 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Precise Observations of Neural Model Robustness in Classification
Paper and Code
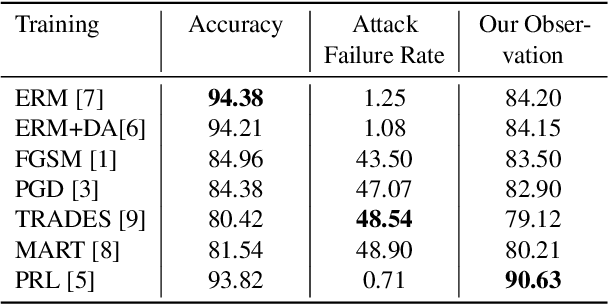
In deep learning applications, robustness measures the ability of neural models that handle slight changes in input data, which could lead to potential safety hazards, especially in safety-critical applications. Pre-deployment assessment of model robustness is essential, but existing methods often suffer from either high costs or imprecise results. To enhance safety in real-world scenarios, metrics that effectively capture the model's robustness are needed. To address this issue, we compare the rigour and usage conditions of various assessment methods based on different definitions. Then, we propose a straightforward and practical metric utilizing hypothesis testing for probabilistic robustness and have integrated it into the TorchAttacks library. Through a comparative analysis of diverse robustness assessment methods, our approach contributes to a deeper understanding of model robustness in safety-critical applications.