 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Concepts Emerge from Motion
May 27, 2025Object concepts play a foundational role in human visual cognition, enabling perception, memory, and interaction in the physical world. Inspired by findings in developmental neuroscience - where infants are shown to acquire object understanding through observation of motion - we propose a biologically inspired framework for learning object-centric visual representations in an unsupervised manner. Our key insight is that motion boundary serves as a strong signal for object-level grouping, which can be used to derive pseudo instance supervision from raw videos. Concretely, we generate motion-based instance masks using off-the-shelf optical flow and clustering algorithms, and use them to train visual encoders via contrastive learning. Our framework is fully label-free and does not rely on camera calibration, making it scalable to large-scale unstructured video data. We evaluate our approach on three downstream tasks spanning both low-level (monocular depth estimation) and high-level (3D object detection and occupancy prediction) vision. Our models outperform previous supervised and self-supervised baselines and demonstrate strong generalization to unseen scenes. These results suggest that motion-induced object representations offer a compelling alternative to existing vision foundation models, capturing a crucial but overlooked level of abstraction: the visual instance. The corresponding code will be released upon paper acceptance.
Anchor3DLane++: 3D Lane Detection via Sample-Adaptive Sparse 3D Anchor Regression
Dec 22, 2024In this paper, we focus on the challenging task of monocular 3D lane detection. Previous methods typically adopt inverse perspective mapping (IPM) to transform the Front-Viewed (FV) images or features into the Bird-Eye-Viewed (BEV) space for lane detection. However, IPM's dependence on flat ground assumption and context information loss in BEV representations lead to inaccurate 3D information estimation. Though efforts have been made to bypass BEV and directly predict 3D lanes from FV representations, their performances still fall behind BEV-based methods due to a lack of structured modeling of 3D lanes. In this paper, we propose a novel BEV-free method named Anchor3DLane++ which defines 3D lane anchors as structural representations and makes predictions directly from FV features. We also design a Prototype-based Adaptive Anchor Generation (PAAG) module to generate sample-adaptive sparse 3D anchors dynamically. In addition, an Equal-Width (EW) loss is developed to leverage the parallel property of lanes for regularization. Furthermore, camera-LiDAR fusion is also explored based on Anchor3DLane++ to leverage complementary information. Extensive experiments on three popular 3D lane detection benchmarks show that our Anchor3DLane++ outperforms previous state-of-the-art methods. Code is available at: https://github.com/tusen-ai/Anchor3DLane.
Towards Flexible 3D Perception: Object-Centric Occupancy Completion Augments 3D Object Detection
Dec 06, 2024



While 3D object bounding box (bbox) representation has been widely used in autonomous driving perception, it lacks the ability to capture the precise details of an object's intrinsic geometry. Recently, occupancy has emerged as a promising alternative for 3D scene perception. However, constructing a high-resolution occupancy map remains infeasible for large scenes due to computational constraints. Recognizing that foreground objects only occupy a small portion of the scene, we introduce object-centric occupancy as a supplement to object bboxes. This representation not only provides intricate details for detected objects but also enables higher voxel resolution in practical applications. We advance the development of object-centric occupancy perception from both data and algorithm perspectives. On the data side, we construct the first object-centric occupancy dataset from scratch using an automated pipeline. From the algorithmic standpoint, we introduce a novel object-centric occupancy completion network equipped with an implicit shape decoder that manages dynamic-size occupancy generation. This network accurately predicts the complete object-centric occupancy volume for inaccurate object proposals by leveraging temporal information from long sequences. Our method demonstrates robust performance in completing object shapes under noisy detection and tracking conditions. Additionally, we show that our occupancy features significantly enhance the detection results of state-of-the-art 3D object detectors, especially for incomplete or distant objects in the Waymo Open Dataset.
MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection
Aug 12, 2024The rise of autonomous vehicles has significantly increased the demand for robust 3D object detection systems. While cameras and LiDAR sensors each offer unique advantages--cameras provide rich texture information and LiDAR offers precise 3D spatial data--relying on a single modality often leads to performance limitations. This paper introduces MV2DFusion, a multi-modal detection framework that integrates the strengths of both worlds through an advanced query-based fusion mechanism. By introducing an image query generator to align with image-specific attributes and a point cloud query generator, MV2DFusion effectively combines modality-specific object semantics without biasing toward one single modality. Then the sparse fusion process can be accomplished based on the valuable object semantics, ensuring efficient and accurate object detection across various scenarios. Our framework's flexibility allows it to integrate with any image and point cloud-based detectors, showcasing its adaptability and potential for future advancements. Extensive evaluations on the nuScenes and Argoverse2 datasets demonstrate that MV2DFusion achieves state-of-the-art performance, particularly excelling in long-range detection scenarios.
Enhancing 3D Lane Detection and Topology Reasoning with 2D Lane Priors
Jun 05, 2024



