 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Aware Reasoning over Incomplete Knowledge Graph with Graph-Based Soft Prompting
Apr 14, 2026Large Language Models (LLMs) have shown remarkable capabilities across various tasks but remain prone to hallucinations in knowledge-intensive scenarios. Knowledge Base Question Answering (KBQA) mitigates this by grounding generation in Knowledge Graphs (KGs). However, most multi-hop KBQA methods rely on explicit edge traversal, making them fragile to KG incompleteness. In this paper, we proposed a novel graph-based soft prompting framework that shifts the reasoning paradigm from node-level path traversal to subgraph-level reasoning. Specifically, we employ a Graph Neural Network (GNN) to encode extracted structural subgraphs into soft prompts, enabling LLM to reason over richer structural context and identify relevant entities beyond immediate graph neighbors, thereby reducing sensitivity to missing edges. Furthermore, we introduce a two-stage paradigm that reduces computational cost while preserving good performance: a lightweight LLM first leverages the soft prompts to identify question-relevant entities and relations, followed by a more powerful LLM for evidence-aware answer generation. Experiments on four multi-hop KBQA benchmarks show that our approach achieves state-of-the-art performance on three of them, demonstrating its effectiveness. Code is available at the repository: https://github.com/Wangshuaiia/GraSP.
Domain-Adapted Pre-trained Language Models for Implicit Information Extraction in Crash Narratives
Oct 10, 2025



Free-text crash narratives recorded in real-world crash databases have been shown to play a significant role in improving traffic safety. However, large-scale analyses remain difficult to implement as there are no documented tools that can batch process the unstructured, non standardized text content written by various authors with diverse experience and attention to detail. In recent years, Transformer-based pre-trained language models (PLMs), such as Bidirectional Encoder Representations from Transformers (BERT) and large language models (LLMs), have demonstrated strong capabilities across various natural language processing tasks. These models can extract explicit facts from crash narratives, but their performance declines on inference-heavy tasks in, for example, Crash Type identification, which can involve nearly 100 categories. Moreover, relying on closed LLMs through external APIs raises privacy concerns for sensitive crash data. Additionally, these black-box tools often underperform due to limited domain knowledge. Motivated by these challenges, we study whether compact open-source PLMs can support reasoning-intensive extraction from crash narratives. We target two challenging objectives: 1) identifying the Manner of Collision for a crash, and 2) Crash Type for each vehicle involved in the crash event from real-world crash narratives. To bridge domain gaps, we apply fine-tuning techniques to inject task-specific knowledge to LLMs with Low-Rank Adaption (LoRA) and BERT. Experiments on the authoritative real-world dataset Crash Investigation Sampling System (CISS) demonstrate that our fine-tuned compact models outperform strong closed LLMs, such as GPT-4o, while requiring only minimal training resources. Further analysis reveals that the fine-tuned PLMs can capture richer narrative details and even correct some mislabeled annotations in the dataset.
