 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan large language models understand uncommon meanings of common words?
May 09, 2024Large language models (LLMs) like ChatGPT have shown significant advancements across diverse natural language understanding (NLU) tasks, including intelligent dialogue and autonomous agents. Yet, lacking widely acknowledged testing mechanisms, answering `whether LLMs are stochastic parrots or genuinely comprehend the world' remains unclear, fostering numerous studies and sparking heated debates. Prevailing research mainly focuses on surface-level NLU, neglecting fine-grained explorations. However, such explorations are crucial for understanding their unique comprehension mechanisms, aligning with human cognition, and finally enhancing LLMs' general NLU capacities. To address this gap, our study delves into LLMs' nuanced semantic comprehension capabilities, particularly regarding common words with uncommon meanings. The idea stems from foundational principles of human communication within psychology, which underscore accurate shared understandings of word semantics. Specifically, this paper presents the innovative construction of a Lexical Semantic Comprehension (LeSC) dataset with novel evaluation metrics, the first benchmark encompassing both fine-grained and cross-lingual dimensions. Introducing models of both open-source and closed-source, varied scales and architectures, our extensive empirical experiments demonstrate the inferior performance of existing models in this basic lexical-meaning understanding task. Notably, even the state-of-the-art LLMs GPT-4 and GPT-3.5 lag behind 16-year-old humans by 3.9% and 22.3%, respectively. Additionally, multiple advanced prompting techniques and retrieval-augmented generation are also introduced to help alleviate this trouble, yet limitations persist. By highlighting the above critical shortcomings, this research motivates further investigation and offers novel insights for developing more intelligent LLMs.
KS-LLM: Knowledge Selection of Large Language Models with Evidence Document for Question Answering
Apr 24, 2024
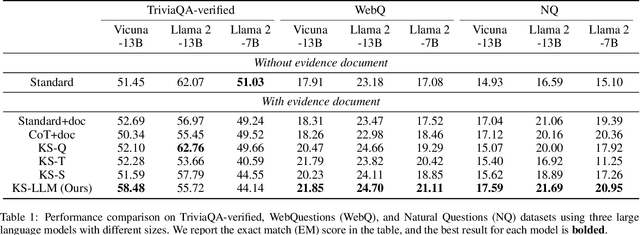
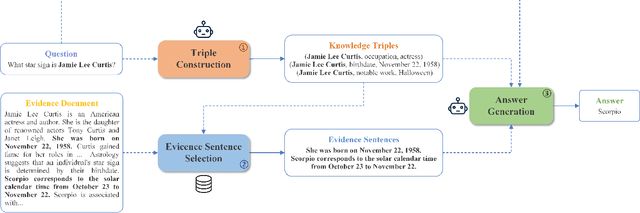
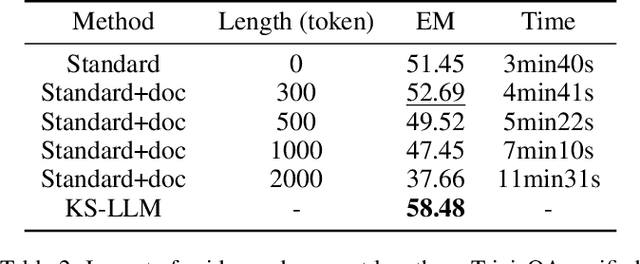
Large language models (LLMs) suffer from the hallucination problem and face significant challenges when applied to knowledge-intensive tasks. A promising approach is to leverage evidence documents as extra supporting knowledge, which can be obtained through retrieval or generation. However, existing methods directly leverage the entire contents of the evidence document, which may introduce noise information and impair the performance of large language models. To tackle this problem, we propose a novel Knowledge Selection of Large Language Models (KS-LLM) method, aiming to identify valuable information from evidence documents. The KS-LLM approach utilizes triples to effectively select knowledge snippets from evidence documents that are beneficial to answering questions. Specifically, we first generate triples based on the input question, then select the evidence sentences most similar to triples from the evidence document, and finally combine the evidence sentences and triples to assist large language models in generating answers. Experimental comparisons on several question answering datasets, such as TriviaQA, WebQ, and NQ, demonstrate that the proposed method surpasses the baselines and achieves the best results.