 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCBench: A Streaming Counting Benchmark for Spatial-Temporal State Maintenance in Long Videos
Mar 13, 2026Video understanding requires models to continuously track and update world state during playback. While existing benchmarks have advanced video understanding evaluation across multiple dimensions, the observation of how models maintain world state remains insufficient. We propose VCBench, a streaming counting benchmark that repositions counting as a minimal probe for diagnosing world state maintenance capability. We decompose this capability into object counting (tracking currently visible objects vs.\ tracking cumulative unique identities) and event counting (detecting instantaneous actions vs.\ tracking complete activity cycles), forming 8 fine-grained subcategories. VCBench contains 406 videos with frame-by-frame annotations of 10,071 event occurrence moments and object state change moments, generating 1,000 streaming QA pairs with 4,576 query points along timelines. By observing state maintenance trajectories through streaming multi-point queries, we design three complementary metrics to diagnose numerical precision, trajectory consistency, and temporal awareness. Evaluation on mainstream video-language models shows that current models still exhibit significant deficiencies in spatial-temporal state maintenance, particularly struggling with tasks like periodic event counting. VCBench provides a diagnostic framework for measuring and improving state maintenance in video understanding systems.
WeThink: Toward General-purpose Vision-Language Reasoning via Reinforcement Learning
Jun 09, 2025Building on the success of text-based reasoning models like DeepSeek-R1, extending these capabilities to multimodal reasoning holds great promise. While recent works have attempted to adapt DeepSeek-R1-style reinforcement learning (RL) training paradigms to multimodal large language models (MLLM), focusing on domain-specific tasks like math and visual perception, a critical question remains: How can we achieve the general-purpose visual-language reasoning through RL? To address this challenge, we make three key efforts: (1) A novel Scalable Multimodal QA Synthesis pipeline that autonomously generates context-aware, reasoning-centric question-answer (QA) pairs directly from the given images. (2) The open-source WeThink dataset containing over 120K multimodal QA pairs with annotated reasoning paths, curated from 18 diverse dataset sources and covering various question domains. (3) A comprehensive exploration of RL on our dataset, incorporating a hybrid reward mechanism that combines rule-based verification with model-based assessment to optimize RL training efficiency across various task domains. Across 14 diverse MLLM benchmarks, we demonstrate that our WeThink dataset significantly enhances performance, from mathematical reasoning to diverse general multimodal tasks. Moreover, we show that our automated data pipeline can continuously increase data diversity to further improve model performance.