Plugging Schema Graph into Multi-Table QA: A Human-Guided Framework for Reducing LLM Reliance
Jun 04, 2025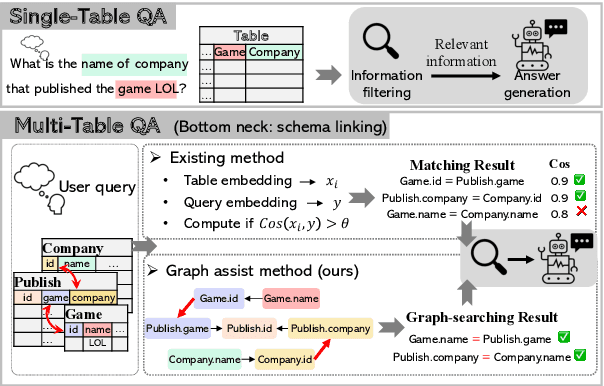
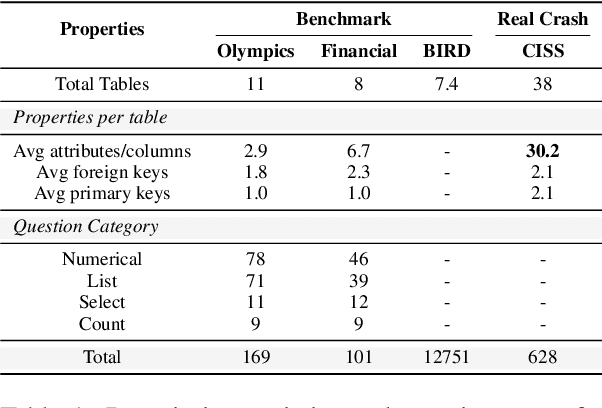
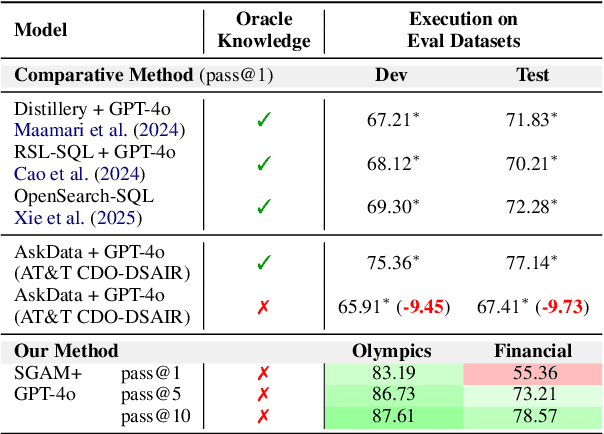
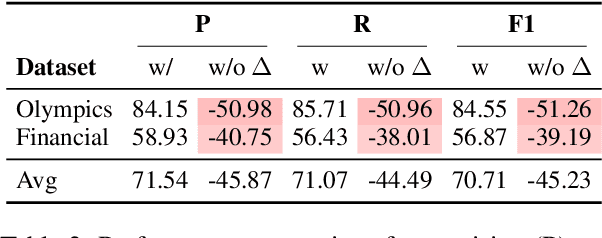
Large language models (LLMs) have shown promise in table Question Answering (Table QA). However, extending these capabilities to multi-table QA remains challenging due to unreliable schema linking across complex tables. Existing methods based on semantic similarity work well only on simplified hand-crafted datasets and struggle to handle complex, real-world scenarios with numerous and diverse columns. To address this, we propose a graph-based framework that leverages human-curated relational knowledge to explicitly encode schema links and join paths. Given a natural language query, our method searches this graph to construct interpretable reasoning chains, aided by pruning and sub-path merging strategies to enhance efficiency and coherence. Experiments on both standard benchmarks and a realistic, large-scale dataset demonstrate the effectiveness of our approach. To our knowledge, this is the first multi-table QA system applied to truly complex industrial tabular data.
MambaEVT: Event Stream based Visual Object Tracking using State Space Model
Aug 20, 2024



Event camera-based visual tracking has drawn more and more attention in recent years due to the unique imaging principle and advantages of low energy consumption, high dynamic range, and dense temporal resolution. Current event-based tracking algorithms are gradually hitting their performance bottlenecks, due to the utilization of vision Transformer and the static template for target object localization. In this paper, we propose a novel Mamba-based visual tracking framework that adopts the state space model with linear complexity as a backbone network. The search regions and target template are fed into the vision Mamba network for simultaneous feature extraction and interaction. The output tokens of search regions will be fed into the tracking head for target localization. More importantly, we consider introducing a dynamic template update strategy into the tracking framework using the Memory Mamba network. By considering the diversity of samples in the target template library and making appropriate adjustments to the template memory module, a more effective dynamic template can be integrated. The effective combination of dynamic and static templates allows our Mamba-based tracking algorithm to achieve a good balance between accuracy and computational cost on multiple large-scale datasets, including EventVOT, VisEvent, and FE240hz. The source code will be released on https://github.com/Event-AHU/MambaEVT
Treat Stillness with Movement: Remote Sensing Change Detection via Coarse-grained Temporal Foregrounds Mining
Aug 15, 2024
