 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanoGS: Training-Free Gaussian Splat Simplification
Mar 17, 20263D Gaussian Splat (3DGS) enables high-fidelity, real-time novel view synthesis by representing scenes with large sets of anisotropic primitives, but often requires millions of Splats, incurring significant storage and transmission costs. Most existing compression methods rely on GPU-intensive post-training optimization with calibrated images, limiting practical deployment. We introduce NanoGS, a training-free and lightweight framework for Gaussian Splat simplification. Instead of relying on image-based rendering supervision, NanoGS formulates simplification as local pairwise merging over a sparse spatial graph. The method approximates a pair of Gaussians with a single primitive using mass preserved moment matching and evaluates merge quality through a principled merge cost between the original mixture and its approximation. By restricting merge candidates to local neighborhoods and selecting compatible pairs efficiently, NanoGS produces compact Gaussian representations while preserving scene structure and appearance. NanoGS operates directly on existing Gaussian Splat models, runs efficiently on CPU, and preserves the standard 3DGS parameterization, enabling seamless integration with existing rendering pipelines. Experiments demonstrate that NanoGS substantially reduces primitive count while maintaining high rendering fidelity, providing an efficient and practical solution for Gaussian Splat simplification. Our project website is available at https://saliteta.github.io/NanoGS/.
IDU: Incremental Dynamic Update of Existing 3D Virtual Environments with New Imagery Data
Aug 25, 2025For simulation and training purposes, military organizations have made substantial investments in developing high-resolution 3D virtual environments through extensive imaging and 3D scanning. However, the dynamic nature of battlefield conditions-where objects may appear or vanish over time-makes frequent full-scale updates both time-consuming and costly. In response, we introduce the Incremental Dynamic Update (IDU) pipeline, which efficiently updates existing 3D reconstructions, such as 3D Gaussian Splatting (3DGS), with only a small set of newly acquired images. Our approach starts with camera pose estimation to align new images with the existing 3D model, followed by change detection to pinpoint modifications in the scene. A 3D generative AI model is then used to create high-quality 3D assets of the new elements, which