Instruction-Oriented Preference Alignment for Enhancing Multi-Modal Comprehension Capability of MLLMs
Mar 26, 2025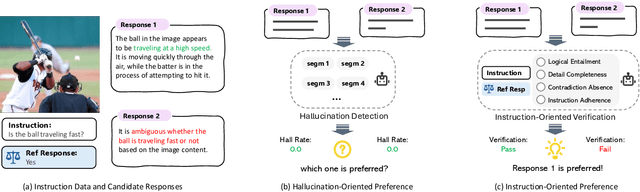
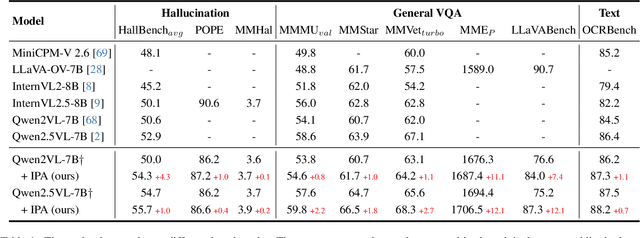
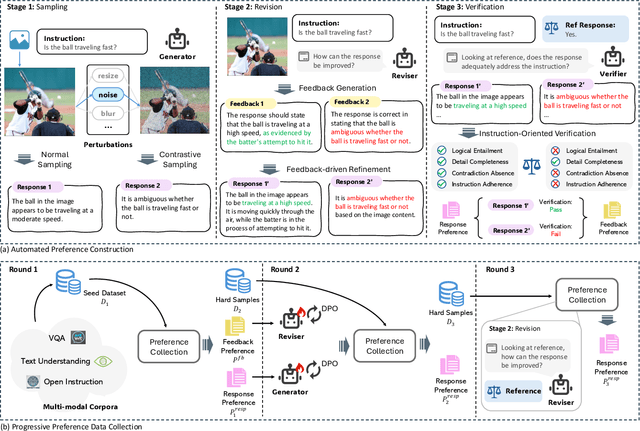
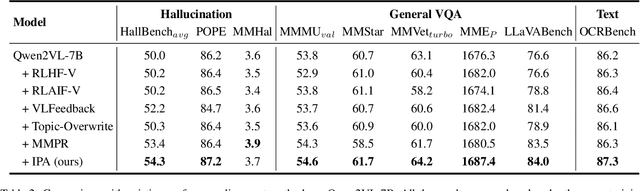
Preference alignment has emerged as an effective strategy to enhance the performance of Multimodal Large Language Models (MLLMs) following supervised fine-tuning. While existing preference alignment methods predominantly target hallucination factors, they overlook the factors essential for multi-modal comprehension capabilities, often narrowing their improvements on hallucination mitigation. To bridge this gap, we propose Instruction-oriented Preference Alignment (IPA), a scalable framework designed to automatically construct alignment preferences grounded in instruction fulfillment efficacy. Our method involves an automated preference construction coupled with a dedicated verification process that identifies instruction-oriented factors, avoiding significant variability in response representations. Additionally, IPA incorporates a progressive preference collection pipeline, further recalling challenging samples through model self-evolution and reference-guided refinement. Experiments conducted on Qwen2VL-7B demonstrate IPA's effectiveness across multiple benchmarks, including hallucination evaluation, visual question answering, and text understanding tasks, highlighting its capability to enhance general comprehension.
Treat Stillness with Movement: Remote Sensing Change Detection via Coarse-grained Temporal Foregrounds Mining
Aug 15, 2024
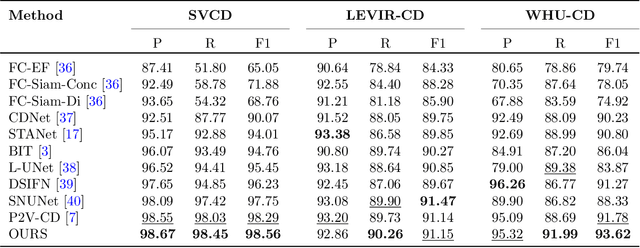
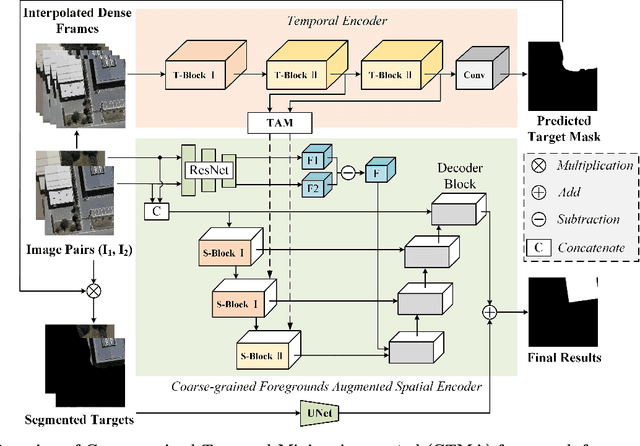

Current works focus on addressing the remote sensing change detection task using bi-temporal images. Although good performance can be achieved, however, seldom of they consider the motion cues which may also be vital. In this work, we revisit the widely adopted bi-temporal images-based framework and propose a novel Coarse-grained Temporal Mining Augmented (CTMA) framework. To be specific, given the bi-temporal images, we first transform them into a video using interpolation operations. Then, a set of temporal encoders is adopted to extract the motion features from the obtained video for coarse-grained changed region prediction. Subsequently, we design a novel Coarse-grained Foregrounds Augmented Spatial Encoder module to integrate both global and local information. We also introduce a motion augmented strategy that leverages motion cues as an additional output to aggregate with the spatial features for improved results. Meanwhile, we feed the input image pairs into the ResNet to get the different features and also the spatial blocks for fine-grained feature learning. More importantly, we propose a mask augmented strategy that utilizes coarse-grained changed regions, incorporating them into the decoder blocks to enhance the final changed prediction. Extensive experiments conducted on multiple benchmark datasets fully validated the effectiveness of our proposed framework for remote sensing image change detection. The source code of this paper will be released on https://github.com/Event-AHU/CTM_Remote_Sensing_Change_Detection
MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection
Aug 12, 2024The rise of autonomous vehicles has significantly increased the demand for robust 3D object detection systems. While cameras and LiDAR sensors each offer unique advantages--cameras provide rich texture information and LiDAR offers precise 3D spatial data--relying on a single modality often leads to performance limitations. This paper introduces MV2DFusion, a multi-modal detection framework that integrates the strengths of both worlds through an advanced query-based fusion mechanism. By introducing an image query generator to align with image-specific attributes and a point cloud query generator, MV2DFusion effectively combines modality-specific object semantics without biasing toward one single modality. Then the sparse fusion process can be accomplished based on the valuable object semantics, ensuring efficient and accurate object detection across various scenarios. Our framework's flexibility allows it to integrate with any image and point cloud-based detectors, showcasing its adaptability and potential for future advancements. Extensive evaluations on the nuScenes and Argoverse2 datasets demonstrate that MV2DFusion achieves state-of-the-art performance, particularly excelling in long-range detection scenarios.
Enhancing 3D Lane Detection and Topology Reasoning with 2D Lane Priors
Jun 05, 2024



3D lane detection and topology reasoning are essential tasks in autonomous driving scenarios, requiring not only detecting the accurate 3D coordinates on lane lines, but also reasoning the relationship between lanes and traffic elements. Current vision-based methods, whether explicitly constructing BEV features or not, all establish the lane anchors/queries in 3D space while ignoring the 2D lane priors. In this study, we propose Topo2D, a novel framework based on Transformer, leveraging 2D lane instances to initialize 3D queries and 3D positional embeddings. Furthermore, we explicitly incorporate 2D lane features into the recognition of topology relationships among lane centerlines and between lane centerlines and traffic elements. Topo2D achieves 44.5% OLS on multi-view topology reasoning benchmark OpenLane-V2 and 62.6% F-Socre on single-view 3D lane detection benchmark OpenLane, exceeding the performance of existing state-of-the-art methods.
Eliminating Cross-modal Conflicts in BEV Space for LiDAR-Camera 3D Object Detection
Mar 12, 2024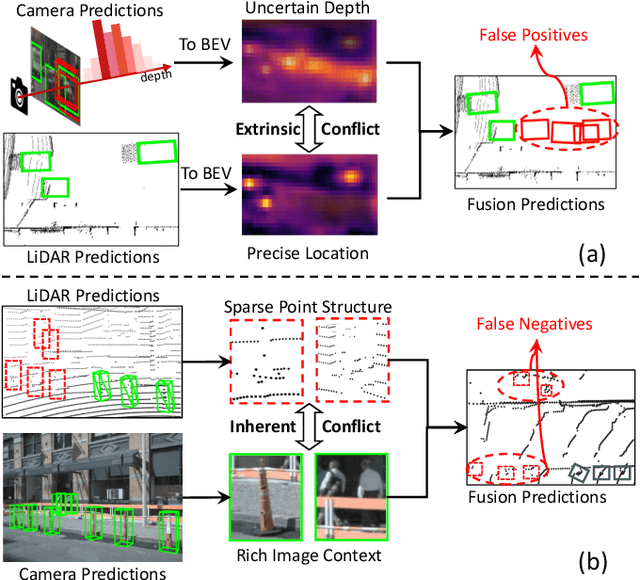
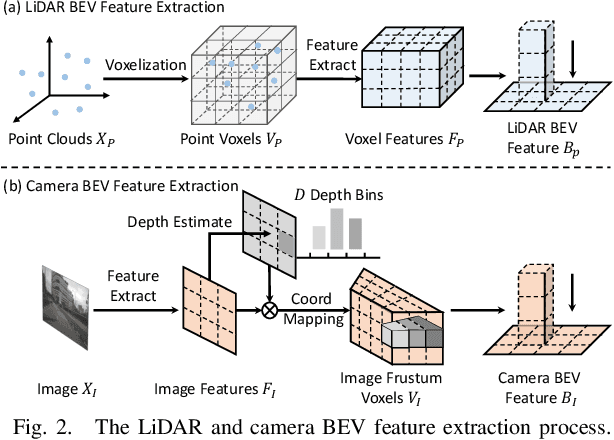
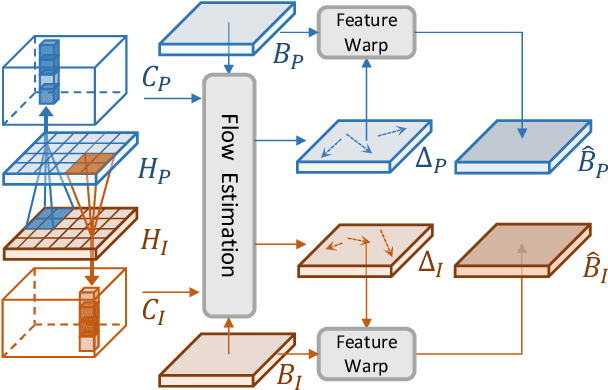
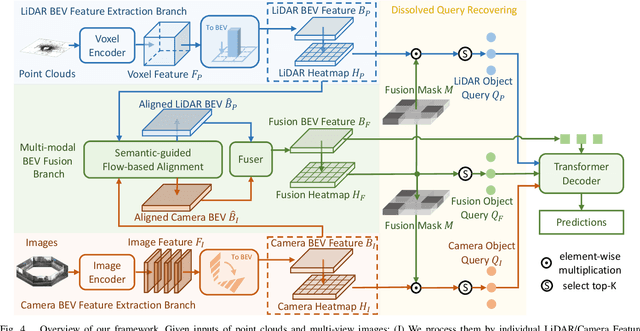
