 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPSL: Representing Volumetric Video via Content-Promoted Scene Layers
Nov 18, 2025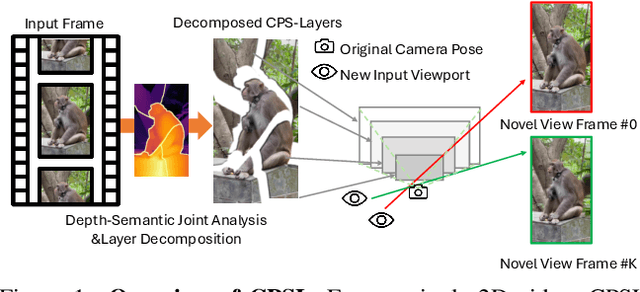

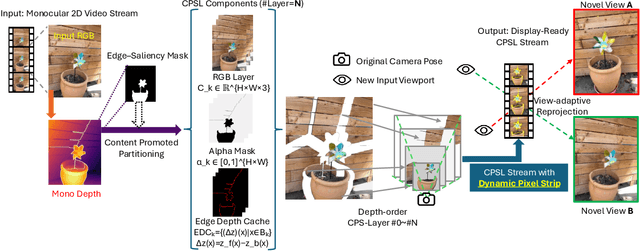
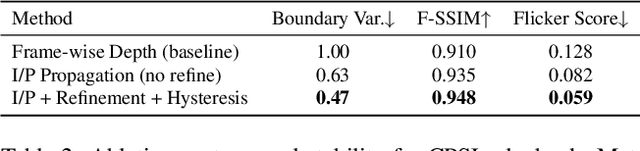
Volumetric video enables immersive and interactive visual experiences by supporting free viewpoint exploration and realistic motion parallax. However, existing volumetric representations from explicit point clouds to implicit neural fields, remain costly in capture, computation, and rendering, which limits their scalability for on-demand video and reduces their feasibility for real-time communication. To bridge this gap, we propose Content-Promoted Scene Layers (CPSL), a compact 2.5D video representation that brings the perceptual benefits of volumetric video to conventional 2D content. Guided by per-frame depth and content saliency, CPSL decomposes each frame into a small set of geometry-consistent layers equipped with soft alpha bands and an edge-depth cache that jointly preserve occlusion ordering and boundary continuity. These lightweight, 2D-encodable assets enable parallax-corrected novel-view synthesis via depth-weighted warping and front-to-back alpha compositing, bypassing expensive 3D reconstruction. Temporally, CPSL maintains inter-frame coherence using motion-guided propagation and per-layer encoding, supporting real-time playback with standard video codecs. Across multiple benchmarks, CPSL achieves superior perceptual quality and boundary fidelity compared with layer-based and neural-field baselines while reducing storage and rendering cost by several folds. Our approach offer a practical path from 2D video to scalable 2.5D immersive media.
ForgeDAN: An Evolutionary Framework for Jailbreaking Aligned Large Language Models
Nov 17, 2025



The rapid adoption of large language models (LLMs) has brought both transformative applications and new security risks, including jailbreak attacks that bypass alignment safeguards to elicit harmful outputs. Existing automated jailbreak generation approaches e.g. AutoDAN, suffer from limited mutation diversity, shallow fitness evaluation, and fragile keyword-based detection. To address these limitations, we propose ForgeDAN, a novel evolutionary framework for generating semantically coherent and highly effective adversarial prompts against aligned LLMs. First, ForgeDAN introduces multi-strategy textual perturbations across \textit{character, word, and sentence-level} operations to enhance attack diversity; then we employ interpretable semantic fitness evaluation based on a text similarity model to guide the evolutionary process toward semantically relevant and harmful outputs; finally, ForgeDAN integrates dual-dimensional jailbreak judgment, leveraging an LLM-based classifier to jointly assess model compliance and output harmfulness, thereby reducing false positives and improving detection effectiveness. Our evaluation demonstrates ForgeDAN achieves high jailbreaking success rates while maintaining naturalness and stealth, outperforming existing SOTA solutions.
BGM-HAN: A Hierarchical Attention Network for Accurate and Fair Decision Assessment on Semi-Structured Profiles
Jul 23, 2025Human decision-making in high-stakes domains often relies on expertise and heuristics, but is vulnerable to hard-to-detect cognitive biases that threaten fairness and long-term outcomes. This work presents a novel approach to enhancing complex decision-making workflows through the integration of hierarchical learning alongside various enhancements. Focusing on university admissions as a representative high-stakes domain, we propose BGM-HAN, an enhanced Byte-Pair Encoded, Gated Multi-head Hierarchical Attention Network, designed to effectively model semi-structured applicant data. BGM-HAN captures multi-level representations that are crucial for nuanced assessment, improving both interpretability and predictive performance. Experimental results on real admissions data demonstrate that our proposed model significantly outperforms both state-of-the-art baselines from traditional machine learning to large language models, offering a promising framework for augmenting decision-making in domains where structure, context, and fairness matter. Source code is available at: https://github.com/junhua/bgm-han.
Fairness And Performance In Harmony: Data Debiasing Is All You Need
Nov 26, 2024



