 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSL: Sweet Spot Learning for Differentiated Guidance in Agentic Optimization
Jan 30, 2026Reinforcement learning with verifiable rewards has emerged as a powerful paradigm for training intelligent agents. However, existing methods typically employ binary rewards that fail to capture quality differences among trajectories achieving identical outcomes, thereby overlooking potential diversity within the solution space. Inspired by the ``sweet spot'' concept in tennis-the racket's core region that produces optimal hitting effects, we introduce \textbf{S}weet \textbf{S}pot \textbf{L}earning (\textbf{SSL}), a novel framework that provides differentiated guidance for agent optimization. SSL follows a simple yet effective principle: progressively amplified, tiered rewards guide policies toward the sweet-spot region of the solution space. This principle naturally adapts across diverse tasks: visual perception tasks leverage distance-tiered modeling to reward proximity, while complex reasoning tasks reward incremental progress toward promising solutions. We theoretically demonstrate that SSL preserves optimal solution ordering and enhances the gradient signal-to-noise ratio, thereby fostering more directed optimization. Extensive experiments across GUI perception, short/long-term planning, and complex reasoning tasks show consistent improvements over strong baselines on 12 benchmarks, achieving up to 2.5X sample efficiency gains and effective cross-task transferability. Our work establishes SSL as a general principle for training capable and robust agents.
Unified Multimodal and Multilingual Retrieval via Multi-Task Learning with NLU Integration
Jan 21, 2026Multimodal retrieval systems typically employ Vision Language Models (VLMs) that encode images and text independently into vectors within a shared embedding space. Despite incorporating text encoders, VLMs consistently underperform specialized text models on text-only retrieval tasks. Moreover, introducing additional text encoders increases storage, inference overhead, and exacerbates retrieval inefficiencies, especially in multilingual settings. To address these limitations, we propose a multi-task learning framework that unifies the feature representation across images, long and short texts, and intent-rich queries. To our knowledge, this is the first work to jointly optimize multilingual image retrieval, text retrieval, and natural language understanding (NLU) tasks within a single framework. Our approach integrates image and text retrieval with a shared text encoder that is enhanced by NLU features for intent understanding and retrieval accuracy.
HyperVL: An Efficient and Dynamic Multimodal Large Language Model for Edge Devices
Dec 16, 2025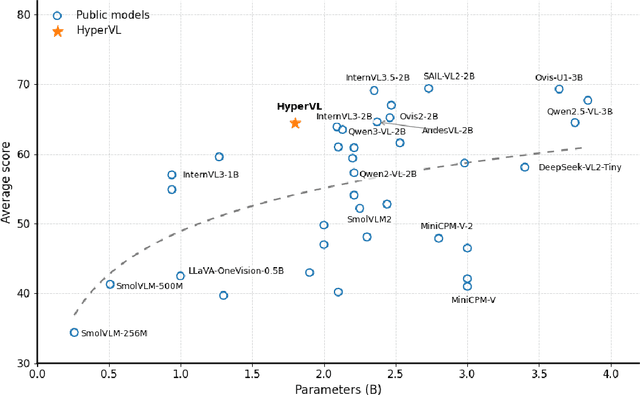

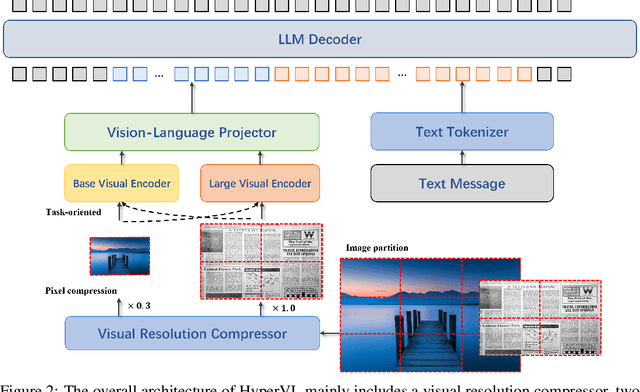

Current multimodal large lanauge models possess strong perceptual and reasoning capabilities, however high computational and memory requirements make them difficult to deploy directly on on-device environments. While small-parameter models are progressively endowed with strong general capabilities, standard Vision Transformer (ViT) encoders remain a critical bottleneck, suffering from excessive latency and memory consumption when processing high-resolution inputs.To address these challenges, we introduce HyperVL, an efficient multimodal large language model tailored for on-device inference. HyperVL adopts an image-tiling strategy to cap peak memory usage and incorporates two novel techniques: (1) a Visual Resolution Compressor (VRC) that adaptively predicts optimal encoding resolutions to eliminate redundant computation, and (2) Dual Consistency Learning (DCL), which aligns multi-scale ViT encoders within a unified framework, enabling dynamic switching between visual branches under a shared LLM. Extensive experiments demonstrate that HyperVL achieves state-of-the-art performance among models of comparable size across multiple benchmarks. Furthermore, it significantly significantly reduces latency and power consumption on real mobile devices, demonstrating its practicality for on-device multimodal inference.