3D lane detection and topology reasoning are essential tasks in autonomous driving scenarios, requiring not only detecting the accurate 3D coordinates on lane lines, but also reasoning the relationship between lanes and traffic elements. Current vision-based methods, whether explicitly constructing BEV features or not, all establish the lane anchors/queries in 3D space while ignoring the 2D lane priors. In this study, we propose Topo2D, a novel framework based on Transformer, leveraging 2D lane instances to initialize 3D queries and 3D positional embeddings. Furthermore, we explicitly incorporate 2D lane features into the recognition of topology relationships among lane centerlines and between lane centerlines and traffic elements. Topo2D achieves 44.5% OLS on multi-view topology reasoning benchmark OpenLane-V2 and 62.6% F-Socre on single-view 3D lane detection benchmark OpenLane, exceeding the performance of existing state-of-the-art methods.
SparseFusion: Efficient Sparse Multi-Modal Fusion Framework for Long-Range 3D Perception
Mar 15, 2024



Multi-modal 3D object detection has exhibited significant progress in recent years. However, most existing methods can hardly scale to long-range scenarios due to their reliance on dense 3D features, which substantially escalate computational demands and memory usage. In this paper, we introduce SparseFusion, a novel multi-modal fusion framework fully built upon sparse 3D features to facilitate efficient long-range perception. The core of our method is the Sparse View Transformer module, which selectively lifts regions of interest in 2D image space into the unified 3D space. The proposed module introduces sparsity from both semantic and geometric aspects which only fill grids that foreground objects potentially reside in. Comprehensive experiments have verified the efficiency and effectiveness of our framework in long-range 3D perception. Remarkably, on the long-range Argoverse2 dataset, SparseFusion reduces memory footprint and accelerates the inference by about two times compared to dense detectors. It also achieves state-of-the-art performance with mAP of 41.2% and CDS of 32.1%. The versatility of SparseFusion is also validated in the temporal object detection task and 3D lane detection task. Codes will be released upon acceptance.
Lightning NeRF: Efficient Hybrid Scene Representation for Autonomous Driving
Mar 09, 2024



Recent studies have highlighted the promising application of NeRF in autonomous driving contexts. However, the complexity of outdoor environments, combined with the restricted viewpoints in driving scenarios, complicates the task of precisely reconstructing scene geometry. Such challenges often lead to diminished quality in reconstructions and extended durations for both training and rendering. To tackle these challenges, we present Lightning NeRF. It uses an efficient hybrid scene representation that effectively utilizes the geometry prior from LiDAR in autonomous driving scenarios. Lightning NeRF significantly improves the novel view synthesis performance of NeRF and reduces computational overheads. Through evaluations on real-world datasets, such as KITTI-360, Argoverse2, and our private dataset, we demonstrate that our approach not only exceeds the current state-of-the-art in novel view synthesis quality but also achieves a five-fold increase in training speed and a ten-fold improvement in rendering speed. Codes are available at https://github.com/VISION-SJTU/Lightning-NeRF .
TSTTC: A Large-Scale Dataset for Time-to-Contact Estimation in Driving Scenarios
Sep 06, 2023Time-to-Contact (TTC) estimation is a critical task for assessing collision risk and is widely used in various driver assistance and autonomous driving systems. The past few decades have witnessed development of related theories and algorithms. The prevalent learning-based methods call for a large-scale TTC dataset in real-world scenarios. In this work, we present a large-scale object oriented TTC dataset in the driving scene for promoting the TTC estimation by a monocular camera. To collect valuable samples and make data with different TTC values relatively balanced, we go through thousands of hours of driving data and select over 200K sequences with a preset data distribution. To augment the quantity of small TTC cases, we also generate clips using the latest Neural rendering methods. Additionally, we provide several simple yet effective TTC estimation baselines and evaluate them extensively on the proposed dataset to demonstrate their effectiveness. The proposed dataset is publicly available at https://open-dataset.tusen.ai/TSTTC.
FSD V2: Improving Fully Sparse 3D Object Detection with Virtual Voxels
Aug 07, 2023