Recent 3D object detectors typically utilize multi-sensor data and unify multi-modal features in the shared bird's-eye view (BEV) representation space. However, our empirical findings indicate that previous methods have limitations in generating fusion BEV features free from cross-modal conflicts. These conflicts encompass extrinsic conflicts caused by BEV feature construction and inherent conflicts stemming from heterogeneous sensor signals. Therefore, we propose a novel Eliminating Conflicts Fusion (ECFusion) method to explicitly eliminate the extrinsic/inherent conflicts in BEV space and produce improved multi-modal BEV features. Specifically, we devise a Semantic-guided Flow-based Alignment (SFA) module to resolve extrinsic conflicts via unifying spatial distribution in BEV space before fusion. Moreover, we design a Dissolved Query Recovering (DQR) mechanism to remedy inherent conflicts by preserving objectness clues that are lost in the fusion BEV feature. In general, our method maximizes the effective information utilization of each modality and leverages inter-modal complementarity. Our method achieves state-of-the-art performance in the highly competitive nuScenes 3D object detection dataset. The code is released at https://github.com/fjhzhixi/ECFusion.
VcT: Visual change Transformer for Remote Sensing Image Change Detection
Oct 17, 2023Existing visual change detectors usually adopt CNNs or Transformers for feature representation learning and focus on learning effective representation for the changed regions between images. Although good performance can be obtained by enhancing the features of the change regions, however, these works are still limited mainly due to the ignorance of mining the unchanged background context information. It is known that one main challenge for change detection is how to obtain the consistent representations for two images involving different variations, such as spatial variation, sunlight intensity, etc. In this work, we demonstrate that carefully mining the common background information provides an important cue to learn the consistent representations for the two images which thus obviously facilitates the visual change detection problem. Based on this observation, we propose a novel Visual change Transformer (VcT) model for visual change detection problem. To be specific, a shared backbone network is first used to extract the feature maps for the given image pair. Then, each pixel of feature map is regarded as a graph node and the graph neural network is proposed to model the structured information for coarse change map prediction. Top-K reliable tokens can be mined from the map and refined by using the clustering algorithm. Then, these reliable tokens are enhanced by first utilizing self/cross-attention schemes and then interacting with original features via an anchor-primary attention learning module. Finally, the prediction head is proposed to get a more accurate change map. Extensive experiments on multiple benchmark datasets validated the effectiveness of our proposed VcT model.
