 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Constrained Cross-Resolution Enhancement Network for Optics-Guided Thermal UAV Image Super-Resolution
Jan 07, 2026Optics-guided thermal UAV image super-resolution has attracted significant research interest due to its potential in all-weather monitoring applications. However, existing methods typically compress optical features to match thermal feature dimensions for cross-modal alignment and fusion, which not only causes the loss of high-frequency information that is beneficial for thermal super-resolution, but also introduces physically inconsistent artifacts such as texture distortions and edge blurring by overlooking differences in the imaging physics between modalities. To address these challenges, we propose PCNet to achieve cross-resolution mutual enhancement between optical and thermal modalities, while physically constraining the optical guidance process via thermal conduction to enable robust thermal UAV image super-resolution. In particular, we design a Cross-Resolution Mutual Enhancement Module (CRME) to jointly optimize thermal image super-resolution and optical-to-thermal modality conversion, facilitating effective bidirectional feature interaction across resolutions while preserving high-frequency optical priors. Moreover, we propose a Physics-Driven Thermal Conduction Module (PDTM) that incorporates two-dimensional heat conduction into optical guidance, modeling spatially-varying heat conduction properties to prevent inconsistent artifacts. In addition, we introduce a temperature consistency loss that enforces regional distribution consistency and boundary gradient smoothness to ensure generated thermal images align with real-world thermal radiation principles. Extensive experiments on VGTSR2.0 and DroneVehicle datasets demonstrate that PCNet significantly outperforms state-of-the-art methods on both reconstruction quality and downstream tasks including semantic segmentation and object detection.
Learning Where to Focus: Density-Driven Guidance for Detecting Dense Tiny Objects
Dec 28, 2025High-resolution remote sensing imagery increasingly contains dense clusters of tiny objects, the detection of which is extremely challenging due to severe mutual occlusion and limited pixel footprints. Existing detection methods typically allocate computational resources uniformly, failing to adaptively focus on these density-concentrated regions, which hinders feature learning effectiveness. To address these limitations, we propose the Dense Region Mining Network (DRMNet), which leverages density maps as explicit spatial priors to guide adaptive feature learning. First, we design a Density Generation Branch (DGB) to model object distribution patterns, providing quantifiable priors that guide the network toward dense regions. Second, to address the computational bottleneck of global attention, our Dense Area Focusing Module (DAFM) uses these density maps to identify and focus on dense areas, enabling efficient local-global feature interaction. Finally, to mitigate feature degradation during hierarchical extraction, we introduce a Dual Filter Fusion Module (DFFM). It disentangles multi-scale features into high- and low-frequency components using a discrete cosine transform and then performs density-guided cross-attention to enhance complementarity while suppressing background interference. Extensive experiments on the AI-TOD and DTOD datasets demonstrate that DRMNet surpasses state-of-the-art methods, particularly in complex scenarios with high object density and severe occlusion.
Towards Robust Optical-SAR Object Detection under Missing Modalities: A Dynamic Quality-Aware Fusion Framework
Dec 27, 2025Optical and Synthetic Aperture Radar (SAR) fusion-based object detection has attracted significant research interest in remote sensing, as these modalities provide complementary information for all-weather monitoring. However, practical deployment is severely limited by inherent challenges. Due to distinct imaging mechanisms, temporal asynchrony, and registration difficulties, obtaining well-aligned optical-SAR image pairs remains extremely difficult, frequently resulting in missing or degraded modality data. Although recent approaches have attempted to address this issue, they still suffer from limited robustness to random missing modalities and lack effective mechanisms to ensure consistent performance improvement in fusion-based detection. To address these limitations, we propose a novel Quality-Aware Dynamic Fusion Network (QDFNet) for robust optical-SAR object detection. Our proposed method leverages learnable reference tokens to dynamically assess feature reliability and guide adaptive fusion in the presence of missing modalities. In particular, we design a Dynamic Modality Quality Assessment (DMQA) module that employs learnable reference tokens to iteratively refine feature reliability assessment, enabling precise identification of degraded regions and providing quality guidance for subsequent fusion. Moreover, we develop an Orthogonal Constraint Normalization Fusion (OCNF) module that employs orthogonal constraints to preserve modality independence while dynamically adjusting fusion weights based on reliability scores, effectively suppressing unreliable feature propagation. Extensive experiments on the SpaceNet6-OTD and OGSOD-2.0 datasets demonstrate the superiority and effectiveness of QDFNet compared to state-of-the-art methods, particularly under partial modality corruption or missing data scenarios.
