of the battery recharging strategy, the overall robustness of the system, and the agents' ability to adapt to environment dynamics.
Where did you tweet from? Inferring the origin locations of tweets based on contextual information
Nov 18, 2022Public conversations on Twitter comprise many pertinent topics including disasters, protests, politics, propaganda, sports, climate change, epidemics/pandemic outbreaks, etc., that can have both regional and global aspects. Spatial discourse analysis rely on geographical data. However, today less than 1% of tweets are geotagged; in both cases--point location or bounding place information. A major issue with tweets is that Twitter users can be at location A and exchange conversations specific to location B, which we call the Location A/B problem. The problem is considered solved if location entities can be classified as either origin locations (Location As) or non-origin locations (Location Bs). In this work, we propose a simple yet effective framework--the True Origin Model--to address the problem that uses machine-level natural language understanding to identify tweets that conceivably contain their origin location information. The model achieves promising accuracy at country (80%), state (67%), city (58%), county (56%) and district (64%) levels with support from a Location Extraction Model as basic as the CoNLL-2003-based RoBERTa. We employ a tweet contexualizer (locBERT) which is one of the core components of the proposed model, to investigate multiple tweets' distributions for understanding Twitter users' tweeting behavior in terms of mentioning origin and non-origin locations. We also highlight a major concern with the currently regarded gold standard test set (ground truth) methodology, introduce a new data set, and identify further research avenues for advancing the area.
Socially Enhanced Situation Awareness from Microblogs using Artificial Intelligence: A Survey
Sep 13, 2022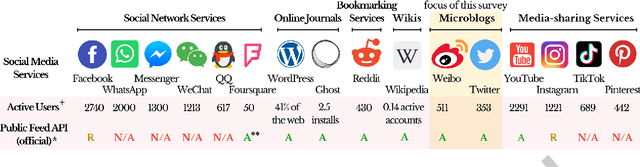
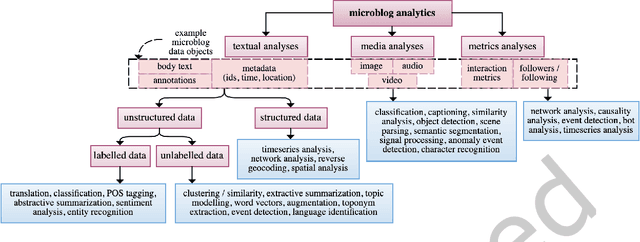
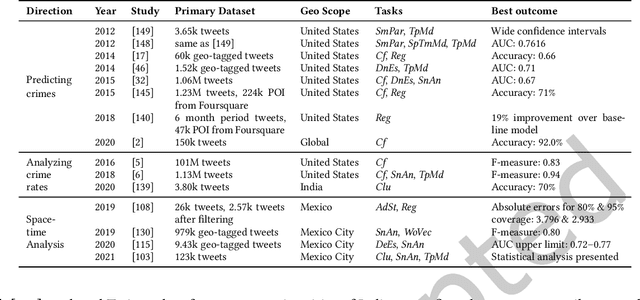
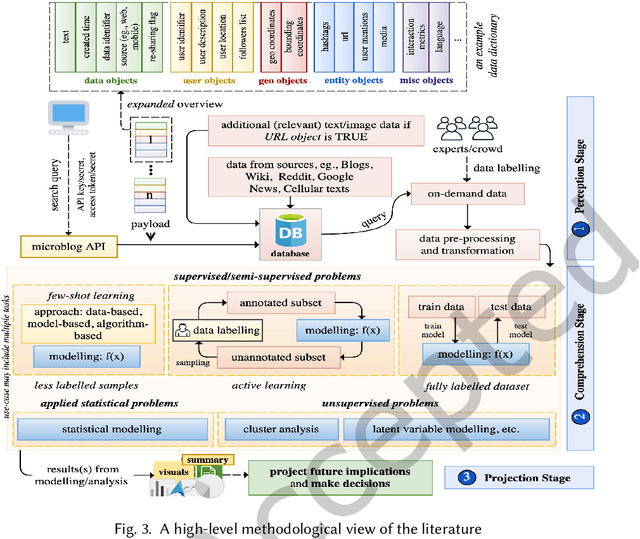
The rise of social media platforms provides an unbounded, infinitely rich source of aggregate knowledge of the world around us, both historic and real-time, from a human perspective. The greatest challenge we face is how to process and understand this raw and unstructured data, go beyond individual observations and see the "big picture"--the domain of Situation Awareness. We provide an extensive survey of Artificial Intelligence research, focusing on microblog social media data with applications to Situation Awareness, that gives the seminal work and state-of-the-art approaches across six thematic areas: Crime, Disasters, Finance, Physical Environment, Politics, and Health and Population. We provide a novel, unified methodological perspective, identify key results and challenges, and present ongoing research directions.