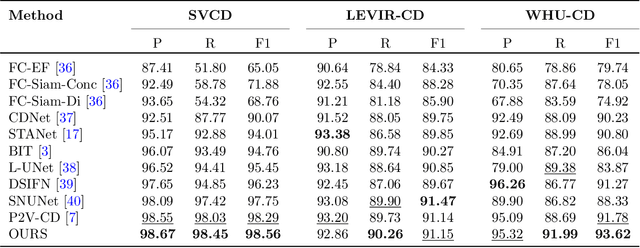
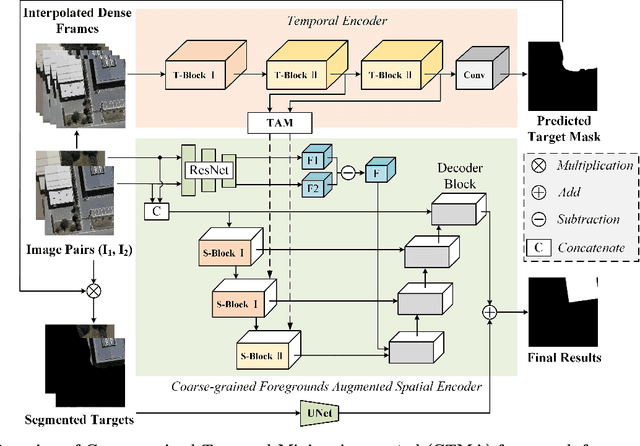

Current works focus on addressing the remote sensing change detection task using bi-temporal images. Although good performance can be achieved, however, seldom of they consider the motion cues which may also be vital. In this work, we revisit the widely adopted bi-temporal images-based framework and propose a novel Coarse-grained Temporal Mining Augmented (CTMA) framework. To be specific, given the bi-temporal images, we first transform them into a video using interpolation operations. Then, a set of temporal encoders is adopted to extract the motion features from the obtained video for coarse-grained changed region prediction. Subsequently, we design a novel Coarse-grained Foregrounds Augmented Spatial Encoder module to integrate both global and local information. We also introduce a motion augmented strategy that leverages motion cues as an additional output to aggregate with the spatial features for improved results. Meanwhile, we feed the input image pairs into the ResNet to get the different features and also the spatial blocks for fine-grained feature learning. More importantly, we propose a mask augmented strategy that utilizes coarse-grained changed regions, incorporating them into the decoder blocks to enhance the final changed prediction. Extensive experiments conducted on multiple benchmark datasets fully validated the effectiveness of our proposed framework for remote sensing image change detection. The source code of this paper will be released on https://github.com/Event-AHU/CTM_Remote_Sensing_Change_Detection
Ultrasound SAM Adapter: Adapting SAM for Breast Lesion Segmentation in Ultrasound Images
Apr 23, 2024



Segment Anything Model (SAM) has recently achieved amazing results in the field of natural image segmentation. However, it is not effective for medical image segmentation, owing to the large domain gap between natural and medical images. In this paper, we mainly focus on ultrasound image segmentation. As we know that it is very difficult to train a foundation model for ultrasound image data due to the lack of large-scale annotated ultrasound image data. To address these issues, in this paper, we develop a novel Breast Ultrasound SAM Adapter, termed Breast Ultrasound Segment Anything Model (BUSSAM), which migrates the SAM to the field of breast ultrasound image segmentation by using the adapter technique. To be specific, we first design a novel CNN image encoder, which is fully trained on the BUS dataset. Our CNN image encoder is more lightweight, and focuses more on features of local receptive field, which provides the complementary information to the ViT branch in SAM. Then, we design a novel Cross-Branch Adapter to allow the CNN image encoder to fully interact with the ViT image encoder in SAM module. Finally, we add both of the Position Adapter and the Feature Adapter to the ViT branch to fine-tune the original SAM. The experimental results on AMUBUS and BUSI datasets demonstrate that our proposed model outperforms other medical image segmentation models significantly. Our code will be available at: https://github.com/bscs12/BUSSAM.