are seamlessly integrated into the existing 3D model. The IDU pipeline incorporates human guidance to ensure high accuracy in object identification and placement, with each update focusing on a single new object at a time. Experimental results confirm that our proposed IDU pipeline significantly reduces update time and labor, offering a cost-effective and targeted solution for maintaining up-to-date 3D models in rapidly evolving military scenarios.
Splat Feature Solver
Aug 17, 2025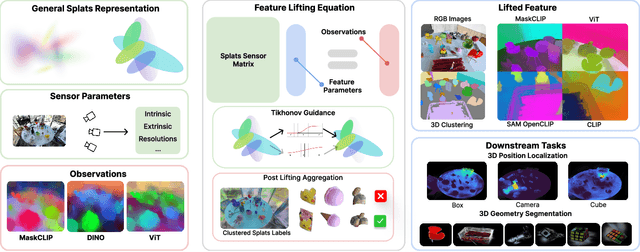
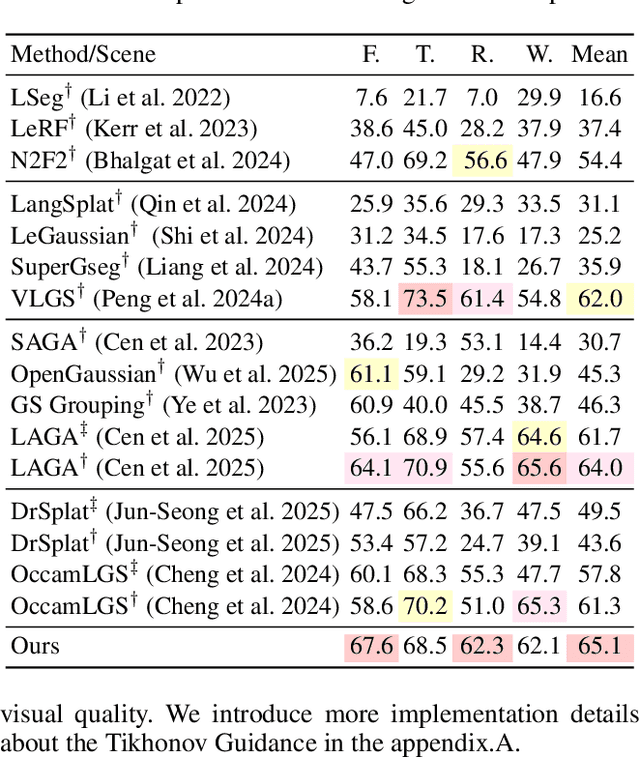
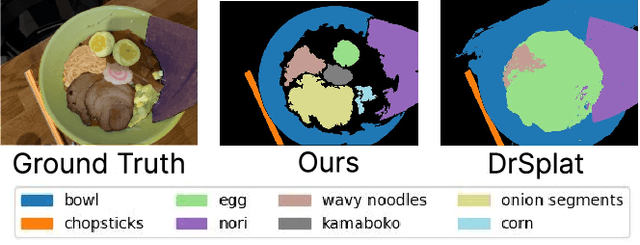
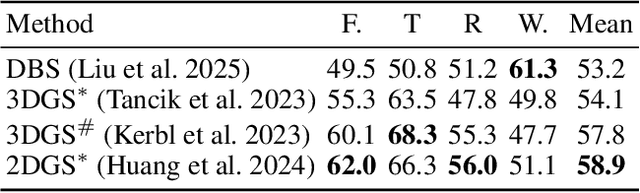
Feature lifting has emerged as a crucial component in 3D scene understanding, enabling the attachment of rich image feature descriptors (e.g., DINO, CLIP) onto splat-based 3D representations. The core challenge lies in optimally assigning rich general attributes to 3D primitives while addressing the inconsistency issues from multi-view images. We present a unified, kernel- and feature-agnostic formulation of the feature lifting problem as a sparse linear inverse problem, which can be solved efficiently in closed form. Our approach admits a provable upper bound on the global optimal error under convex losses for delivering high quality lifted features. To address inconsistencies and noise in multi-view observations, we introduce two complementary regularization strategies to stabilize the solution and enhance semantic fidelity. Tikhonov Guidance enforces numerical stability through soft diagonal dominance, while Post-Lifting Aggregation filters noisy inputs via feature clustering. Extensive experiments demonstrate that our approach achieves state-of-the-art performance on open-vocabulary 3D segmentation benchmarks, outperforming training-based, grouping-based, and heuristic-forward baselines while producing the lifted features in minutes. Code is available at \href{https://github.com/saliteta/splat-distiller.git}{\textbf{github}}. We also have a \href{https://splat-distiller.pages.dev/}
BYOCL: Build Your Own Consistent Latent with Hierarchical Representative Latent Clustering
Oct 19, 2024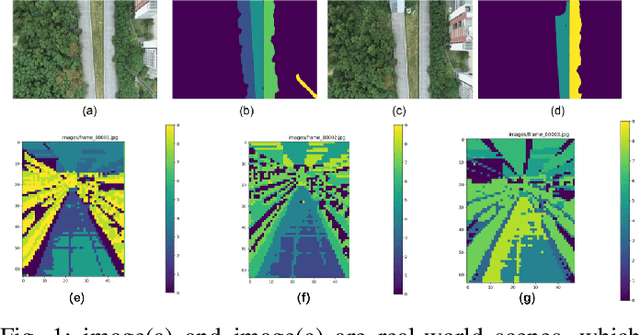
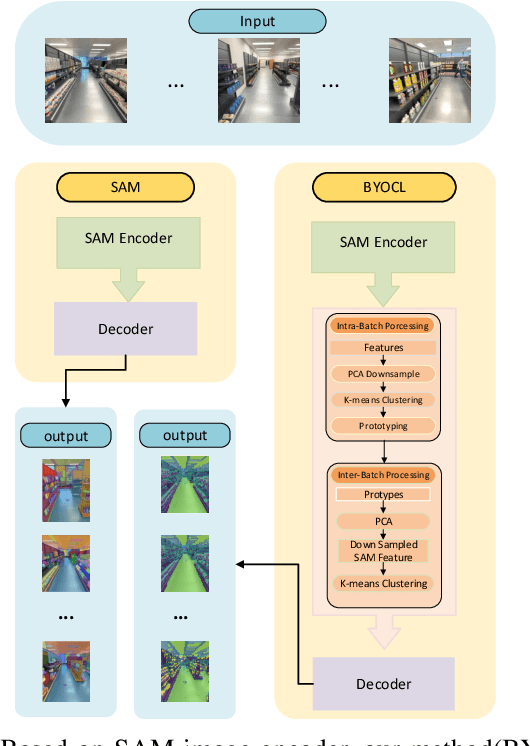
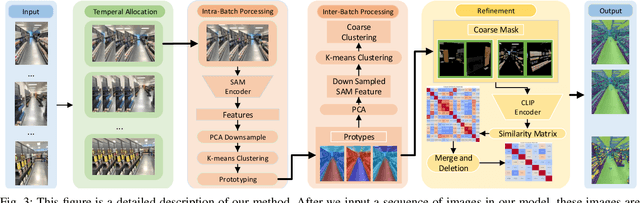
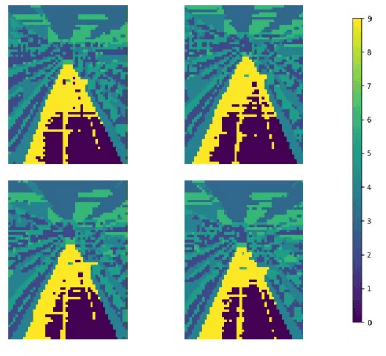
