 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Knowledge Purification in Multi-Teacher Knowledge Distillation for LLMs
Feb 01, 2026Knowledge distillation has emerged as a pivotal technique for transferring knowledge from stronger large language models (LLMs) to smaller, more efficient models. However, traditional distillation approaches face challenges related to knowledge conflicts and high resource demands, particularly when leveraging multiple teacher models. In this paper, we introduce the concept of \textbf{Knowledge Purification}, which consolidates the rationales from multiple teacher LLMs into a single rationale, thereby mitigating conflicts and enhancing efficiency. To investigate the effectiveness of knowledge purification, we further propose five purification methods from various perspectives. Our experiments demonstrate that these methods not only improve the performance of the distilled model but also effectively alleviate knowledge conflicts. Moreover, router-based methods exhibit robust generalization capabilities, underscoring the potential of innovative purification techniques in optimizing multi-teacher distillation and facilitating the practical deployment of powerful yet lightweight models.
RadialRouter: Structured Representation for Efficient and Robust Large Language Models Routing
Jun 04, 2025The rapid advancements in large language models (LLMs) have led to the emergence of routing techniques, which aim to efficiently select the optimal LLM from diverse candidates to tackle specific tasks, optimizing performance while reducing costs. Current LLM routing methods are limited in effectiveness due to insufficient exploration of the intrinsic connection between user queries and the characteristics of LLMs. To address this issue, in this paper, we present RadialRouter, a novel framework for LLM routing which employs a lightweight Transformer-based backbone with a radial structure named RadialFormer to articulate the query-LLMs relationship. The optimal LLM selection is performed based on the final states of RadialFormer. The pipeline is further refined by an objective function that combines Kullback-Leibler divergence with the query-query contrastive loss to enhance robustness. Experimental results on RouterBench show that RadialRouter significantly outperforms existing routing methods by 9.2\% and 5.8\% in the Balance and Cost First scenarios, respectively. Additionally, its adaptability toward different performance-cost trade-offs and the dynamic LLM pool demonstrates practical application potential.
ELDeR: Getting Efficient LLMs through Data-Driven Regularized Layer-wise Pruning
May 23, 2025The deployment of Large language models (LLMs) in many fields is largely hindered by their high computational and memory costs. Recent studies suggest that LLMs exhibit sparsity, which can be used for pruning. Previous pruning methods typically follow a prune-then-finetune paradigm. Since the pruned parts still contain valuable information, statically removing them without updating the remaining parameters often results in irreversible performance degradation, requiring costly recovery fine-tuning (RFT) to maintain performance. To address this, we propose a novel paradigm: first apply regularization, then prune. Based on this paradigm, we propose ELDeR: Getting Efficient LLMs through Data-Driven Regularized Layer-wise Pruning. We multiply the output of each transformer layer by an initial weight, then we iteratively learn the weights of each transformer layer by using a small amount of data in a simple way. After that, we apply regularization to the difference between the output and input of the layers with smaller weights, forcing the information to be transferred to the remaining layers. Compared with direct pruning, ELDeR reduces the information loss caused by direct parameter removal, thus better preserving the model's language modeling ability. Experimental results show that ELDeR achieves superior performance compared with powerful layer-wise structured pruning methods, while greatly reducing RFT computational costs. Since ELDeR is a layer-wise pruning method, its end-to-end acceleration effect is obvious, making it a promising technique for efficient LLMs.
Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities
May 21, 2025Reinforcement learning (RL) has emerged as an effective method for training reasoning models. However, existing RL approaches typically bias the model's output distribution toward reward-maximizing paths without introducing external knowledge. This limits their exploration capacity and results in a narrower reasoning capability boundary compared to base models. To address this limitation, we propose TAPO (Thought-Augmented Policy Optimization), a novel framework that augments RL by incorporating external high-level guidance ("thought patterns"). By adaptively integrating structured thoughts during training, TAPO effectively balances model-internal exploration and external guidance exploitation. Extensive experiments show that our approach significantly outperforms GRPO by 99% on AIME, 41% on AMC, and 17% on Minerva Math. Notably, these high-level thought patterns, abstracted from only 500 prior samples, generalize effectively across various tasks and models. This highlights TAPO's potential for broader applications across multiple tasks and domains. Our further analysis reveals that introducing external guidance produces powerful reasoning models with superior explainability of inference behavior and enhanced output readability.
