 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGAlign-Rec: Ranking-Guided Alignment for Latent Query Reasoning in Recommendation Systems
Feb 13, 2026Proactive intent prediction is a critical capability in modern e-commerce chatbots, enabling "zero-query" recommendations by anticipating user needs from behavioral and contextual signals. However, existing industrial systems face two fundamental challenges: (1) the semantic gap between discrete user features and the semantic intents within the chatbot's Knowledge Base, and (2) the objective misalignment between general-purpose LLM outputs and task-specific ranking utilities. To address these issues, we propose RGAlign-Rec, a closed-loop alignment framework that integrates an LLM-based semantic reasoner with a Query-Enhanced (QE) ranking model. We also introduce Ranking-Guided Alignment (RGA), a multi-stage training paradigm that utilizes downstream ranking signals as feedback to refine the LLM's latent reasoning. Extensive experiments on a large-scale industrial dataset from Shopee demonstrate that RGAlign-Rec achieves a 0.12% gain in GAUC, leading to a significant 3.52% relative reduction in error rate, and a 0.56% improvement in Recall@3. Online A/B testing further validates the cumulative effectiveness of our framework: the Query-Enhanced model (QE-Rec) initially yields a 0.98% improvement in CTR, while the subsequent Ranking-Guided Alignment stage contributes an additional 0.13% gain. These results indicate that ranking-aware alignment effectively synchronizes semantic reasoning with ranking objectives, significantly enhancing both prediction accuracy and service quality in real-world proactive recommendation systems.
HyMoERec: Hybrid Mixture-of-Experts for Sequential Recommendation
Nov 09, 2025We propose HyMoERec, a novel sequential recommendation framework that addresses the limitations of uniform Position-wise Feed-Forward Networks in existing models. Current approaches treat all user interactions and items equally, overlooking the heterogeneity in user behavior patterns and diversity in item complexity. HyMoERec initially introduces a hybrid mixture-of-experts architecture that combines shared and specialized expert branches with an adaptive expert fusion mechanism for the sequential recommendation task. This design captures diverse reasoning for varied users and items while ensuring stable training. Experiments on MovieLens-1M and Beauty datasets demonstrate that HyMoERec consistently outperforms state-of-the-art baselines.
Get Global Guarantees: On the Probabilistic Nature of Perturbation Robustness
Aug 26, 2025In safety-critical deep learning applications, robustness measures the ability of neural models that handle imperceptible perturbations in input data, which may lead to potential safety hazards. Existing pre-deployment robustness assessment methods typically suffer from significant trade-offs between computational cost and measurement precision, limiting their practical utility. To address these limitations, this paper conducts a comprehensive comparative analysis of existing robustness definitions and associated assessment methodologies. We propose tower robustness to evaluate robustness, which is a novel, practical metric based on hypothesis testing to quantitatively evaluate probabilistic robustness, enabling more rigorous and efficient pre-deployment assessments. Our extensive comparative evaluation illustrates the advantages and applicability of our proposed approach, thereby advancing the systematic understanding and enhancement of model robustness in safety-critical deep learning applications.
BGM-HAN: A Hierarchical Attention Network for Accurate and Fair Decision Assessment on Semi-Structured Profiles
Jul 23, 2025Human decision-making in high-stakes domains often relies on expertise and heuristics, but is vulnerable to hard-to-detect cognitive biases that threaten fairness and long-term outcomes. This work presents a novel approach to enhancing complex decision-making workflows through the integration of hierarchical learning alongside various enhancements. Focusing on university admissions as a representative high-stakes domain, we propose BGM-HAN, an enhanced Byte-Pair Encoded, Gated Multi-head Hierarchical Attention Network, designed to effectively model semi-structured applicant data. BGM-HAN captures multi-level representations that are crucial for nuanced assessment, improving both interpretability and predictive performance. Experimental results on real admissions data demonstrate that our proposed model significantly outperforms both state-of-the-art baselines from traditional machine learning to large language models, offering a promising framework for augmenting decision-making in domains where structure, context, and fairness matter. Source code is available at: https://github.com/junhua/bgm-han.
Fairness And Performance In Harmony: Data Debiasing Is All You Need
Nov 26, 2024



