 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGet Global Guarantees: On the Probabilistic Nature of Perturbation Robustness
Aug 26, 2025In safety-critical deep learning applications, robustness measures the ability of neural models that handle imperceptible perturbations in input data, which may lead to potential safety hazards. Existing pre-deployment robustness assessment methods typically suffer from significant trade-offs between computational cost and measurement precision, limiting their practical utility. To address these limitations, this paper conducts a comprehensive comparative analysis of existing robustness definitions and associated assessment methodologies. We propose tower robustness to evaluate robustness, which is a novel, practical metric based on hypothesis testing to quantitatively evaluate probabilistic robustness, enabling more rigorous and efficient pre-deployment assessments. Our extensive comparative evaluation illustrates the advantages and applicability of our proposed approach, thereby advancing the systematic understanding and enhancement of model robustness in safety-critical deep learning applications.
Label-Free Topic-Focused Summarization Using Query Augmentation
Apr 25, 2024In today's data and information-rich world, summarization techniques are essential in harnessing vast text to extract key information and enhance decision-making and efficiency. In particular, topic-focused summarization is important due to its ability to tailor content to specific aspects of an extended text. However, this usually requires extensive labelled datasets and considerable computational power. This study introduces a novel method, Augmented-Query Summarization (AQS), for topic-focused summarization without the need for extensive labelled datasets, leveraging query augmentation and hierarchical clustering. This approach facilitates the transferability of machine learning models to the task of summarization, circumventing the need for topic-specific training. Through real-world tests, our method demonstrates the ability to generate relevant and accurate summaries, showing its potential as a cost-effective solution in data-rich environments. This innovation paves the way for broader application and accessibility in the field of topic-focused summarization technology, offering a scalable, efficient method for personalized content extraction.
Towards Precise Observations of Neural Model Robustness in Classification
Apr 25, 2024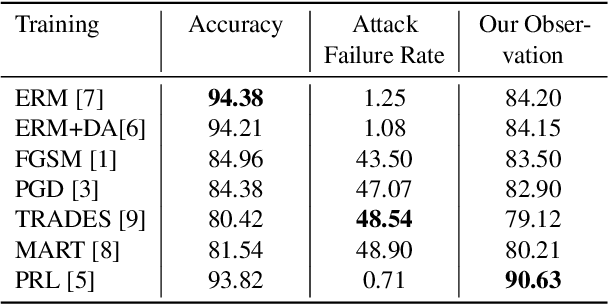
In deep learning applications, robustness measures the ability of neural models that handle slight changes in input data, which could lead to potential safety hazards, especially in safety-critical applications. Pre-deployment assessment of model robustness is essential, but existing methods often suffer from either high costs or imprecise results. To enhance safety in real-world scenarios, metrics that effectively capture the model's robustness are needed. To address this issue, we compare the rigour and usage conditions of various assessment methods based on different definitions. Then, we propose a straightforward and practical metric utilizing hypothesis testing for probabilistic robustness and have integrated it into the TorchAttacks library. Through a comparative analysis of diverse robustness assessment methods, our approach contributes to a deeper understanding of model robustness in safety-critical applications.
Similarity between Units of Natural Language: The Transition from Coarse to Fine Estimation
Oct 25, 2022Capturing the similarities between human language units is crucial for explaining how humans associate different objects, and therefore its computation has received extensive attention, research, and applications. With the ever-increasing amount of information around us, calculating similarity becomes increasingly complex, especially in many cases, such as legal or medical affairs, measuring similarity requires extra care and precision, as small acts within a language unit can have significant real-world effects. My research goal in this thesis is to develop regression models that account for similarities between language units in a more refined way. Computation of similarity has come a long way, but approaches to debugging the measures are often based on continually fitting human judgment values. To this end, my goal is to develop an algorithm that precisely catches loopholes in a similarity calculation. Furthermore, most methods have vague definitions of the similarities they compute and are often difficult to interpret. The proposed framework addresses both shortcomings. It constantly improves the model through catching different loopholes. In addition, every refinement of the model provides a reasonable explanation. The regression model introduced in this thesis is called progressively refined similarity computation, which combines attack testing with adversarial training. The similarity regression model of this thesis achieves state-of-the-art performance in handling edge cases.
Universal Evasion Attacks on Summarization Scoring
Oct 25, 2022The automatic scoring of summaries is important as it guides the development of summarizers. Scoring is also complex, as it involves multiple aspects such as fluency, grammar, and even textual entailment with the source text. However, summary scoring has not been considered a machine learning task to study its accuracy and robustness. In this study, we place automatic scoring in the context of regression machine learning tasks and perform evasion attacks to explore its robustness. Attack systems predict a non-summary string from each input, and these non-summary strings achieve competitive scores with good summarizers on the most popular metrics: ROUGE, METEOR, and BERTScore. Attack systems also "outperform" state-of-the-art summarization methods on ROUGE-1 and ROUGE-L, and score the second-highest on METEOR. Furthermore, a BERTScore backdoor is observed: a simple trigger can score higher than any automatic summarization method. The evasion attacks in this work indicate the low robustness of current scoring systems at the system level. We hope that our highlighting of these proposed attacks will facilitate the development of summary scores.
Revision for Concision: A Constrained Paraphrase Generation Task
Oct 25, 2022



Academic writing should be concise as concise sentences better keep the readers' attention and convey meaning clearly. Writing concisely is challenging, for writers often struggle to revise their drafts. We introduce and formulate revising for concision as a natural language processing task at the sentence level. Revising for concision requires algorithms to use only necessary words to rewrite a sentence while preserving its meaning. The revised sentence should be evaluated according to its word choice, sentence structure, and organization. The revised sentence also needs to fulfil semantic retention and syntactic soundness. To aide these efforts, we curate and make available a benchmark parallel dataset that can depict revising for concision. The dataset contains 536 pairs of sentences before and after revising, and all pairs are collected from college writing centres. We also present and evaluate the approaches to this problem, which may assist researchers in this area.