 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Noise Robustness of Acoustic Model via Deep Adversarial Training
May 02, 2018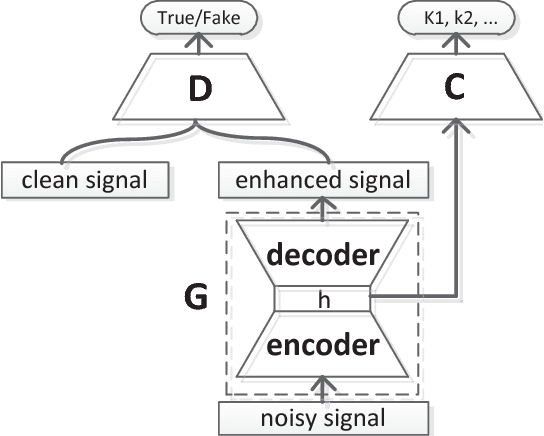


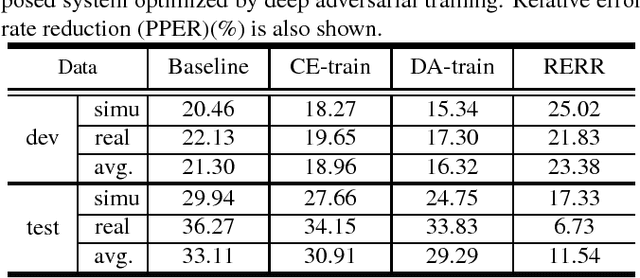
In realistic environments, speech is usually interfered by various noise and reverberation, which dramatically degrades the performance of automatic speech recognition (ASR) systems. To alleviate this issue, the commonest way is to use a well-designed speech enhancement approach as the front-end of ASR. However, more complex pipelines, more computations and even higher hardware costs (microphone array) are additionally consumed for this kind of methods. In addition, speech enhancement would result in speech distortions and mismatches to training. In this paper, we propose an adversarial training method to directly boost noise robustness of acoustic model. Specifically, a jointly compositional scheme of generative adversarial net (GAN) and neural network-based acoustic model (AM) is used in the training phase. GAN is used to generate clean feature representations from noisy features by the guidance of a discriminator that tries to distinguish between the true clean signals and generated signals. The joint optimization of generator, discriminator and AM concentrates the strengths of both GAN and AM for speech recognition. Systematic experiments on CHiME-4 show that the proposed method significantly improves the noise robustness of AM and achieves the average relative error rate reduction of 23.38% and 11.54% on the development and test set, respectively.