To address the semantic inconsistency issue with SAM or other single-image segmentation models handling image sequences, we introduce BYOCL. This novel model outperforms SAM in extensive experiments, showcasing its Hierarchical prototype capabilities across CLIP and other representations. BYOCL significantly reduces time and space consumption by dividing inputs into smaller batches, achieving exponential time reduction compared to previous methods. Our approach leverages the SAM image encoder for feature extraction, followed by Intra-Batch and Inter-Batch clustering algorithms. Extensive experiments demonstrate that BYOCL far exceeds the previous state-of-the-art single image segmentation model. Our work is the first to apply consistent segmentation using foundation models without requiring training, utilizing plug-and-play modules for any latent space, making our method highly efficientModels are available at \href{https://github.com/cyt1202/BYOCL.git
SA-GS: Semantic-Aware Gaussian Splatting for Large Scene Reconstruction with Geometry Constrain
May 28, 2024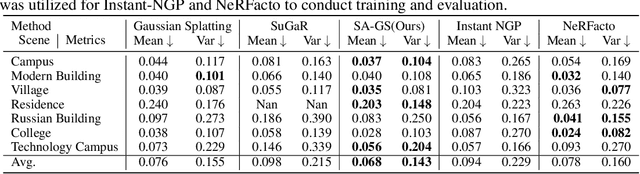
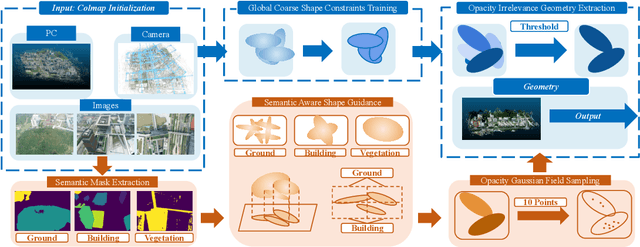

With the emergence of Gaussian Splats, recent efforts have focused on large-scale scene geometric reconstruction. However, most of these efforts either concentrate on memory reduction or spatial space division, neglecting information in the semantic space. In this paper, we propose a novel method, named SA-GS, for fine-grained 3D geometry reconstruction using semantic-aware 3D Gaussian Splats. Specifically, we leverage prior information stored in large vision models such as SAM and DINO to generate semantic masks. We then introduce a geometric complexity measurement function to serve as soft regularization, guiding the shape of each Gaussian Splat within specific semantic areas. Additionally, we present a method that estimates the expected number of Gaussian Splats in different semantic areas, effectively providing a lower bound for Gaussian Splats in these areas. Subsequently, we extract the point cloud using a novel probability density-based extraction method, transforming Gaussian Splats into a point cloud crucial for downstream tasks. Our method also offers the potential for detailed semantic inquiries while maintaining high image-based reconstruction results. We provide extensive experiments on publicly available large-scale scene reconstruction datasets with highly accurate point clouds as ground truth and our novel dataset. Our results demonstrate the superiority of our method over current state-of-the-art Gaussian Splats reconstruction methods by a significant margin in terms of geometric-based measurement metrics. Code and additional results will soon be available on our project page.