Twitter conversations predict the daily confirmed COVID-19 cases
Jun 21, 2022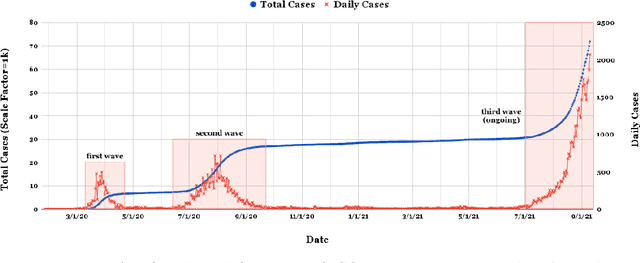
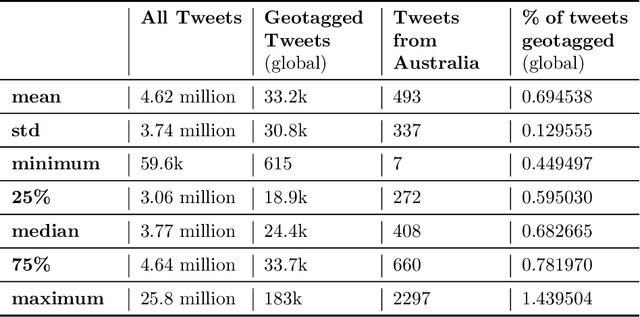
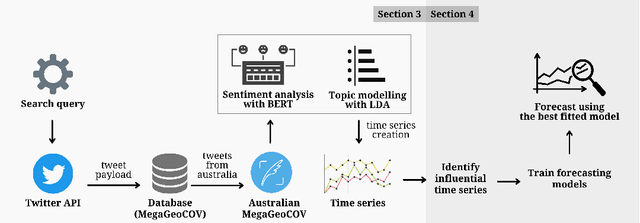
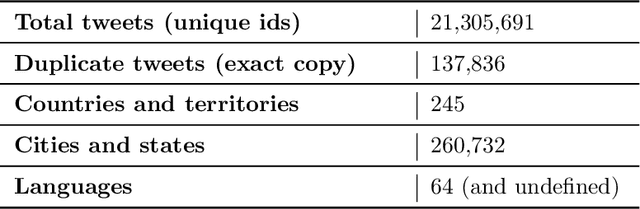
As of writing this paper, COVID-19 (Coronavirus disease 2019) has spread to more than 220 countries and territories. Following the outbreak, the pandemic's seriousness has made people more active on social media, especially on the microblogging platforms such as Twitter and Weibo. The pandemic-specific discourse has remained on-trend on these platforms for months now. Previous studies have confirmed the contributions of such socially generated conversations towards situational awareness of crisis events. The early forecasts of cases are essential to authorities to estimate the requirements of resources needed to cope with the outgrowths of the virus. Therefore, this study attempts to incorporate the public discourse in the design of forecasting models particularly targeted for the steep-hill region of an ongoing wave. We propose a sentiment-involved topic-based methodology for designing multiple time series from publicly available COVID-19 related Twitter conversations. As a use case, we implement the proposed methodology on Australian COVID-19 daily cases and Twitter conversations generated within the country. Experimental results: (i) show the presence of latent social media variables that Granger-cause the daily COVID-19 confirmed cases, and (ii) confirm that those variables offer additional prediction capability to forecasting models. Further, the results show that the inclusion of social media variables for modeling introduces 48.83--51.38% improvements on RMSE over the baseline models. We also release the large-scale COVID-19 specific geotagged global tweets dataset, MegaGeoCOV, to the public anticipating that the geotagged data of this scale would aid in understanding the conversational dynamics of the pandemic through other spatial and temporal contexts.