VcT: Visual change Transformer for Remote Sensing Image Change Detection
Oct 17, 2023Existing visual change detectors usually adopt CNNs or Transformers for feature representation learning and focus on learning effective representation for the changed regions between images. Although good performance can be obtained by enhancing the features of the change regions, however, these works are still limited mainly due to the ignorance of mining the unchanged background context information. It is known that one main challenge for change detection is how to obtain the consistent representations for two images involving different variations, such as spatial variation, sunlight intensity, etc. In this work, we demonstrate that carefully mining the common background information provides an important cue to learn the consistent representations for the two images which thus obviously facilitates the visual change detection problem. Based on this observation, we propose a novel Visual change Transformer (VcT) model for visual change detection problem. To be specific, a shared backbone network is first used to extract the feature maps for the given image pair. Then, each pixel of feature map is regarded as a graph node and the graph neural network is proposed to model the structured information for coarse change map prediction. Top-K reliable tokens can be mined from the map and refined by using the clustering algorithm. Then, these reliable tokens are enhanced by first utilizing self/cross-attention schemes and then interacting with original features via an anchor-primary attention learning module. Finally, the prediction head is proposed to get a more accurate change map. Extensive experiments on multiple benchmark datasets validated the effectiveness of our proposed VcT model.
Rethinking Batch Sample Relationships for Data Representation: A Batch-Graph Transformer based Approach
Nov 19, 2022Exploring sample relationships within each mini-batch has shown great potential for learning image representations. Existing works generally adopt the regular Transformer to model the visual content relationships, ignoring the cues of semantic/label correlations between samples. Also, they generally adopt the "full" self-attention mechanism which are obviously redundant and also sensitive to the noisy samples. To overcome these issues, in this paper, we design a simple yet flexible Batch-Graph Transformer (BGFormer) for mini-batch sample representations by deeply capturing the relationships of image samples from both visual and semantic perspectives. BGFormer has three main aspects. (1) It employs a flexible graph model, termed Batch Graph to jointly encode the visual and semantic relationships of samples within each mini-batch. (2) It explores the neighborhood relationships of samples by borrowing the idea of sparse graph representation which thus performs robustly, w.r.t., noisy samples. (3) It devises a novel Transformer architecture that mainly adopts dual structure-constrained self-attention (SSA), together with graph normalization, FFN, etc, to carefully exploit the batch graph information for sample tokens (nodes) representations. As an application, we apply BGFormer to the metric learning tasks. Extensive experiments on four popular datasets demonstrate the effectiveness of the proposed model.
Few-Shot Learning Meets Transformer: Unified Query-Support Transformers for Few-Shot Classification
Aug 26, 2022



Few-shot classification which aims to recognize unseen classes using very limited samples has attracted more and more attention. Usually, it is formulated as a metric learning problem. The core issue of few-shot classification is how to learn (1) consistent representations for images in both support and query sets and (2) effective metric learning for images between support and query sets. In this paper, we show that the two challenges can be well modeled simultaneously via a unified Query-Support TransFormer (QSFormer) model. To be specific,the proposed QSFormer involves global query-support sample Transformer (sampleFormer) branch and local patch Transformer (patchFormer) learning branch. sampleFormer aims to capture the dependence of samples in support and query sets for image representation. It adopts the Encoder, Decoder and Cross-Attention to respectively model the Support, Query (image) representation and Metric learning for few-shot classification task. Also, as a complementary to global learning branch, we adopt a local patch Transformer to extract structural representation for each image sample by capturing the long-range dependence of local image patches. In addition, a novel Cross-scale Interactive Feature Extractor (CIFE) is proposed to extract and fuse multi-scale CNN features as an effective backbone module for the proposed few-shot learning method. All modules are integrated into a unified framework and trained in an end-to-end manner. Extensive experiments on four popular datasets demonstrate the effectiveness and superiority of the proposed QSFormer.