GauU-Scene V2: Assessing the Reliability of Image-Based Metrics with Expansive Lidar Image Dataset Using 3DGS and NeRF
Apr 13, 2024



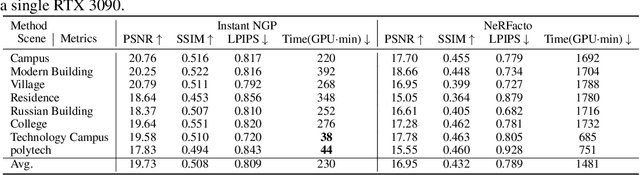
We introduce a novel, multimodal large-scale scene reconstruction benchmark that utilizes newly developed 3D representation approaches: Gaussian Splatting and Neural Radiance Fields (NeRF). Our expansive U-Scene dataset surpasses any previously existing real large-scale outdoor LiDAR and image dataset in both area and point count. GauU-Scene encompasses over 6.5 square kilometers and features a comprehensive RGB dataset coupled with LiDAR ground truth. Additionally, we are the first to propose a LiDAR and image alignment method for a drone-based dataset. Our assessment of GauU-Scene includes a detailed analysis across various novel viewpoints, employing image-based metrics such as SSIM, LPIPS, and PSNR on NeRF and Gaussian Splatting based methods. This analysis reveals contradictory results when applying geometric-based metrics like Chamfer distance. The experimental results on our multimodal dataset highlight the unreliability of current image-based metrics and reveal significant drawbacks in geometric reconstruction using the current Gaussian Splatting-based method, further illustrating the necessity of our dataset for assessing geometry reconstruction tasks. We also provide detailed supplementary information on data collection protocols and make the dataset available on the following anonymous project page
GauU-Scene: A Scene Reconstruction Benchmark on Large Scale 3D Reconstruction Dataset Using Gaussian Splatting
Jan 25, 2024
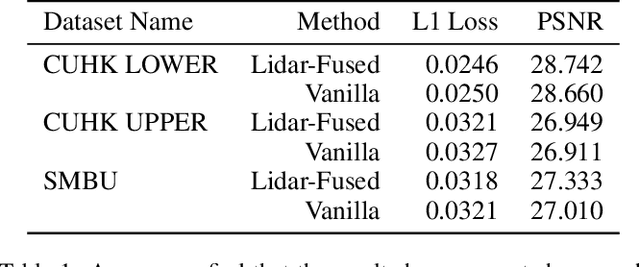
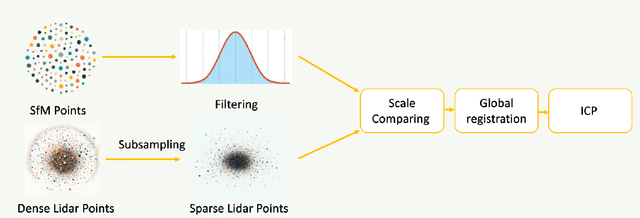

We introduce a novel large-scale scene reconstruction benchmark using the newly developed 3D representation approach, Gaussian Splatting, on our expansive U-Scene dataset. U-Scene encompasses over one and a half square kilometres, featuring a comprehensive RGB dataset coupled with LiDAR ground truth. For data acquisition, we employed the Matrix 300 drone equipped with the high-accuracy Zenmuse L1 LiDAR, enabling precise rooftop data collection. This dataset, offers a unique blend of urban and academic environments for advanced spatial analysis convers more than 1.5 km$^2$. Our evaluation of U-Scene with Gaussian Splatting includes a detailed analysis across various novel viewpoints. We also juxtapose these results with those derived from our accurate point cloud dataset, highlighting significant differences that underscore the importance of combine multi-modal information