Beyond Time: Cross-Dimensional Frequency Supervision for Time Series Forecasting
May 16, 2025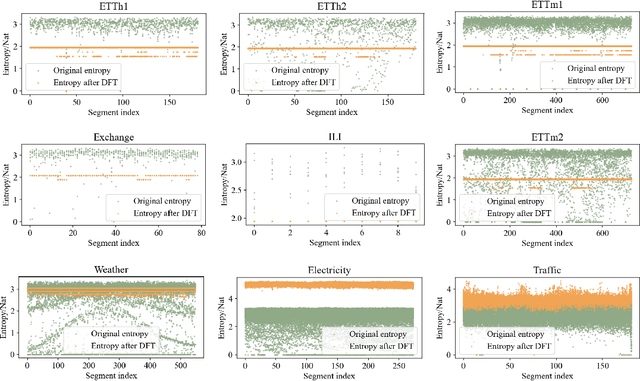
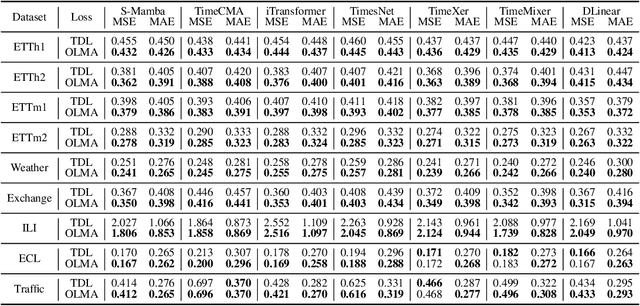
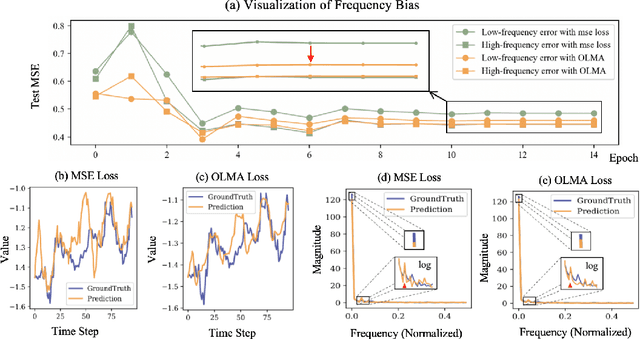
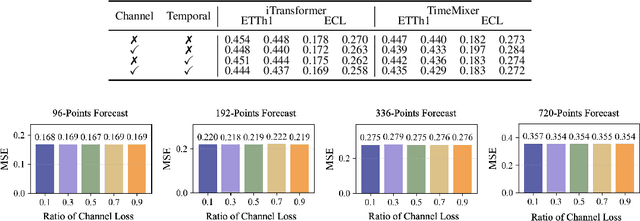
Time series forecasting plays a crucial role in various fields, and the methods based on frequency domain analysis have become an important branch. However, most existing studies focus on the design of elaborate model architectures and are often tailored for limited datasets, still lacking universality. Besides, the assumption of independent and identically distributed (IID) data also contradicts the strong correlation of the time domain labels. To address these issues, abandoning time domain supervision, we propose a purely frequency domain supervision approach named cross-dimensional frequency (X-Freq) loss. Specifically, based on a statistical phenomenon, we first prove that the information entropy of the time series is higher than its spectral entropy, which implies higher certainty in frequency domain and thus can provide better supervision. Secondly, the Fourier Transform and the Wavelet Transform are applied to the time dimension and the channel dimension of the time series respectively, to capture the long-term and short-term frequency variations as well as the spatial configuration features. Thirdly, the loss between predictions and targets is uniformly computed in the frequency domain. Moreover, we plug-and-play incorporate X-Freq into multiple advanced forecasting models and compare on 14 real-world datasets. The experimental results demonstrate that, without making any modification to the original architectures or hyperparameters, X-Freq can improve the forecasting performance by an average of 3.3% on long-term forecasting datasets and 27.7% on short-term ones, showcasing superior generality and practicality. The code will be released publicly.