Real-time Spatio-temporal Event Detection on Geotagged Social Media
Jun 23, 2021
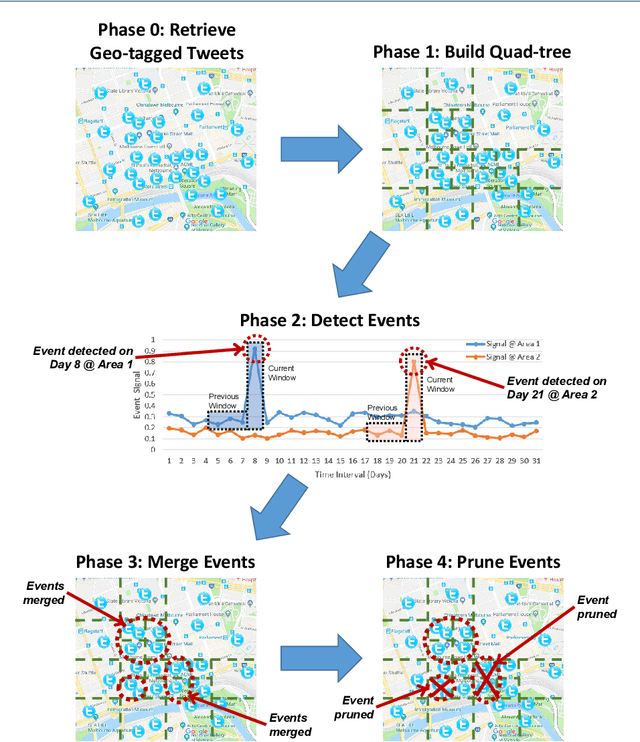


A key challenge in mining social media data streams is to identify events which are actively discussed by a group of people in a specific local or global area. Such events are useful for early warning for accident, protest, election or breaking news. However, neither the list of events nor the resolution of both event time and space is fixed or known beforehand. In this work, we propose an online spatio-temporal event detection system using social media that is able to detect events at different time and space resolutions. First, to address the challenge related to the unknown spatial resolution of events, a quad-tree method is exploited in order to split the geographical space into multiscale regions based on the density of social media data. Then, a statistical unsupervised approach is performed that involves Poisson distribution and a smoothing method for highlighting regions with unexpected density of social posts. Further, event duration is precisely estimated by merging events happening in the same region at consecutive time intervals. A post processing stage is introduced to filter out events that are spam, fake or wrong. Finally, we incorporate simple semantics by using social media entities to assess the integrity, and accuracy of detected events. The proposed method is evaluated using different social media datasets: Twitter and Flickr for different cities: Melbourne, London, Paris and New York. To verify the effectiveness of the proposed method, we compare our results with two baseline algorithms based on fixed split of geographical space and clustering method. For performance evaluation, we manually compute recall and precision. We also propose a new quality measure named strength index, which automatically measures how accurate the reported event is.
User Identification across Social Networking Sites using User Profiles and Posting Patterns
Jun 22, 2021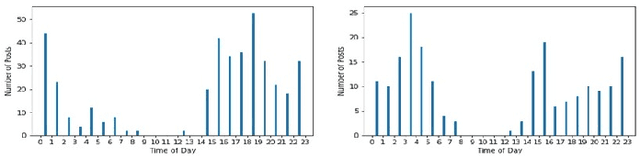
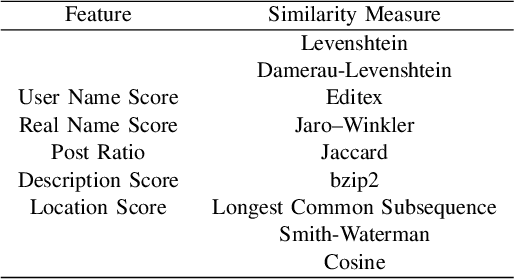

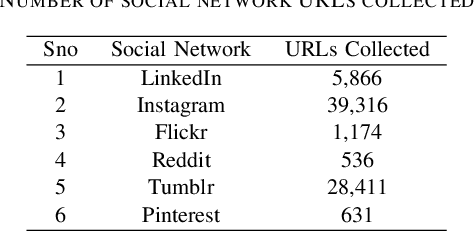
With the prevalence of online social networking sites (OSNs) and mobile devices, people are increasingly reliant on a variety of OSNs for keeping in touch with family and friends, and using it as a source of information. For example, a user might utilise multiple OSNs for different purposes, such as using Flickr to share holiday pictures with family and friends, and Twitter to post short messages about their thoughts. Identifying the same user across multiple OSNs is an important task as this allows us to understand the usage patterns of users among different OSNs, make recommendations when a user registers for a new OSN, and various other useful applications. To address this problem, we proposed an algorithm based on the multilayer perceptron using various types of features, namely: (i) user profile, such as name, location, description; (ii) temporal distribution of user generated content; and (iii) embedding based on user name, real name and description. Using a Twitter and Flickr dataset of users and their posting activities, we perform an empirical study on how these features affect the performance of user identification across the two OSNs and discuss our main findings based on the different features.