Fairness in both machine learning (ML) predictions and human decisions is critical, with ML models prone to algorithmic and data bias, and human decisions affected by subjectivity and cognitive bias. This study investigates fairness using a real-world university admission dataset with 870 profiles, leveraging three ML models, namely XGB, Bi-LSTM, and KNN. Textual features are encoded with BERT embeddings. For individual fairness, we assess decision consistency among experts with varied backgrounds and ML models, using a consistency score. Results show ML models outperform humans in fairness by 14.08% to 18.79%. For group fairness, we propose a gender-debiasing pipeline and demonstrate its efficacy in removing gender-specific language without compromising prediction performance. Post-debiasing, all models maintain or improve their classification accuracy, validating the hypothesis that fairness and performance can coexist. Our findings highlight ML's potential to enhance fairness in admissions while maintaining high accuracy, advocating a hybrid approach combining human judgement and ML models.
Intent-Aware Dialogue Generation and Multi-Task Contrastive Learning for Multi-Turn Intent Classification
Nov 21, 2024
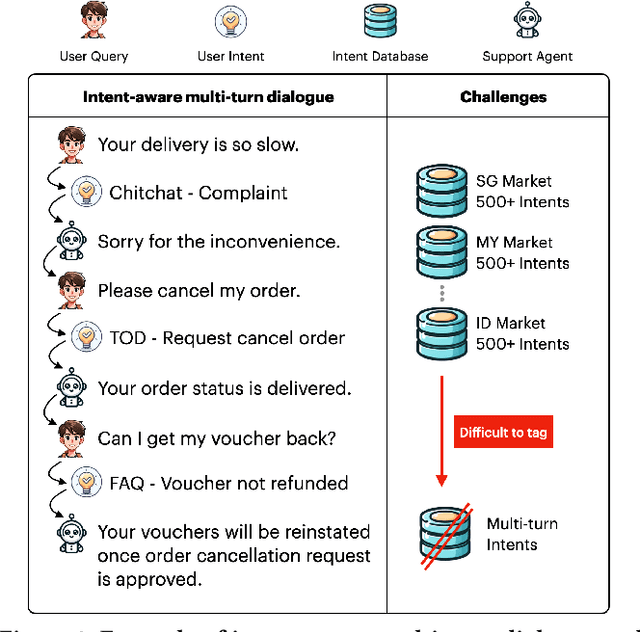

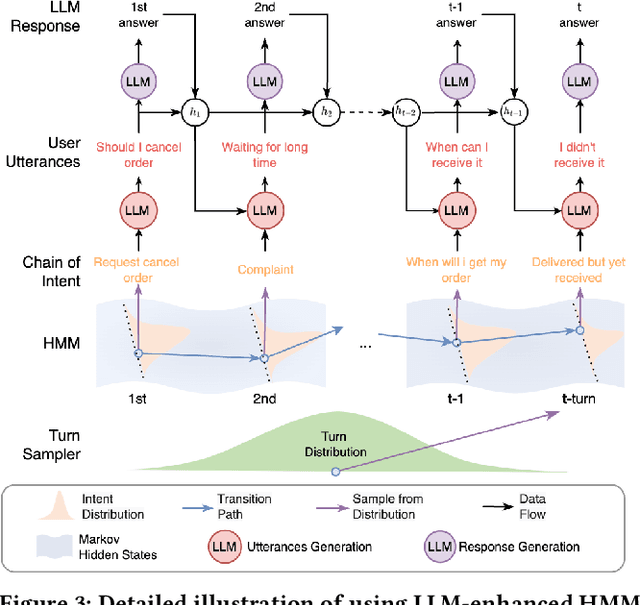
Generating large-scale, domain-specific, multilingual multi-turn dialogue datasets remains a significant hurdle for training effective Multi-Turn Intent Classification models in chatbot systems. In this paper, we introduce Chain-of-Intent, a novel mechanism that combines Hidden Markov Models with Large Language Models (LLMs) to generate contextually aware, intent-driven conversations through self-play. By extracting domain-specific knowledge from e-commerce chat logs, we estimate conversation turns and intent transitions, which guide the generation of coherent dialogues. Leveraging LLMs to enhance emission probabilities, our approach produces natural and contextually consistent questions and answers. We also propose MINT-CL, a framework for multi-turn intent classification using multi-task contrastive learning, improving classification accuracy without the need for extensive annotated data. Evaluations show that our methods outperform baselines in dialogue quality and intent classification accuracy, especially in multilingual settings, while significantly reducing data generation efforts. Furthermore, we release MINT-E, a multilingual, intent-aware multi-turn e-commerce dialogue corpus to support future research in this area.
Physics-Informed LLM-Agent for Automated Modulation Design in Power Electronics Systems
Nov 21, 2024



LLM-based autonomous agents have demonstrated outstanding performance in solving complex industrial tasks. However, in the pursuit of carbon neutrality and high-performance renewable energy systems, existing AI-assisted design automation faces significant limitations in explainability, scalability, and usability. To address these challenges, we propose LP-COMDA, an LLM-based, physics-informed autonomous agent that automates the modulation design of power converters in Power Electronics Systems with minimal human supervision. Unlike traditional AI-assisted approaches, LP-COMDA contains an LLM-based planner that gathers and validates design specifications through a user-friendly chat interface. The planner then coordinates with physics-informed design and optimization tools to iteratively generate and refine modulation designs autonomously. Through the chat interface, LP-COMDA provides an explainable design process, presenting explanations and charts. Experiments show that LP-COMDA outperforms all baseline methods, achieving a 63.2% reduction in error compared to the second-best benchmark method in terms of standard mean absolute error. Furthermore, empirical studies with 20 experts conclude that design time with LP-COMDA is over 33 times faster than conventional methods, showing its significant improvement on design efficiency over the current processes.
Balancing Accuracy and Efficiency in Multi-Turn Intent Classification for LLM-Powered Dialog Systems in Production
Nov 19, 2024