DehazeMamba: SAR-guided Optical Remote Sensing Image Dehazing with Adaptive State Space Model
Mar 17, 2025



Optical remote sensing image dehazing presents significant challenges due to its extensive spatial scale and highly non-uniform haze distribution, which traditional single-image dehazing methods struggle to address effectively. While Synthetic Aperture Radar (SAR) imagery offers inherently haze-free reference information for large-scale scenes, existing SAR-guided dehazing approaches face two critical limitations: the integration of SAR information often diminishes the quality of haze-free regions, and the instability of feature quality further exacerbates cross-modal domain shift. To overcome these challenges, we introduce DehazeMamba, a novel SAR-guided dehazing network built on a progressive haze decoupling fusion strategy. Our approach incorporates two key innovations: a Haze Perception and Decoupling Module (HPDM) that dynamically identifies haze-affected regions through optical-SAR difference analysis, and a Progressive Fusion Module (PFM) that mitigates domain shift through a two-stage fusion process based on feature quality assessment. To facilitate research in this domain, we present MRSHaze, a large-scale benchmark dataset comprising 8,000 pairs of temporally synchronized, precisely geo-registered SAR-optical images with high resolution and diverse haze conditions. Extensive experiments demonstrate that DehazeMamba significantly outperforms state-of-the-art methods, achieving a 0.73 dB improvement in PSNR and substantial enhancements in downstream tasks such as semantic segmentation. The dataset is available at https://github.com/mmic-lcl/Datasets-and-benchmark-code.
CPAny: Couple With Any Encoder to Refer Multi-Object Tracking
Mar 10, 2025Referring Multi-Object Tracking (RMOT) aims to localize target trajectories specified by natural language expressions in videos. Existing RMOT methods mainly follow two paradigms, namely, one-stage strategies and two-stage ones. The former jointly trains tracking with referring but suffers from substantial computational overhead. Although the latter improves computational efficiency, its CLIP-inspired dual-tower architecture restricts compatibility with other visual/text backbones and is not future-proof. To overcome these limitations, we propose CPAny, a novel encoder-decoder framework for two-stage RMOT, which introduces two core components: (1) a Contextual Visual Semantic Abstractor (CVSA) performs context-aware aggregation on visual backbone features and projects them into a unified semantic space; (2) a Parallel Semantic Summarizer (PSS) decodes the visual and linguistic features at the semantic level in parallel and generates referring scores. By replacing the inherent feature alignment of encoders with a self-constructed unified semantic space, CPAny achieves flexible compatibility with arbitrary emerging visual / text encoders. Meanwhile, CPAny aggregates contextual information by encoding only once and processes multiple expressions in parallel, significantly reducing computational redundancy. Extensive experiments on the Refer-KITTI and Refer-KITTI-V2 datasets show that CPAny outperforms SOTA methods across diverse encoder combinations, with a particular 7.77\% HOTA improvement on Refer-KITTI-V2. Code will be available soon.