Object as Query: Equipping Any 2D Object Detector with 3D Detection Ability
Jan 06, 2023



3D object detection from multi-view images has drawn much attention over the past few years. Existing methods mainly establish 3D representations from multi-view images and adopt a dense detection head for object detection, or employ object queries distributed in 3D space to localize objects. In this paper, we design Multi-View 2D Objects guided 3D Object Detector (MV2D), which can be equipped with any 2D object detector to promote multi-view 3D object detection. Since 2D detections can provide valuable priors for object existence, MV2D exploits 2D detector to generate object queries conditioned on the rich image semantics. These dynamically generated queries enable MV2D to detect objects in larger 3D space without increased computational costs and shows a strong capability of localizing 3D objects. For the generated queries, we design a sparse cross attention module to force them to focus on the features of specific objects, which reduces the computational cost and suppresses interference from noises. The evaluation results on the nuScenes dataset demonstrate that dynamic object queries and sparse feature aggregation do not harm 3D detection capability. MV2D also exhibits a state-of-the-art performance among existing methods. We hope MV2D can serve as a new baseline for future research.
Multi-view Human Body Mesh Translator
Oct 04, 2022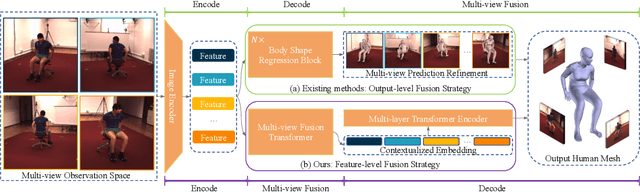
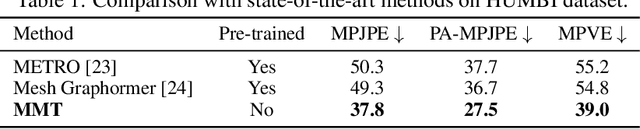
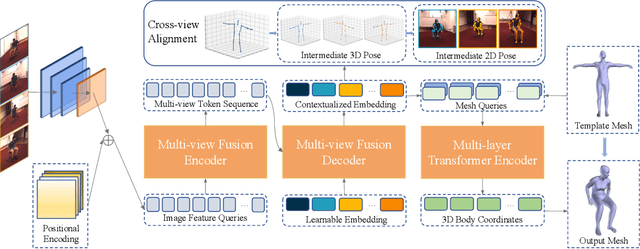

Existing methods for human mesh recovery mainly focus on single-view frameworks, but they often fail to produce accurate results due to the ill-posed setup. Considering the maturity of the multi-view motion capture system, in this paper, we propose to solve the prior ill-posed problem by leveraging multiple images from different views, thus significantly enhancing the quality of recovered meshes. In particular, we present a novel \textbf{M}ulti-view human body \textbf{M}esh \textbf{T}ranslator (MMT) model for estimating human body mesh with the help of vision transformer. Specifically, MMT takes multi-view images as input and translates them to targeted meshes in a single-forward manner. MMT fuses features of different views in both encoding and decoding phases, leading to representations embedded with global information. Additionally, to ensure the tokens are intensively focused on the human pose and shape, MMT conducts cross-view alignment at the feature level by projecting 3D keypoint positions to each view and enforcing their consistency in geometry constraints. Comprehensive experiments demonstrate that MMT outperforms existing single or multi-view models by a large margin for human mesh recovery task, notably, 28.8\% improvement in MPVE over the current state-of-the-art method on the challenging HUMBI dataset. Qualitative evaluation also verifies the effectiveness of MMT in reconstructing high-quality human mesh. Codes will be made available upon acceptance.