Can large language models understand uncommon meanings of common words?
May 09, 2024Large language models (LLMs) like ChatGPT have shown significant advancements across diverse natural language understanding (NLU) tasks, including intelligent dialogue and autonomous agents. Yet, lacking widely acknowledged testing mechanisms, answering `whether LLMs are stochastic parrots or genuinely comprehend the world' remains unclear, fostering numerous studies and sparking heated debates. Prevailing research mainly focuses on surface-level NLU, neglecting fine-grained explorations. However, such explorations are crucial for understanding their unique comprehension mechanisms, aligning with human cognition, and finally enhancing LLMs' general NLU capacities. To address this gap, our study delves into LLMs' nuanced semantic comprehension capabilities, particularly regarding common words with uncommon meanings. The idea stems from foundational principles of human communication within psychology, which underscore accurate shared understandings of word semantics. Specifically, this paper presents the innovative construction of a Lexical Semantic Comprehension (LeSC) dataset with novel evaluation metrics, the first benchmark encompassing both fine-grained and cross-lingual dimensions. Introducing models of both open-source and closed-source, varied scales and architectures, our extensive empirical experiments demonstrate the inferior performance of existing models in this basic lexical-meaning understanding task. Notably, even the state-of-the-art LLMs GPT-4 and GPT-3.5 lag behind 16-year-old humans by 3.9% and 22.3%, respectively. Additionally, multiple advanced prompting techniques and retrieval-augmented generation are also introduced to help alleviate this trouble, yet limitations persist. By highlighting the above critical shortcomings, this research motivates further investigation and offers novel insights for developing more intelligent LLMs.
KS-LLM: Knowledge Selection of Large Language Models with Evidence Document for Question Answering
Apr 24, 2024
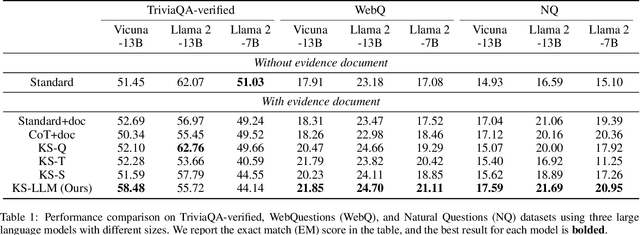
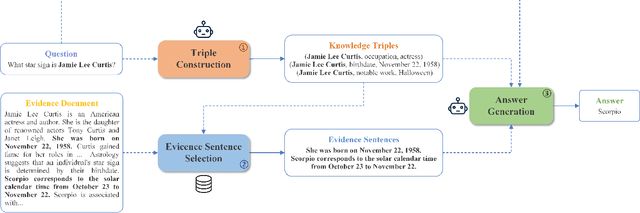
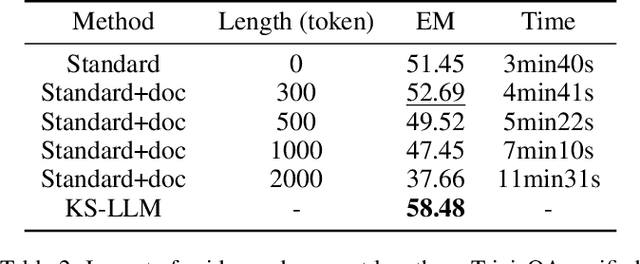
