 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphe: High-Fidelity Generative Video Streaming with Vision Foundation Model
Feb 03, 2026Video streaming is a fundamental Internet service, while the quality still cannot be guaranteed especially in poor network conditions such as bandwidth-constrained and remote areas. Existing works mainly work towards two directions: traditional pixel-codec streaming nearly approaches its limit and is hard to step further in compression; the emerging neural-enhanced or generative streaming usually fall short in latency and visual fidelity, hindering their practical deployment. Inspired by the recent success of vision foundation model (VFM), we strive to harness the powerful video understanding and processing capacities of VFM to achieve generalization, high fidelity and loss resilience for real-time video streaming with even higher compression rate. We present the first revolutionized paradigm that enables VFM-based end-to-end generative video streaming towards this goal. Specifically, Morphe employs joint training of visual tokenizers and variable-resolution spatiotemporal optimization under simulated network constraints. Additionally, a robust streaming system is constructed that leverages intelligent packet dropping to resist real-world network perturbations. Extensive evaluation demonstrates that Morphe achieves comparable visual quality while saving 62.5\% bandwidth compared to H.265, and accomplishes real-time, loss-resilient video delivery in challenging network environments, representing a milestone in VFM-enabled multimedia streaming solutions.
AgentsEval: Clinically Faithful Evaluation of Medical Imaging Reports via Multi-Agent Reasoning
Jan 23, 2026Evaluating the clinical correctness and reasoning fidelity of automatically generated medical imaging reports remains a critical yet unresolved challenge. Existing evaluation methods often fail to capture the structured diagnostic logic that underlies radiological interpretation, resulting in unreliable judgments and limited clinical relevance. We introduce AgentsEval, a multi-agent stream reasoning framework that emulates the collaborative diagnostic workflow of radiologists. By dividing the evaluation process into interpretable steps including criteria definition, evidence extraction, alignment, and consistency scoring, AgentsEval provides explicit reasoning traces and structured clinical feedback. We also construct a multi-domain perturbation-based benchmark covering five medical report datasets with diverse imaging modalities and controlled semantic variations. Experimental results demonstrate that AgentsEval delivers clinically aligned, semantically faithful, and interpretable evaluations that remain robust under paraphrastic, semantic, and stylistic perturbations. This framework represents a step toward transparent and clinically grounded assessment of medical report generation systems, fostering trustworthy integration of large language models into clinical practice.
FutureX: Enhance End-to-End Autonomous Driving via Latent Chain-of-Thought World Model
Dec 12, 2025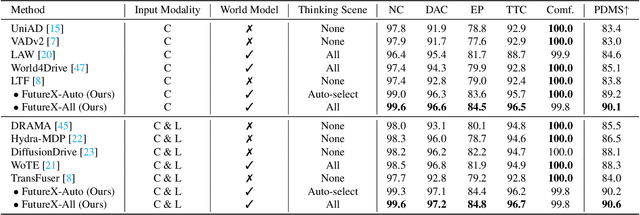
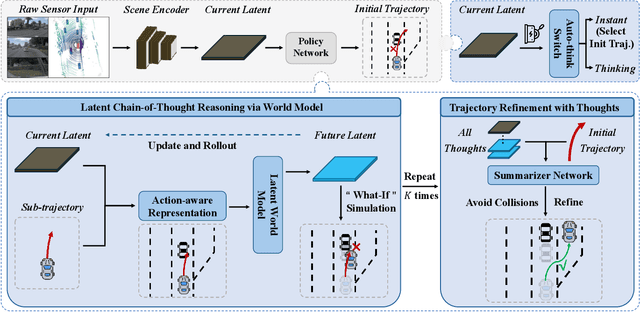

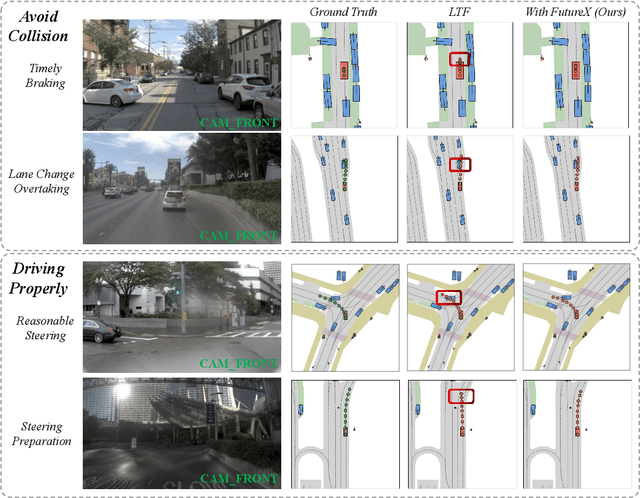