Fairness in both machine learning (ML) predictions and human decisions is critical, with ML models prone to algorithmic and data bias, and human decisions affected by subjectivity and cognitive bias. This study investigates fairness using a real-world university admission dataset with 870 profiles, leveraging three ML models, namely XGB, Bi-LSTM, and KNN. Textual features are encoded with BERT embeddings. For individual fairness, we assess decision consistency among experts with varied backgrounds and ML models, using a consistency score. Results show ML models outperform humans in fairness by 14.08% to 18.79%. For group fairness, we propose a gender-debiasing pipeline and demonstrate its efficacy in removing gender-specific language without compromising prediction performance. Post-debiasing, all models maintain or improve their classification accuracy, validating the hypothesis that fairness and performance can coexist. Our findings highlight ML's potential to enhance fairness in admissions while maintaining high accuracy, advocating a hybrid approach combining human judgement and ML models.
Physics-Informed LLM-Agent for Automated Modulation Design in Power Electronics Systems
Nov 21, 2024



LLM-based autonomous agents have demonstrated outstanding performance in solving complex industrial tasks. However, in the pursuit of carbon neutrality and high-performance renewable energy systems, existing AI-assisted design automation faces significant limitations in explainability, scalability, and usability. To address these challenges, we propose LP-COMDA, an LLM-based, physics-informed autonomous agent that automates the modulation design of power converters in Power Electronics Systems with minimal human supervision. Unlike traditional AI-assisted approaches, LP-COMDA contains an LLM-based planner that gathers and validates design specifications through a user-friendly chat interface. The planner then coordinates with physics-informed design and optimization tools to iteratively generate and refine modulation designs autonomously. Through the chat interface, LP-COMDA provides an explainable design process, presenting explanations and charts. Experiments show that LP-COMDA outperforms all baseline methods, achieving a 63.2% reduction in error compared to the second-best benchmark method in terms of standard mean absolute error. Furthermore, empirical studies with 20 experts conclude that design time with LP-COMDA is over 33 times faster than conventional methods, showing its significant improvement on design efficiency over the current processes.
Intent-Aware Dialogue Generation and Multi-Task Contrastive Learning for Multi-Turn Intent Classification
Nov 21, 2024
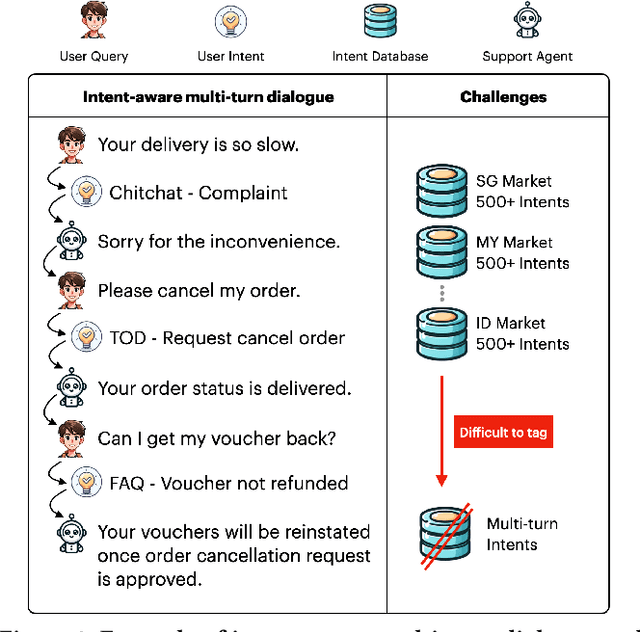