Large language models (LLMs) suffer from the hallucination problem and face significant challenges when applied to knowledge-intensive tasks. A promising approach is to leverage evidence documents as extra supporting knowledge, which can be obtained through retrieval or generation. However, existing methods directly leverage the entire contents of the evidence document, which may introduce noise information and impair the performance of large language models. To tackle this problem, we propose a novel Knowledge Selection of Large Language Models (KS-LLM) method, aiming to identify valuable information from evidence documents. The KS-LLM approach utilizes triples to effectively select knowledge snippets from evidence documents that are beneficial to answering questions. Specifically, we first generate triples based on the input question, then select the evidence sentences most similar to triples from the evidence document, and finally combine the evidence sentences and triples to assist large language models in generating answers. Experimental comparisons on several question answering datasets, such as TriviaQA, WebQ, and NQ, demonstrate that the proposed method surpasses the baselines and achieves the best results.
ADD 2023: the Second Audio Deepfake Detection Challenge
May 23, 2023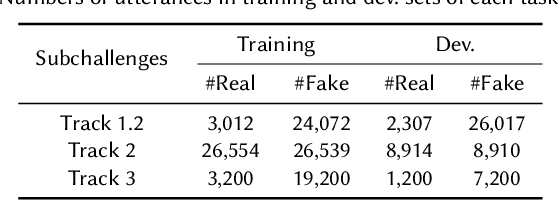
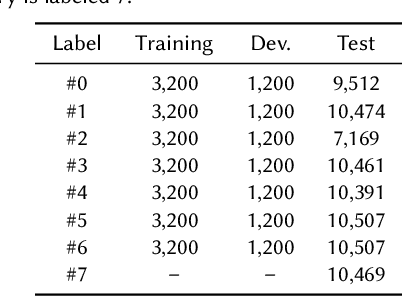
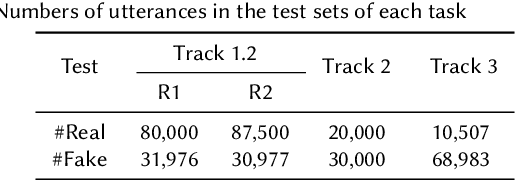

Audio deepfake detection is an emerging topic in the artificial intelligence community. The second Audio Deepfake Detection Challenge (ADD 2023) aims to spur researchers around the world to build new innovative technologies that can further accelerate and foster research on detecting and analyzing deepfake speech utterances. Different from previous challenges (e.g. ADD 2022), ADD 2023 focuses on surpassing the constraints of binary real/fake classification, and actually localizing the manipulated intervals in a partially fake speech as well as pinpointing the source responsible for generating any fake audio. Furthermore, ADD 2023 includes more rounds of evaluation for the fake audio game sub-challenge. The ADD 2023 challenge includes three subchallenges: audio fake game (FG), manipulation region location (RL) and deepfake algorithm recognition (AR). This paper describes the datasets, evaluation metrics, and protocols. Some findings are also reported in audio deepfake detection tasks.