In autonomous driving, end-to-end planners learn scene representations from raw sensor data and utilize them to generate a motion plan or control actions. However, exclusive reliance on the current scene for motion planning may result in suboptimal responses in highly dynamic traffic environments where ego actions further alter the future scene. To model the evolution of future scenes, we leverage the World Model to represent how the ego vehicle and its environment interact and change over time, which entails complex reasoning. The Chain of Thought (CoT) offers a promising solution by forecasting a sequence of future thoughts that subsequently guide trajectory refinement. In this paper, we propose FutureX, a CoT-driven pipeline that enhances end-to-end planners to perform complex motion planning via future scene latent reasoning and trajectory refinement. Specifically, the Auto-think Switch examines the current scene and decides whether additional reasoning is required to yield a higher-quality motion plan. Once FutureX enters the Thinking mode, the Latent World Model conducts a CoT-guided rollout to predict future scene representation, enabling the Summarizer Module to further refine the motion plan. Otherwise, FutureX operates in an Instant mode to generate motion plans in a forward pass for relatively simple scenes. Extensive experiments demonstrate that FutureX enhances existing methods by producing more rational motion plans and fewer collisions without compromising efficiency, thereby achieving substantial overall performance gains, e.g., 6.2 PDMS improvement for TransFuser on NAVSIM. Code will be released.
CloseUpShot: Close-up Novel View Synthesis from Sparse-views via Point-conditioned Diffusion Model
Nov 17, 2025Reconstructing 3D scenes and synthesizing novel views from sparse input views is a highly challenging task. Recent advances in video diffusion models have demonstrated strong temporal reasoning capabilities, making them a promising tool for enhancing reconstruction quality under sparse-view settings. However, existing approaches are primarily designed for modest viewpoint variations, which struggle in capturing fine-grained details in close-up scenarios since input information is severely limited. In this paper, we present a diffusion-based framework, called CloseUpShot, for close-up novel view synthesis from sparse inputs via point-conditioned video diffusion. Specifically, we observe that pixel-warping conditioning suffers from severe sparsity and background leakage in close-up settings. To address this, we propose hierarchical warping and occlusion-aware noise suppression, enhancing the quality and completeness of the conditioning images for the video diffusion model. Furthermore, we introduce global structure guidance, which leverages a dense fused point cloud to provide consistent geometric context to the diffusion process, to compensate for the lack of globally consistent 3D constraints in sparse conditioning inputs. Extensive experiments on multiple datasets demonstrate that our method outperforms existing approaches, especially in close-up novel view synthesis, clearly validating the effectiveness of our design.
Integrated Sensing and Communication: Towards Multifunctional Perceptive Network
Oct 16, 2025The capacity-maximization design philosophy has driven the growth of wireless networks for decades. However, with the slowdown in recent data traffic demand, the mobile industry can no longer rely solely on communication services to sustain development. In response, Integrated Sensing and Communications (ISAC) has emerged as a transformative solution, embedding sensing capabilities into communication networks to enable multifunctional wireless systems. This paradigm shift expands the role of networks from sole data transmission to versatile platforms supporting diverse applications. In this review, we provide a bird's-eye view of ISAC for new researchers, highlighting key challenges, opportunities, and application scenarios to guide future exploration in this field.