DReSS: Data-driven Regularized Structured Streamlining for Large Language Models
Jan 29, 2025



Large language models (LLMs) have achieved significant progress across various domains, but their increasing scale results in high computational and memory costs. Recent studies have revealed that LLMs exhibit sparsity, providing the potential to reduce model size through pruning techniques. However, existing pruning methods typically follow a prune-then-finetune paradigm. Since the pruned components still contain valuable information, their direct removal often leads to irreversible performance degradation, imposing a substantial computational burden to recover performance during finetuning. In this paper, we propose a novel paradigm that first applies regularization, then prunes, and finally finetunes. Based on this paradigm, we introduce DReSS, a simple and effective Data-driven Regularized Structured Streamlining method for LLMs. By leveraging a small amount of data to regularize the components to be pruned, DReSS explicitly transfers the important information to the remaining parts of the model in advance. Compared to direct pruning, this can reduce the information loss caused by parameter removal, thereby enhancing its language modeling capabilities. Experimental results demonstrate that DReSS significantly outperforms existing pruning methods even under extreme pruning ratios, significantly reducing latency and increasing throughput.
VELoRA: A Low-Rank Adaptation Approach for Efficient RGB-Event based Recognition
Dec 28, 2024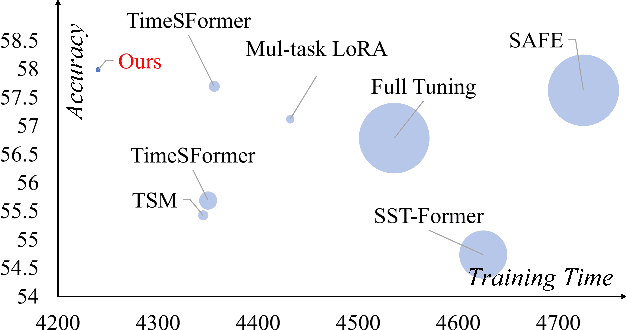
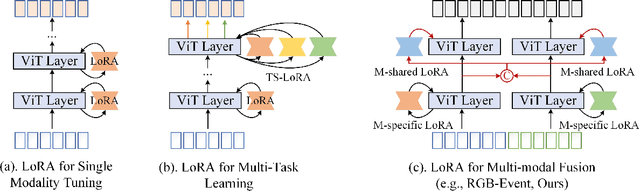
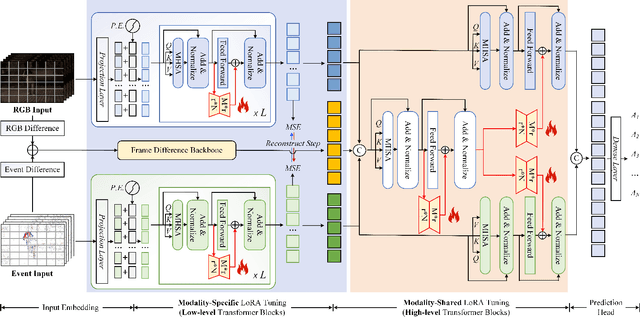
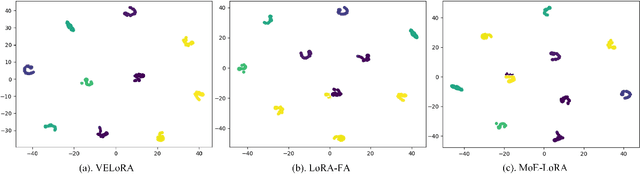
Pattern recognition leveraging both RGB and Event cameras can significantly enhance performance by deploying deep neural networks that utilize a fine-tuning strategy. Inspired by the successful application of large models, the introduction of such large models can also be considered to further enhance the performance of multi-modal tasks. However, fully fine-tuning these models leads to inefficiency and lightweight fine-tuning methods such as LoRA and Adapter have been proposed to achieve a better balance between efficiency and performance. To our knowledge, there is currently no work that has conducted parameter-efficient fine-tuning (PEFT) for RGB-Event recognition based on pre-trained foundation models. To address this issue, this paper proposes a novel PEFT strategy to adapt the pre-trained foundation vision models for the RGB-Event-based classification. Specifically, given the RGB frames and event streams, we extract the RGB and event features based on the vision foundation model ViT with a modality-specific LoRA tuning strategy. The frame difference of the dual modalities is also considered to capture the motion cues via the frame difference backbone network. These features are concatenated and fed into high-level Transformer layers for efficient multi-modal feature learning via modality-shared LoRA tuning. Finally, we concatenate these features and feed them into a classification head to achieve efficient fine-tuning. The source code and pre-trained models will be released on \url{https://github.com/Event-AHU/VELoRA}.