ADD 2022: the First Audio Deep Synthesis Detection Challenge
Feb 26, 2022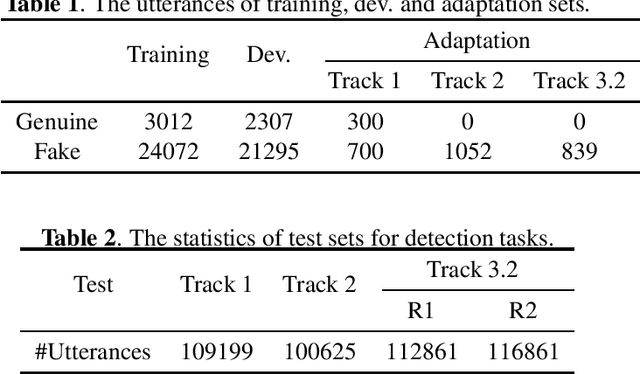
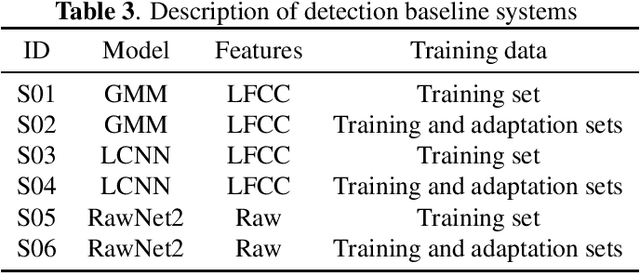
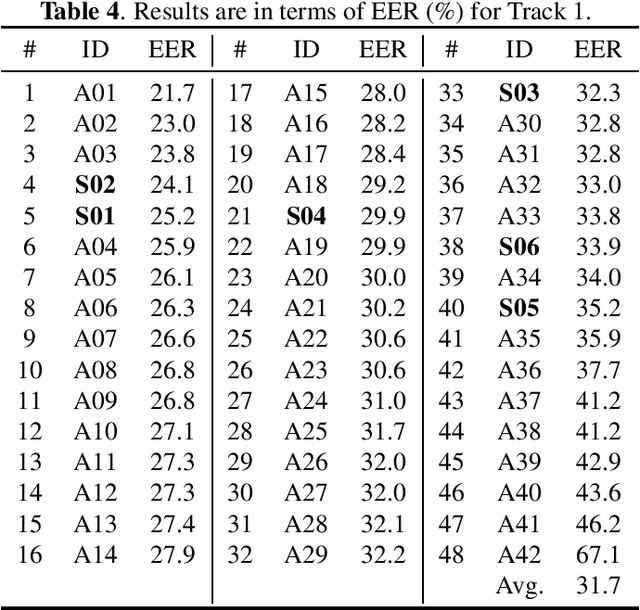
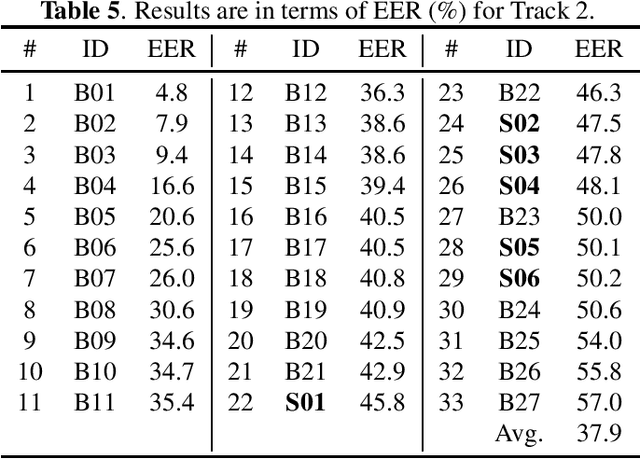
Audio deepfake detection is an emerging topic, which was included in the ASVspoof 2021. However, the recent shared tasks have not covered many real-life and challenging scenarios. The first Audio Deep synthesis Detection challenge (ADD) was motivated to fill in the gap. The ADD 2022 includes three tracks: low-quality fake audio detection (LF), partially fake audio detection (PF) and audio fake game (FG). The LF track focuses on dealing with bona fide and fully fake utterances with various real-world noises etc. The PF track aims to distinguish the partially fake audio from the real. The FG track is a rivalry game, which includes two tasks: an audio generation task and an audio fake detection task. In this paper, we describe the datasets, evaluation metrics, and protocols. We also report major findings that reflect the recent advances in audio deepfake detection tasks.