MutualFormer: Multi-Modality Representation Learning via Mutual Transformer
Dec 31, 2021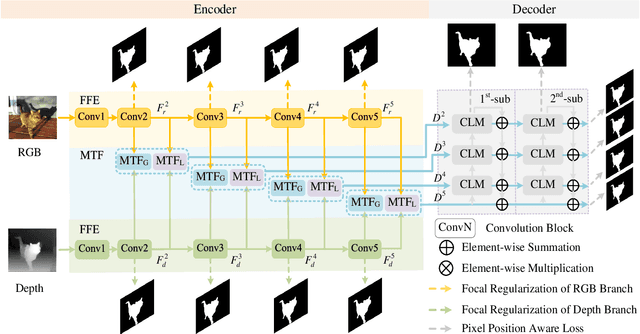
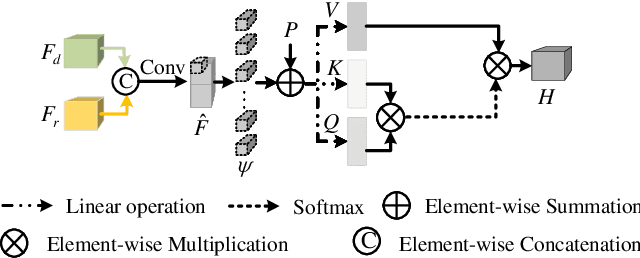
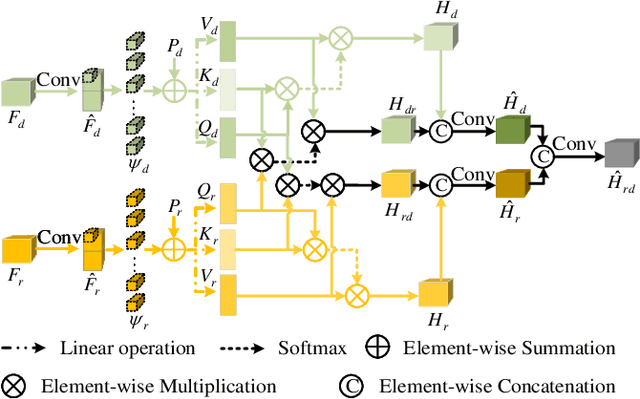
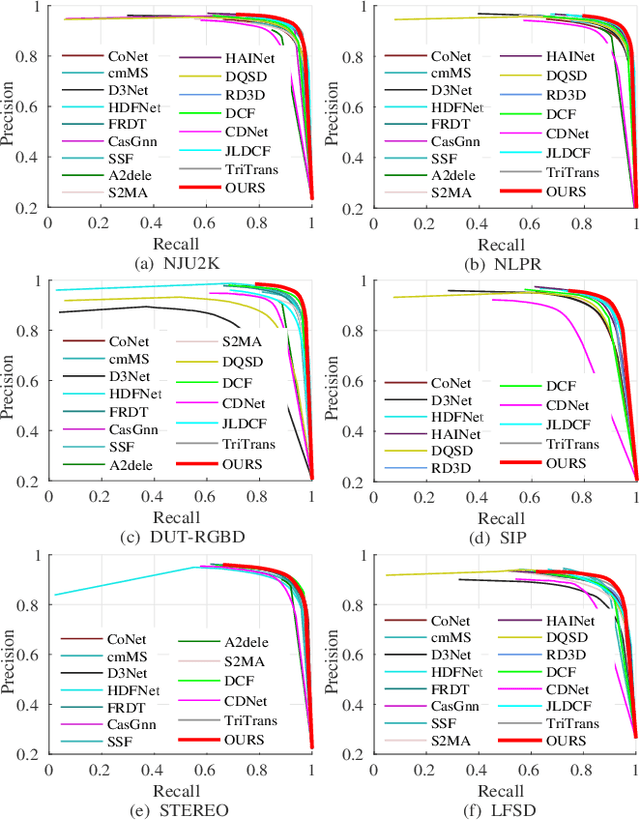
Aggregating multi-modality data to obtain accurate and reliable data representation attracts more and more attention. The pristine researchers generally adopt the CNN to extract features of independent modality and aggregate them with a fusion module. However, the overall performance is becoming saturated due to limited local convolutional features. Recent studies demonstrate that Transformer models usually work comparable or even better than CNN for multi-modality task, but they simply adopt concatenation or cross-attention for feature fusion which may just obtain sub-optimal results. In this work, we re-thinking the self-attention based Transformer and propose a novel MutualFormer for multi-modality data fusion and representation. The core of MutualFormer is the design of both token mixer and modality mixer to conduct the communication among both tokens and modalities. Specifically, it contains three main modules, i.e., i) Self-attention (SA) for intra-modality token mixer, ii) Cross-diffusion attention (CDA) for inter-modality mixer and iii) Aggregation module. The main advantage of the proposed CDA is that it is defined based on individual domain similarities in the metric space which thus can naturally avoid the issue of domain/modality gap in cross-modality similarities computation. We successfully apply the MutualFormer to the saliency detection problem and propose a novel approach to obtain the reinforced features of RGB and Depth images. Extensive experiments on six popular datasets demonstrate that our model achieves comparable results with 16 SOTA models.