Data-Efficient Generalization for Zero-shot Composed Image Retrieval
Mar 07, 2025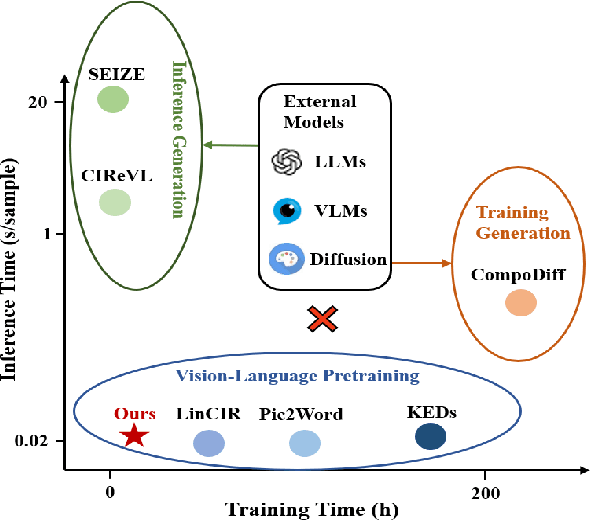
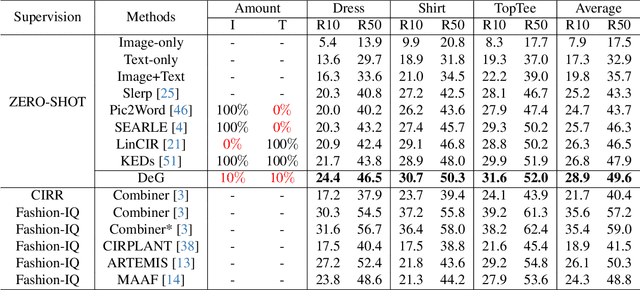
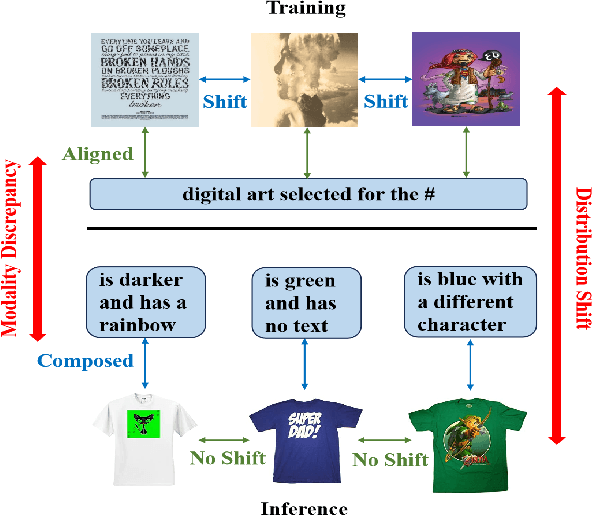
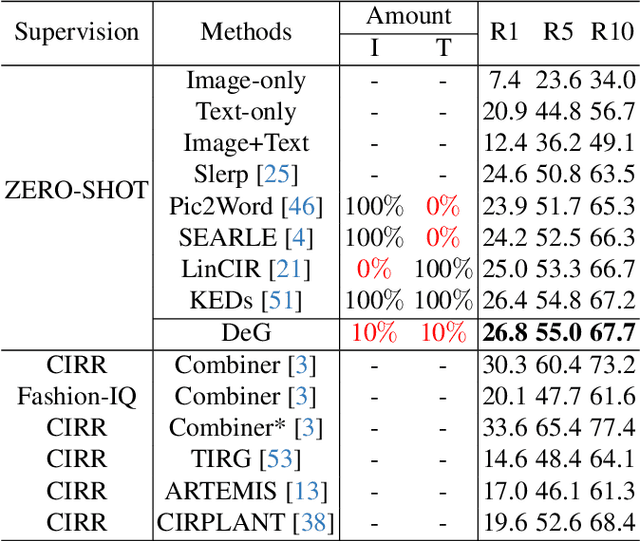
Zero-shot Composed Image Retrieval (ZS-CIR) aims to retrieve the target image based on a reference image and a text description without requiring in-distribution triplets for training. One prevalent approach follows the vision-language pretraining paradigm that employs a mapping network to transfer the image embedding to a pseudo-word token in the text embedding space. However, this approach tends to impede network generalization due to modality discrepancy and distribution shift between training and inference. To this end, we propose a Data-efficient Generalization (DeG) framework, including two novel designs, namely, Textual Supplement (TS) module and Semantic-Set (S-Set). The TS module exploits compositional textual semantics during training, enhancing the pseudo-word token with more linguistic semantics and thus mitigating the modality discrepancy effectively. The S-Set exploits the zero-shot capability of pretrained Vision-Language Models (VLMs), alleviating the distribution shift and mitigating the overfitting issue from the redundancy of the large-scale image-text data. Extensive experiments over four ZS-CIR benchmarks show that DeG outperforms the state-of-the-art (SOTA) methods with much less training data, and saves substantial training and inference time for practical usage.
A Multi-Modal Deep Learning Framework for Pan-Cancer Prognosis
Jan 13, 2025Prognostic task is of great importance as it closely related to the survival analysis of patients, the optimization of treatment plans and the allocation of resources. The existing prognostic models have shown promising results on specific datasets, but there are limitations in two aspects. On the one hand, they merely explore certain types of modal data, such as patient histopathology WSI and gene expression analysis. On the other hand, they adopt the per-cancer-per-model paradigm, which means the trained models can only predict the prognostic effect of a single type of cancer, resulting in weak generalization ability. In this paper, a deep-learning based model, named UMPSNet, is proposed. Specifically, to comprehensively understand the condition of patients, in addition to constructing encoders for histopathology images and genomic expression profiles respectively, UMPSNet further integrates four types of important meta data (demographic information, cancer type information, treatment protocols, and diagnosis results) into text templates, and then introduces a text encoder to extract textual features. In addition, the optimal transport OT-based attention mechanism is utilized to align and fuse features of different modalities. Furthermore, a guided soft mixture of experts (GMoE) mechanism is introduced to effectively address the issue of distribution differences among multiple cancer datasets. By incorporating the multi-modality of patient data and joint training, UMPSNet outperforms all SOTA approaches, and moreover, it demonstrates the effectiveness and generalization ability of the proposed learning paradigm of a single model for multiple cancer types. The code of UMPSNet is available at https://github.com/binging512/UMPSNet.