TeraHertz Band Communication: An Old Problem Revisited and Research Directions for the Next Decade
Dec 25, 2021
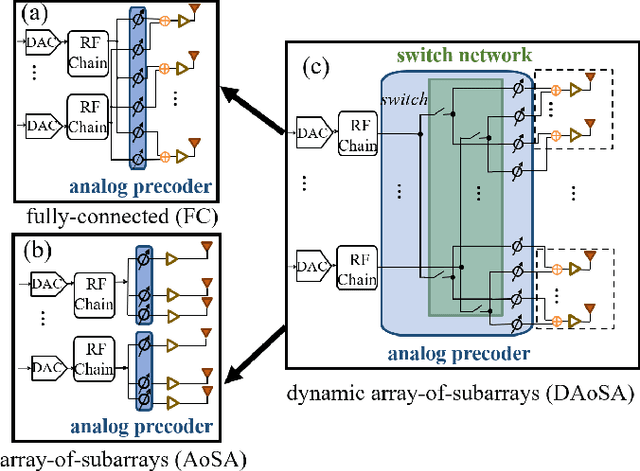
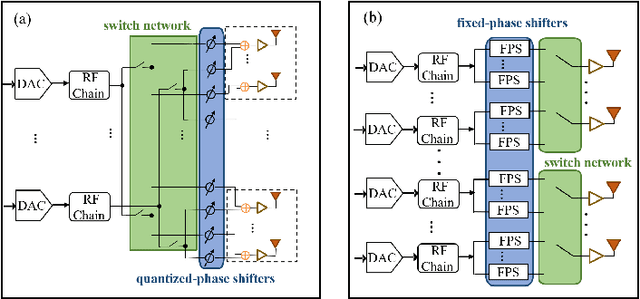
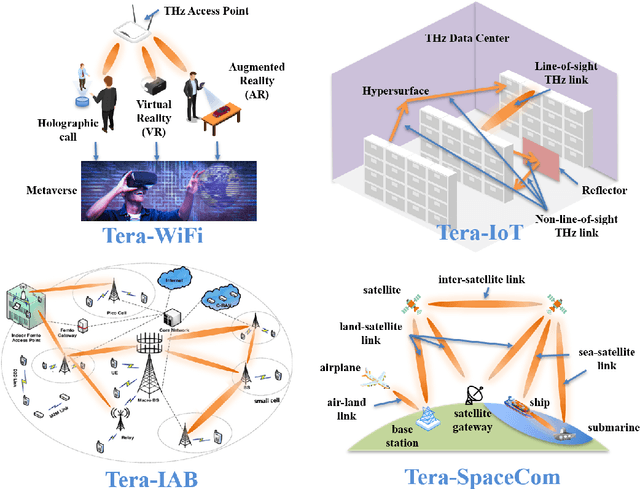
TeraHertz (THz) band communications are envisioned as a key technology for 6G and Beyond. As a fundamental wireless infrastructure, THz communication can boost abundant promising applications. In 2014, our team published two comprehensive roadmaps for the development and progress of THz communication networks [1], [2], which helped the research community to start research on this subject afterwards. In particular, this topic became very important and appealing to the research community due to 6G wireless systems design and development in recent years. Many papers are getting published covering different aspects of wireless systems using the THz band. With this paper, our aim is looking back to the last decade and revisiting the old problems and pointing out what has been achieved in the research community so far. Furthermore, in this paper still to be investigated new research challenges for the THz band communication systems are presented by covering diverse subtopics such as from perspectives of devices, channel behavior, communication and networking problems, physical testbeds and demonstration systems. The key aspects presented in this paper will enable THz communications as a pillar of 6G and Beyond wireless systems in the next decade.