Adaptive Source-Channel Coding for Semantic Communications
Aug 11, 2025Semantic communications (SemComs) have emerged as a promising paradigm for joint data and task-oriented transmissions, combining the demands for both the bit-accurate delivery and end-to-end (E2E) distortion minimization. However, current joint source-channel coding (JSCC) in SemComs is not compatible with the existing communication systems and cannot adapt to the variations of the sources or the channels, while separate source-channel coding (SSCC) is suboptimal in the finite blocklength regime. To address these issues, we propose an adaptive source-channel coding (ASCC) scheme for SemComs over parallel Gaussian channels, where the deep neural network (DNN)-based semantic source coding and conventional digital channel coding are separately deployed and adaptively designed. To enable efficient adaptation between the source and channel coding, we first approximate the E2E data and semantic distortions as functions of source coding rate and bit error ratio (BER) via logistic regression, where BER is further modeled as functions of signal-to-noise ratio (SNR) and channel coding rate. Then, we formulate the weighted sum E2E distortion minimization problem for joint source-channel coding rate and power allocation over parallel channels, which is solved by the successive convex approximation. Finally, simulation results demonstrate that the proposed ASCC scheme outperforms typical deep JSCC and SSCC schemes for both the single- and parallel-channel scenarios while maintaining full compatibility with practical digital systems.
RadioDiff-3D: A 3D$\times$3D Radio Map Dataset and Generative Diffusion Based Benchmark for 6G Environment-Aware Communication
Jul 16, 2025Radio maps (RMs) serve as a critical foundation for enabling environment-aware wireless communication, as they provide the spatial distribution of wireless channel characteristics. Despite recent progress in RM construction using data-driven approaches, most existing methods focus solely on pathloss prediction in a fixed 2D plane, neglecting key parameters such as direction of arrival (DoA), time of arrival (ToA), and vertical spatial variations. Such a limitation is primarily due to the reliance on static learning paradigms, which hinder generalization beyond the training data distribution. To address these challenges, we propose UrbanRadio3D, a large-scale, high-resolution 3D RM dataset constructed via ray tracing in realistic urban environments. UrbanRadio3D is over 37$\times$3 larger than previous datasets across a 3D space with 3 metrics as pathloss, DoA, and ToA, forming a novel 3D$\times$33D dataset with 7$\times$3 more height layers than prior state-of-the-art (SOTA) dataset. To benchmark 3D RM construction, a UNet with 3D convolutional operators is proposed. Moreover, we further introduce RadioDiff-3D, a diffusion-model-based generative framework utilizing the 3D convolutional architecture. RadioDiff-3D supports both radiation-aware scenarios with known transmitter locations and radiation-unaware settings based on sparse spatial observations. Extensive evaluations on UrbanRadio3D validate that RadioDiff-3D achieves superior performance in constructing rich, high-dimensional radio maps under diverse environmental dynamics. This work provides a foundational dataset and benchmark for future research in 3D environment-aware communication. The dataset is available at https://github.com/UNIC-Lab/UrbanRadio3D.