ICFNet: Integrated Cross-modal Fusion Network for Survival Prediction
Jan 06, 2025



Survival prediction is a crucial task in the medical field and is essential for optimizing treatment options and resource allocation. However, current methods often rely on limited data modalities, resulting in suboptimal performance. In this paper, we propose an Integrated Cross-modal Fusion Network (ICFNet) that integrates histopathology whole slide images, genomic expression profiles, patient demographics, and treatment protocols. Specifically, three types of encoders, a residual orthogonal decomposition module and a unification fusion module are employed to merge multi-modal features to enhance prediction accuracy. Additionally, a balanced negative log-likelihood loss function is designed to ensure fair training across different patients. Extensive experiments demonstrate that our ICFNet outperforms state-of-the-art algorithms on five public TCGA datasets, including BLCA, BRCA, GBMLGG, LUAD, and UCEC, and shows its potential to support clinical decision-making and advance precision medicine. The codes are available at: https://github.com/binging512/ICFNet.
VELoRA: A Low-Rank Adaptation Approach for Efficient RGB-Event based Recognition
Dec 28, 2024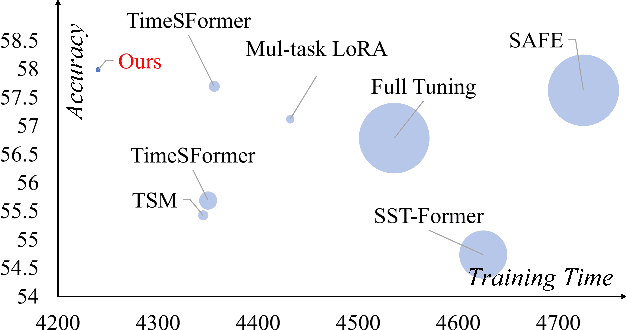
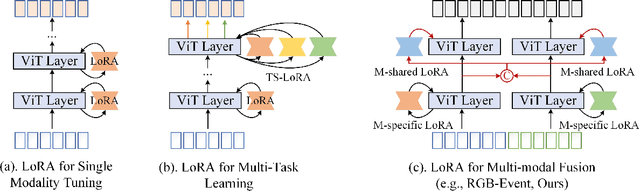
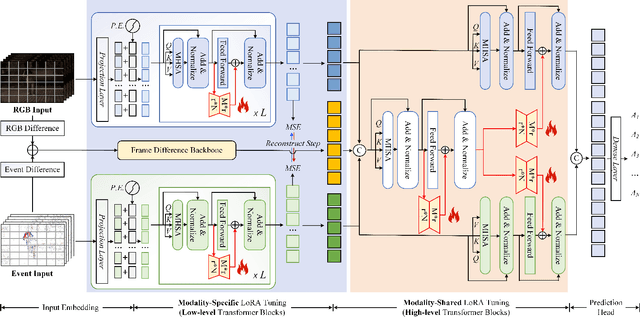
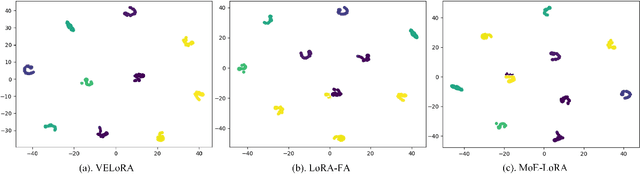
Pattern recognition leveraging both RGB and Event cameras can significantly enhance performance by deploying deep neural networks that utilize a fine-tuning strategy. Inspired by the successful application of large models, the introduction of such large models can also be considered to further enhance the performance of multi-modal tasks. However, fully fine-tuning these models leads to inefficiency and lightweight fine-tuning methods such as LoRA and Adapter have been proposed to achieve a better balance between efficiency and performance. To our knowledge, there is currently no work that has conducted parameter-efficient fine-tuning (PEFT) for RGB-Event recognition based on pre-trained foundation models. To address this issue, this paper proposes a novel PEFT strategy to adapt the pre-trained foundation vision models for the RGB-Event-based classification. Specifically, given the RGB frames and event streams, we extract the RGB and event features based on the vision foundation model ViT with a modality-specific LoRA tuning strategy. The frame difference of the dual modalities is also considered to capture the motion cues via the frame difference backbone network. These features are concatenated and fed into high-level Transformer layers for efficient multi-modal feature learning via modality-shared LoRA tuning. Finally, we concatenate these features and feed them into a classification head to achieve efficient fine-tuning. The source code and pre-trained models will be released on \url{https://github.com/Event-AHU/VELoRA}.