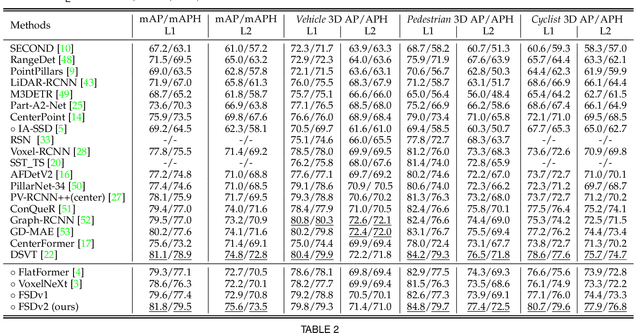
LiDAR-based fully sparse architecture has garnered increasing attention. FSDv1 stands out as a representative work, achieving impressive efficacy and efficiency, albeit with intricate structures and handcrafted designs. In this paper, we present FSDv2, an evolution that aims to simplify the previous FSDv1 while eliminating the inductive bias introduced by its handcrafted instance-level representation, thus promoting better general applicability. To this end, we introduce the concept of \textbf{virtual voxels}, which takes over the clustering-based instance segmentation in FSDv1. Virtual voxels not only address the notorious issue of the Center Feature Missing problem in fully sparse detectors but also endow the framework with a more elegant and streamlined approach. Consequently, we develop a suite of components to complement the virtual voxel concept, including a virtual voxel encoder, a virtual voxel mixer, and a virtual voxel assignment strategy. Through empirical validation, we demonstrate that the virtual voxel mechanism is functionally similar to the handcrafted clustering in FSDv1 while being more general. We conduct experiments on three large-scale datasets: Waymo Open Dataset, Argoverse 2 dataset, and nuScenes dataset. Our results showcase state-of-the-art performance on all three datasets, highlighting the superiority of FSDv2 in long-range scenarios and its general applicability to achieve competitive performance across diverse scenarios. Moreover, we provide comprehensive experimental analysis to elucidate the workings of FSDv2. To foster reproducibility and further research, we have open-sourced FSDv2 at https://github.com/tusen-ai/SST.
Echoes Beyond Points: Unleashing the Power of Raw Radar Data in Multi-modality Fusion
Jul 31, 2023



Radar is ubiquitous in autonomous driving systems due to its low cost and good adaptability to bad weather. Nevertheless, the radar detection performance is usually inferior because its point cloud is sparse and not accurate due to the poor azimuth and elevation resolution. Moreover, point cloud generation algorithms already drop weak signals to reduce the false targets which may be suboptimal for the use of deep fusion. In this paper, we propose a novel method named EchoFusion to skip the existing radar signal processing pipeline and then incorporate the radar raw data with other sensors. Specifically, we first generate the Bird's Eye View (BEV) queries and then take corresponding spectrum features from radar to fuse with other sensors. By this approach, our method could utilize both rich and lossless distance and speed clues from radar echoes and rich semantic clues from images, making our method surpass all existing methods on the RADIal dataset, and approach the performance of LiDAR. Codes will be available upon acceptance.