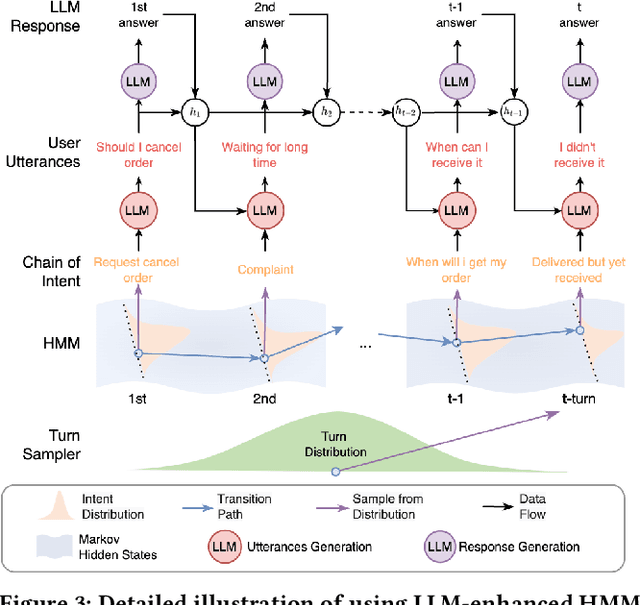
Generating large-scale, domain-specific, multilingual multi-turn dialogue datasets remains a significant hurdle for training effective Multi-Turn Intent Classification models in chatbot systems. In this paper, we introduce Chain-of-Intent, a novel mechanism that combines Hidden Markov Models with Large Language Models (LLMs) to generate contextually aware, intent-driven conversations through self-play. By extracting domain-specific knowledge from e-commerce chat logs, we estimate conversation turns and intent transitions, which guide the generation of coherent dialogues. Leveraging LLMs to enhance emission probabilities, our approach produces natural and contextually consistent questions and answers. We also propose MINT-CL, a framework for multi-turn intent classification using multi-task contrastive learning, improving classification accuracy without the need for extensive annotated data. Evaluations show that our methods outperform baselines in dialogue quality and intent classification accuracy, especially in multilingual settings, while significantly reducing data generation efforts. Furthermore, we release MINT-E, a multilingual, intent-aware multi-turn e-commerce dialogue corpus to support future research in this area.
Balancing Accuracy and Efficiency in Multi-Turn Intent Classification for LLM-Powered Dialog Systems in Production
Nov 19, 2024



Accurate multi-turn intent classification is essential for advancing conversational AI systems. However, challenges such as the scarcity of comprehensive datasets and the complexity of contextual dependencies across dialogue turns hinder progress. This paper presents two novel approaches leveraging Large Language Models (LLMs) to enhance scalability and reduce latency in production dialogue systems. First, we introduce Symbol Tuning, which simplifies intent labels to reduce task complexity and improve performance in multi-turn dialogues. Second, we propose C-LARA (Consistency-aware, Linguistics Adaptive Retrieval Augmentation), a framework that employs LLMs for data augmentation and pseudo-labeling to generate synthetic multi-turn dialogues. These enriched datasets are used to fine-tune a small, efficient model suitable for deployment. Experiments conducted on multilingual dialogue datasets demonstrate significant improvements in classification accuracy and resource efficiency. Our methods enhance multi-turn intent classification accuracy by 5.09%, reduce annotation costs by 40%, and enable scalable deployment in low-resource multilingual industrial systems, highlighting their practicality and impact.
Towards Objective and Unbiased Decision Assessments with LLM-Enhanced Hierarchical Attention Networks
Nov 14, 2024