An Interpretable Neural Network for Configuring Programmable Wireless Environments
May 07, 2019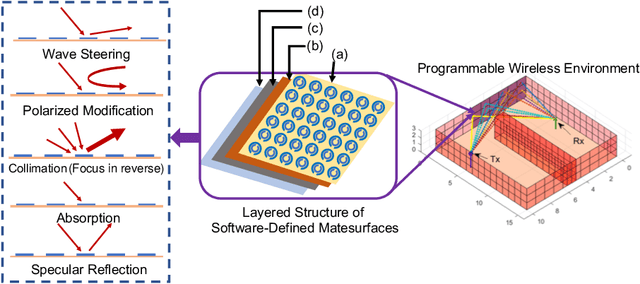
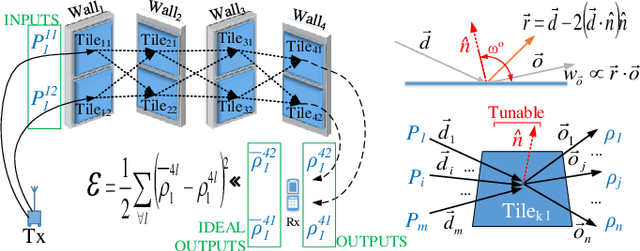
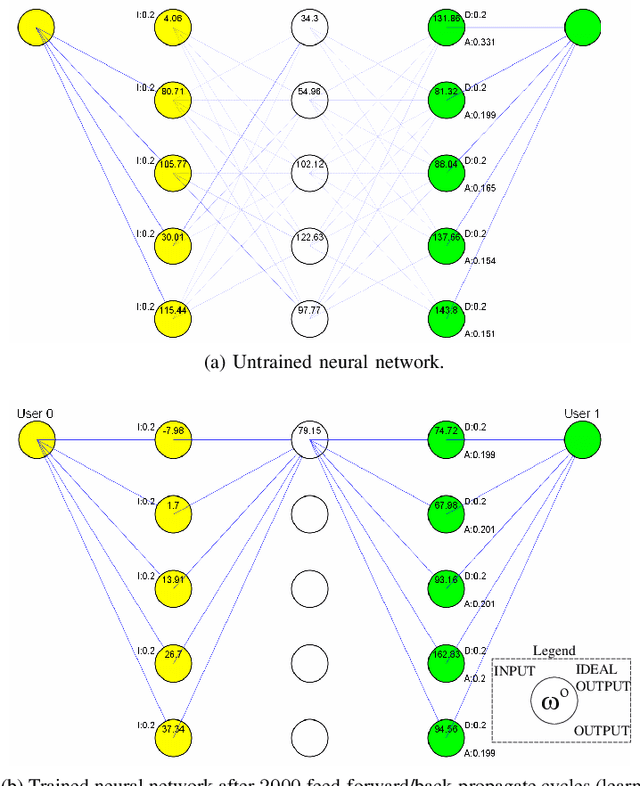
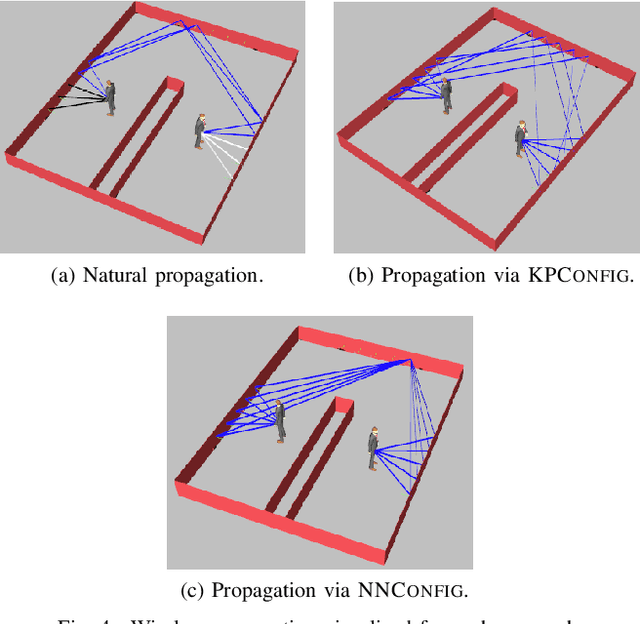
Software-defined metasurfaces (SDMs) comprise a dense topology of basic elements called meta-atoms, exerting the highest degree of control over surface currents among intelligent panel technologies. As such, they can transform impinging electromagnetic (EM) waves in complex ways, modifying their direction, power, frequency spectrum, polarity and phase. A well-defined software interface allows for applying such functionalities to waves and inter-networking SDMs, while abstracting the underlying physics. A network of SDMs deployed over objects within an area, such as a floorplan walls, creates programmable wireless environments (PWEs) with fully customizable propagation of waves within them. This work studies the use of machine learning for configuring such environments to the benefit of users within. The methodology consists of modeling wireless propagation as a custom, interpretable, back-propagating neural network, with SDM elements as nodes and their cross-interactions as links. Following a training period the network learns the propagation basics of SDMs and configures them to facilitate the communication of users within their vicinity.