Pandora's Box or Aladdin's Lamp: A Comprehensive Analysis Revealing the Role of RAG Noise in Large Language Models
Aug 24, 2024



Retrieval-Augmented Generation (RAG) has emerged as a crucial method for addressing hallucinations in large language models (LLMs). While recent research has extended RAG models to complex noisy scenarios, these explorations often confine themselves to limited noise types and presuppose that noise is inherently detrimental to LLMs, potentially deviating from real-world retrieval environments and restricting practical applicability. In this paper, we define seven distinct noise types from a linguistic perspective and establish a Noise RAG Benchmark (NoiserBench), a comprehensive evaluation framework encompassing multiple datasets and reasoning tasks. Through empirical evaluation of eight representative LLMs with diverse architectures and scales, we reveal that these noises can be further categorized into two practical groups: noise that is beneficial to LLMs (aka beneficial noise) and noise that is harmful to LLMs (aka harmful noise). While harmful noise generally impairs performance, beneficial noise may enhance several aspects of model capabilities and overall performance. Our analysis offers insights for developing more robust, adaptable RAG solutions and mitigating hallucinations across diverse retrieval scenarios.
Event Stream based Human Action Recognition: A High-Definition Benchmark Dataset and Algorithms
Aug 19, 2024



Human Action Recognition (HAR) stands as a pivotal research domain in both computer vision and artificial intelligence, with RGB cameras dominating as the preferred tool for investigation and innovation in this field. However, in real-world applications, RGB cameras encounter numerous challenges, including light conditions, fast motion, and privacy concerns. Consequently, bio-inspired event cameras have garnered increasing attention due to their advantages of low energy consumption, high dynamic range, etc. Nevertheless, most existing event-based HAR datasets are low resolution ($346 \times 260$). In this paper, we propose a large-scale, high-definition ($1280 \times 800$) human action recognition dataset based on the CeleX-V event camera, termed CeleX-HAR. It encompasses 150 commonly occurring action categories, comprising a total of 124,625 video sequences. Various factors such as multi-view, illumination, action speed, and occlusion are considered when recording these data. To build a more comprehensive benchmark dataset, we report over 20 mainstream HAR models for future works to compare. In addition, we also propose a novel Mamba vision backbone network for event stream based HAR, termed EVMamba, which equips the spatial plane multi-directional scanning and novel voxel temporal scanning mechanism. By encoding and mining the spatio-temporal information of event streams, our EVMamba has achieved favorable results across multiple datasets. Both the dataset and source code will be released on \url{https://github.com/Event-AHU/CeleX-HAR}
Retain, Blend, and Exchange: A Quality-aware Spatial-Stereo Fusion Approach for Event Stream Recognition
Jun 27, 2024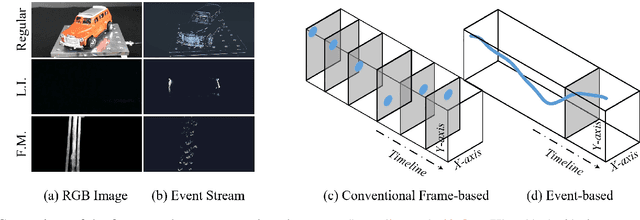
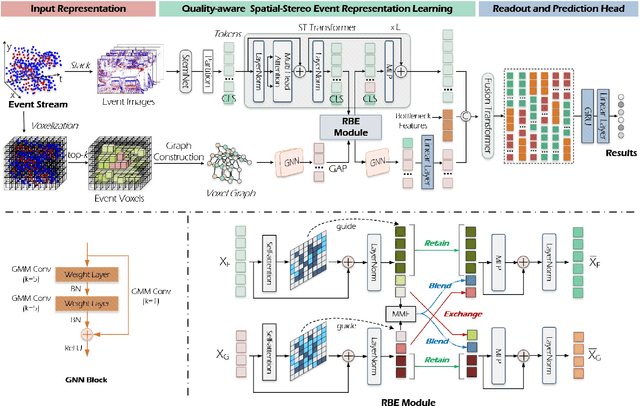
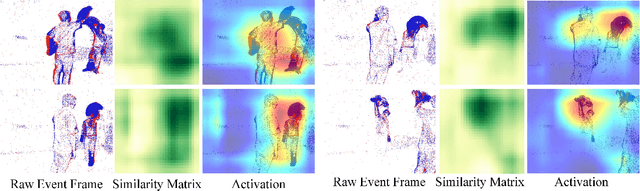
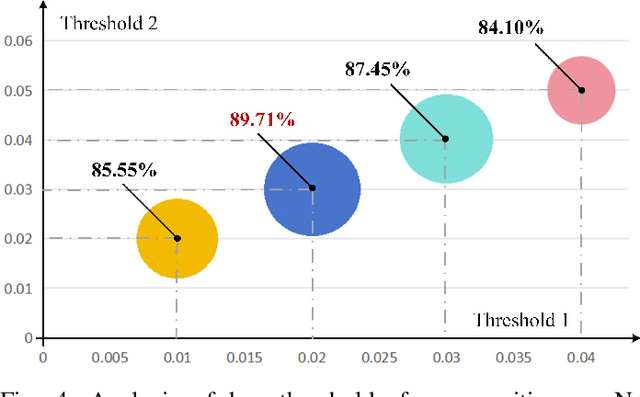