RelTopo: Enhancing Relational Modeling for Driving Scene Topology Reasoning
Jun 16, 2025



Accurate road topology reasoning is critical for autonomous driving, enabling effective navigation and adherence to traffic regulations. Central to this task are lane perception and topology reasoning. However, existing methods typically focus on either lane detection or Lane-to-Lane (L2L) topology reasoning, often \textit{neglecting} Lane-to-Traffic-element (L2T) relationships or \textit{failing} to optimize these tasks jointly. Furthermore, most approaches either overlook relational modeling or apply it in a limited scope, despite the inherent spatial relationships among road elements. We argue that relational modeling is beneficial for both perception and reasoning, as humans naturally leverage contextual relationships for road element recognition and their connectivity inference. To this end, we introduce relational modeling into both perception and reasoning, \textit{jointly} enhancing structural understanding. Specifically, we propose: 1) a relation-aware lane detector, where our geometry-biased self-attention and \curve\ cross-attention refine lane representations by capturing relational dependencies; 2) relation-enhanced topology heads, including a geometry-enhanced L2L head and a cross-view L2T head, boosting reasoning with relational cues; and 3) a contrastive learning strategy with InfoNCE loss to regularize relationship embeddings. Extensive experiments on OpenLane-V2 demonstrate that our approach significantly improves both detection and topology reasoning metrics, achieving +3.1 in DET$_l$, +5.3 in TOP$_{ll}$, +4.9 in TOP$_{lt}$, and an overall +4.4 in OLS, setting a new state-of-the-art. Code will be released.
RadioDiff-$k^2$: Helmholtz Equation Informed Generative Diffusion Model for Multi-Path Aware Radio Map Construction
Apr 22, 2025In this paper, we propose a novel physics-informed generative learning approach, termed RadioDiff-$\bm{k^2}$, for accurate and efficient multipath-aware radio map (RM) construction. As wireless communication evolves towards environment-aware paradigms, driven by the increasing demand for intelligent and proactive optimization in sixth-generation (6G) networks, accurate construction of RMs becomes crucial yet highly challenging. Conventional electromagnetic (EM)-based methods, such as full-wave solvers and ray-tracing approaches, exhibit substantial computational overhead and limited adaptability to dynamic scenarios. Although, existing neural network (NN) approaches have efficient inferencing speed, they lack sufficient consideration of the underlying physics of EM wave propagation, limiting their effectiveness in accurately modeling critical EM singularities induced by complex multipath environments. To address these fundamental limitations, we propose a novel physics-inspired RM construction method guided explicitly by the Helmholtz equation, which inherently governs EM wave propagation. Specifically, we theoretically establish a direct correspondence between EM singularities, which correspond to the critical spatial features influencing wireless propagation, and regions defined by negative wave numbers in the Helmholtz equation. Based on this insight, we design an innovative dual generative diffusion model (DM) framework comprising one DM dedicated to accurately inferring EM singularities and another DM responsible for reconstructing the complete RM using these singularities along with environmental contextual information. Our physics-informed approach uniquely combines the efficiency advantages of data-driven methods with rigorous physics-based EM modeling, significantly enhancing RM accuracy, particularly in complex propagation environments dominated by multipath effects.
Scalable Transceiver Design for Multi-User Communication in FDD Massive MIMO Systems via Deep Learning
Apr 15, 2025This paper addresses the joint transceiver design, including pilot transmission, channel feature extraction and feedback, as well as precoding, for low-overhead downlink massive multiple-input multiple-output (MIMO) communication in frequency-division duplex (FDD) systems. Although deep learning (DL) has shown great potential in tackling this problem, existing methods often suffer from poor scalability in practical systems, as the solution obtained in the training phase merely works for a fixed feedback capacity and a fixed number of users in the deployment phase. To address this limitation, we propose a novel DL-based framework comprised of choreographed neural networks, which can utilize one training phase to generate all the transceiver solutions used in the deployment phase with varying sizes of feedback codebooks and numbers of users. The proposed framework includes a residual vector-quantized variational autoencoder (RVQ-VAE) for efficient channel feedback and an edge graph attention network (EGAT) for robust multiuser precoding. It can adapt to different feedback capacities by flexibly adjusting the RVQ codebook sizes using the hierarchical codebook structure, and scale with the number of users through a feedback module sharing scheme and the inherent scalability of EGAT. Moreover, a progressive training strategy is proposed to further enhance data transmission performance and generalization capability. Numerical results on a real-world dataset demonstrate the superior scalability and performance of our approach over existing methods.