How objective and unbiased are we while making decisions? This work investigates cognitive bias identification in high-stake decision making process by human experts, questioning its effectiveness in real-world settings, such as candidates assessments for university admission. We begin with a statistical analysis assessing correlations among different decision points among in the current process, which discovers discrepancies that imply cognitive bias and inconsistency in decisions. This motivates our exploration of bias-aware AI-augmented workflow that surpass human judgment. We propose BGM-HAN, an enhanced Hierarchical Attention Network with Byte-Pair Encoding, Gated Residual Connections and Multi-Head Attention. Using it as a backbone model, we further propose a Shortlist-Analyse-Recommend (SAR) agentic workflow, which simulate real-world decision-making. In our experiments, both the proposed model and the agentic workflow significantly improves on both human judgment and alternative models, validated with real-world data.
Responsible Multilingual Large Language Models: A Survey of Development, Applications, and Societal Impact
Oct 23, 2024

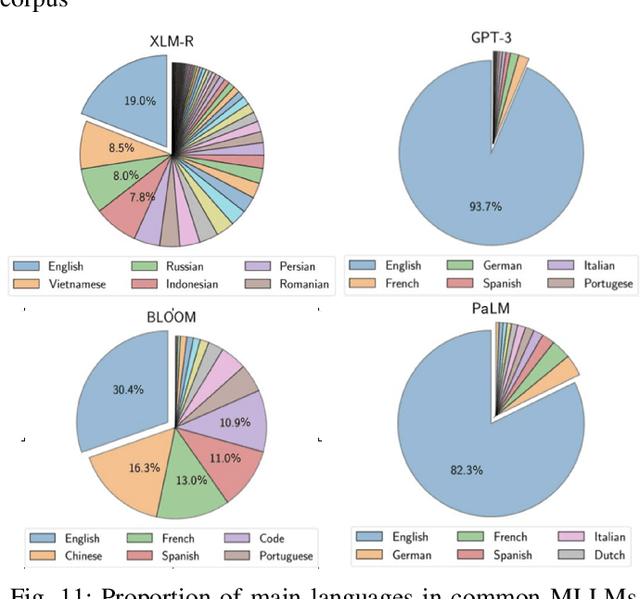

Multilingual Large Language Models (MLLMs) represent a pivotal advancement in democratizing artificial intelligence across linguistic boundaries. While theoretical foundations are well-established, practical implementation guidelines remain scattered. This work bridges this gap by providing a comprehensive end-to-end framework for developing and deploying MLLMs in production environments. We make three distinctive contributions: First, we present an actionable pipeline from data pre-processing through deployment, integrating insights from academic research and industrial applications. Second, using Llama2 as a case study, we provide detailed optimization strategies for enhancing multilingual capabilities, including curriculum learning approaches for balancing high-resource and low-resource languages, tokenization strategies, and effective sampling methods. Third, we offer an interdisciplinary analysis that considers technical, linguistic, and cultural perspectives in MLLM development. Our findings reveal critical challenges in supporting linguistic diversity, with 88.38% of world languages categorized as low-resource, affecting over a billion speakers. We examine practical solutions through real-world applications in customer service, search engines, and machine translation. By synthesizing theoretical frameworks with production-ready implementation strategies, this survey provides essential guidance for practitioners and researchers working to develop more inclusive and effective multilingual AI systems.
Math-LLaVA: Bootstrapping Mathematical Reasoning for Multimodal Large Language Models
Jun 26, 2024



Large language models (LLMs) have demonstrated impressive reasoning capabilities, particularly in textual mathematical problem-solving. However, existing open-source image instruction fine-tuning datasets, containing limited question-answer pairs per image, do not fully exploit visual information to enhance the multimodal mathematical reasoning capabilities of Multimodal LLMs (MLLMs). To bridge this gap, we address the lack of high-quality, diverse multimodal mathematical datasets by collecting 40K high-quality images with question-answer pairs from 24 existing datasets and synthesizing 320K new pairs, creating the MathV360K dataset, which enhances both the breadth and depth of multimodal mathematical questions. We introduce Math-LLaVA, a LLaVA-1.5-based model fine-tuned with MathV360K. This novel approach significantly improves the multimodal mathematical reasoning capabilities of LLaVA-1.5, achieving a 19-point increase and comparable performance to GPT-4V on MathVista's minitest split. Furthermore, Math-LLaVA demonstrates enhanced generalizability, showing substantial improvements on the MMMU benchmark. Our research highlights the importance of dataset diversity and synthesis in advancing MLLMs' mathematical reasoning abilities. The code and data are available at: \url{https://github.com/HZQ950419/Math-LLaVA}.