Existing event stream-based pattern recognition models usually represent the event stream as the point cloud, voxel, image, etc., and design various deep neural networks to learn their features. Although considerable results can be achieved in simple cases, however, the model performance may be limited by monotonous modality expressions, sub-optimal fusion, and readout mechanisms. In this paper, we propose a novel dual-stream framework for event stream-based pattern recognition via differentiated fusion, termed EFV++. It models two common event representations simultaneously, i.e., event images and event voxels. The spatial and three-dimensional stereo information can be learned separately by utilizing Transformer and Graph Neural Network (GNN). We believe the features of each representation still contain both efficient and redundant features and a sub-optimal solution may be obtained if we directly fuse them without differentiation. Thus, we divide each feature into three levels and retain high-quality features, blend medium-quality features, and exchange low-quality features. The enhanced dual features will be fed into the fusion Transformer together with bottleneck features. In addition, we introduce a novel hybrid interaction readout mechanism to enhance the diversity of features as final representations. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance on multiple widely used event stream-based classification datasets. Specifically, we achieve new state-of-the-art performance on the Bullying10k dataset, i.e., $90.51\%$, which exceeds the second place by $+2.21\%$. The source code of this paper has been released on \url{https://github.com/Event-AHU/EFV_event_classification/tree/EFVpp}.
Can large language models understand uncommon meanings of common words?
May 09, 2024Large language models (LLMs) like ChatGPT have shown significant advancements across diverse natural language understanding (NLU) tasks, including intelligent dialogue and autonomous agents. Yet, lacking widely acknowledged testing mechanisms, answering `whether LLMs are stochastic parrots or genuinely comprehend the world' remains unclear, fostering numerous studies and sparking heated debates. Prevailing research mainly focuses on surface-level NLU, neglecting fine-grained explorations. However, such explorations are crucial for understanding their unique comprehension mechanisms, aligning with human cognition, and finally enhancing LLMs' general NLU capacities. To address this gap, our study delves into LLMs' nuanced semantic comprehension capabilities, particularly regarding common words with uncommon meanings. The idea stems from foundational principles of human communication within psychology, which underscore accurate shared understandings of word semantics. Specifically, this paper presents the innovative construction of a Lexical Semantic Comprehension (LeSC) dataset with novel evaluation metrics, the first benchmark encompassing both fine-grained and cross-lingual dimensions. Introducing models of both open-source and closed-source, varied scales and architectures, our extensive empirical experiments demonstrate the inferior performance of existing models in this basic lexical-meaning understanding task. Notably, even the state-of-the-art LLMs GPT-4 and GPT-3.5 lag behind 16-year-old humans by 3.9% and 22.3%, respectively. Additionally, multiple advanced prompting techniques and retrieval-augmented generation are also introduced to help alleviate this trouble, yet limitations persist. By highlighting the above critical shortcomings, this research motivates further investigation and offers novel insights for developing more intelligent LLMs.