Accurate multi-turn intent classification is essential for advancing conversational AI systems. However, challenges such as the scarcity of comprehensive datasets and the complexity of contextual dependencies across dialogue turns hinder progress. This paper presents two novel approaches leveraging Large Language Models (LLMs) to enhance scalability and reduce latency in production dialogue systems. First, we introduce Symbol Tuning, which simplifies intent labels to reduce task complexity and improve performance in multi-turn dialogues. Second, we propose C-LARA (Consistency-aware, Linguistics Adaptive Retrieval Augmentation), a framework that employs LLMs for data augmentation and pseudo-labeling to generate synthetic multi-turn dialogues. These enriched datasets are used to fine-tune a small, efficient model suitable for deployment. Experiments conducted on multilingual dialogue datasets demonstrate significant improvements in classification accuracy and resource efficiency. Our methods enhance multi-turn intent classification accuracy by 5.09%, reduce annotation costs by 40%, and enable scalable deployment in low-resource multilingual industrial systems, highlighting their practicality and impact.
Towards Objective and Unbiased Decision Assessments with LLM-Enhanced Hierarchical Attention Networks
Nov 14, 2024



How objective and unbiased are we while making decisions? This work investigates cognitive bias identification in high-stake decision making process by human experts, questioning its effectiveness in real-world settings, such as candidates assessments for university admission. We begin with a statistical analysis assessing correlations among different decision points among in the current process, which discovers discrepancies that imply cognitive bias and inconsistency in decisions. This motivates our exploration of bias-aware AI-augmented workflow that surpass human judgment. We propose BGM-HAN, an enhanced Hierarchical Attention Network with Byte-Pair Encoding, Gated Residual Connections and Multi-Head Attention. Using it as a backbone model, we further propose a Shortlist-Analyse-Recommend (SAR) agentic workflow, which simulate real-world decision-making. In our experiments, both the proposed model and the agentic workflow significantly improves on both human judgment and alternative models, validated with real-world data.
Enhancing Language Models for Financial Relation Extraction with Named Entities and Part-of-Speech
May 02, 2024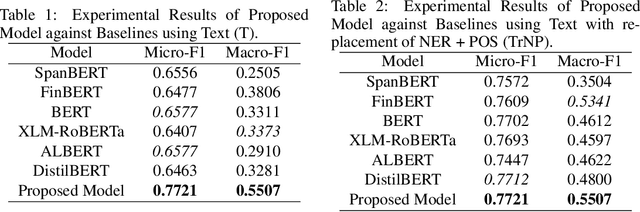
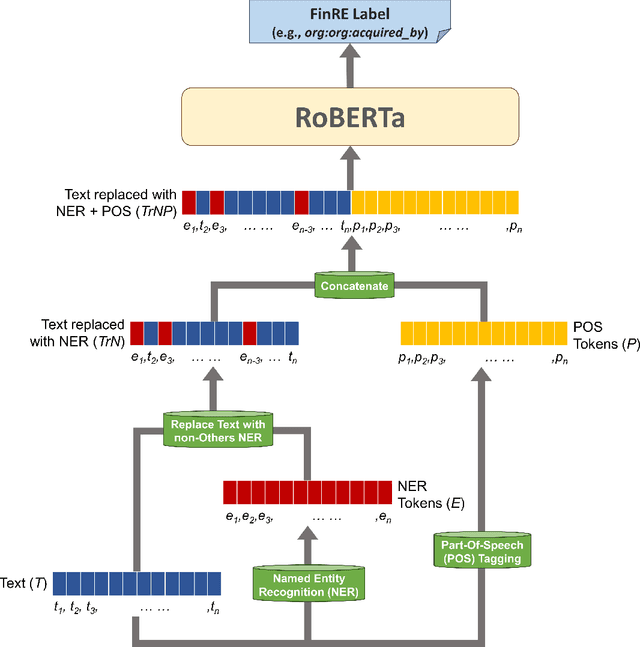
The Financial Relation Extraction (FinRE) task involves identifying the entities and their relation, given a piece of financial statement/text. To solve this FinRE problem, we propose a simple but effective strategy that improves the performance of pre-trained language models by augmenting them with Named Entity Recognition (NER) and Part-Of-Speech (POS), as well as different approaches to combine these information. Experiments on a financial relations dataset show promising results and highlights the benefits of incorporating NER and POS in existing models. Our dataset and codes are available at https://github.com/kwanhui/FinRelExtract.