Deep Segment Attentive Embedding for Duration Robust Speaker Verification
Nov 01, 2018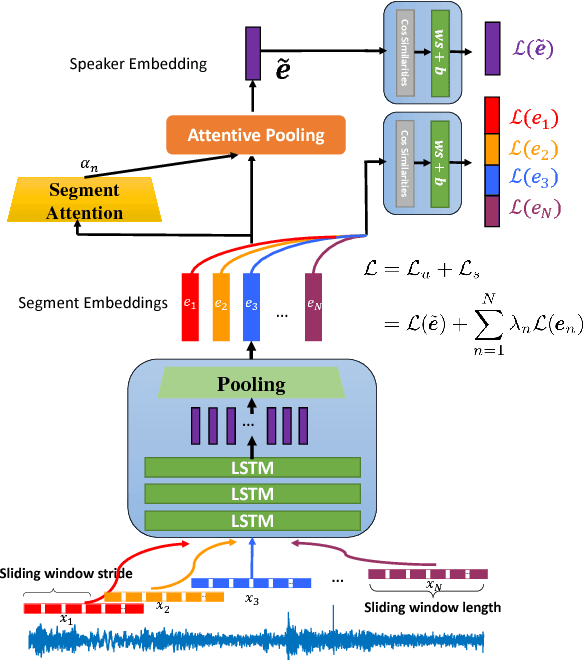

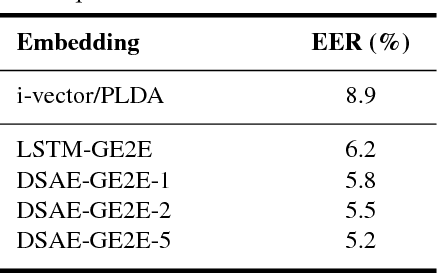
LSTM-based speaker verification usually uses a fixed-length local segment randomly truncated from an utterance to learn the utterance-level speaker embedding, while using the average embedding of all segments of a test utterance to verify the speaker, which results in a critical mismatch between testing and training. This mismatch degrades the performance of speaker verification, especially when the durations of training and testing utterances are very different. To alleviate this issue, we propose the deep segment attentive embedding method to learn the unified speaker embeddings for utterances of variable duration. Each utterance is segmented by a sliding window and LSTM is used to extract the embedding of each segment. Instead of only using one local segment, we use the whole utterance to learn the utterance-level embedding by applying an attentive pooling to the embeddings of all segments. Moreover, the similarity loss of segment-level embeddings is introduced to guide the segment attention to focus on the segments with more speaker discriminations, and jointly optimized with the similarity loss of utterance-level embeddings. Systematic experiments on Tongdun and VoxCeleb show that the proposed method significantly improves robustness of duration variant and achieves the relative Equal Error Rate reduction of 50% and 11.54% , respectively.