Geometry of Interest (GOI): Spatio-Temporal Destination Extraction and Partitioning in GPS Trajectory Data
May 16, 2016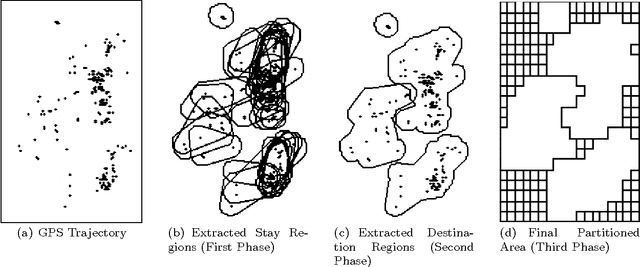
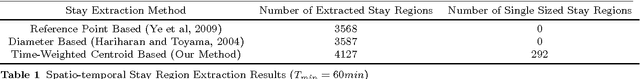
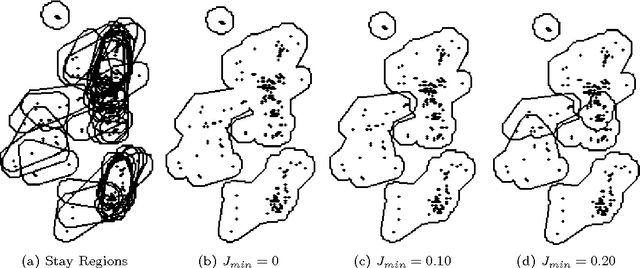
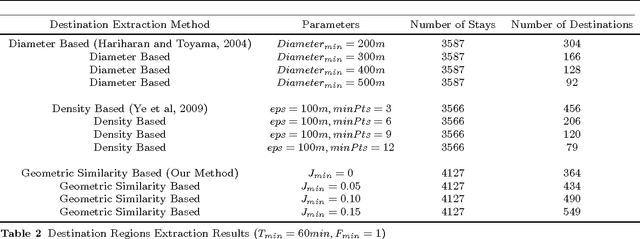
Nowadays large amounts of GPS trajectory data is being continuously collected by GPS-enabled devices such as vehicles navigation systems and mobile phones. GPS trajectory data is useful for applications such as traffic management, location forecasting, and itinerary planning. Such applications often need to extract the time-stamped Sequence of Visited Locations (SVLs) of the mobile objects. The nearest neighbor query (NNQ) is the most applied method for labeling the visited locations based on the IDs of the POIs in the process of SVL generation. NNQ in some scenarios is not accurate enough. To improve the quality of the extracted SVLs, instead of using NNQ, we label the visited locations as the IDs of the POIs which geometrically intersect with the GPS observations. Intersection operator requires the accurate geometry of the points of interest which we refer to them as the Geometries of Interest (GOIs). In some application domains (e.g. movement trajectories of animals), adequate information about the POIs and their GOIs may not be available a priori, or they may not be publicly accessible and, therefore, they need to be derived from GPS trajectory data. In this paper we propose a novel method for estimating the POIs and their GOIs, which consists of three phases: (i) extracting the geometries of the stay regions; (ii) constructing the geometry of destination regions based on the extracted stay regions; and (iii) constructing the GOIs based on the geometries of the destination regions. Using the geometric similarity to known GOIs as the major evaluation criterion, the experiments we performed using long-term GPS trajectory data show that our method outperforms the existing approaches.