 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPR: Penalizing Structural Redundancy in Large Reasoning Models via Anchor-based Process Rewards
Jan 31, 2026Test-Time Scaling (TTS) has significantly enhanced the capabilities of Large Reasoning Models (LRMs) but introduces a critical side-effect known as Overthinking. We conduct a preliminary study to rethink this phenomenon from a fine-grained perspective. We observe that LRMs frequently conduct repetitive self-verification without revision even after obtaining the final answer during the reasoning process. We formally define this specific position where the answer first stabilizes as the Reasoning Anchor. By analyzing pre- and post-anchor reasoning behaviors, we uncover the structural redundancy fixed in LRMs: the meaningless repetitive verification after deriving the first complete answer, which we term the Answer-Stable Tail (AST). Motivated by this observation, we propose Anchor-based Process Reward (APR), a structure-aware reward shaping method that localizes the reasoning anchor and penalizes exclusively the post-anchor AST. Leveraging the policy optimization algorithm suitable for length penalties, our APR models achieved the performance-efficiency Pareto frontier at 1.5B and 7B scales averaged across five mathematical reasoning datasets while requiring significantly fewer computational resources for RL training.
RM-Distiller: Exploiting Generative LLM for Reward Model Distillation
Jan 20, 2026Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human preferences. Due to the difficulty of obtaining high-quality human preference annotations, distilling preferences from generative LLMs has emerged as a standard practice. However, existing approaches predominantly treat teacher models as simple binary annotators, failing to fully exploit the rich knowledge and capabilities for RM distillation. To address this, we propose RM-Distiller, a framework designed to systematically exploit the multifaceted capabilities of teacher LLMs: (1) Refinement capability, which synthesizes highly correlated response pairs to create fine-grained and contrastive signals. (2) Scoring capability, which guides the RM in capturing precise preference strength via a margin-aware optimization objective. (3) Generation capability, which incorporates the teacher's generative distribution to regularize the RM to preserve its fundamental linguistic knowledge. Extensive experiments demonstrate that RM-Distiller significantly outperforms traditional distillation methods both on RM benchmarks and reinforcement learning-based alignment, proving that exploiting multifaceted teacher capabilities is critical for effective reward modeling. To the best of our knowledge, this is the first systematic research on RM distillation from generative LLMs.
SERM: Self-Evolving Relevance Model with Agent-Driven Learning from Massive Query Streams
Jan 14, 2026Due to the dynamically evolving nature of real-world query streams, relevance models struggle to generalize to practical search scenarios. A sophisticated solution is self-evolution techniques. However, in large-scale industrial settings with massive query streams, this technique faces two challenges: (1) informative samples are often sparse and difficult to identify, and (2) pseudo-labels generated by the current model could be unreliable. To address these challenges, in this work, we propose a Self-Evolving Relevance Model approach (SERM), which comprises two complementary multi-agent modules: a multi-agent sample miner, designed to detect distributional shifts and identify informative training samples, and a multi-agent relevance annotator, which provides reliable labels through a two-level agreement framework. We evaluate SERM in a large-scale industrial setting, which serves billions of user requests daily. Experimental results demonstrate that SERM can achieve significant performance gains through iterative self-evolution, as validated by extensive offline multilingual evaluations and online testing.
Probing Preference Representations: A Multi-Dimensional Evaluation and Analysis Method for Reward Models
Nov 16, 2025Previous methods evaluate reward models by testing them on a fixed pairwise ranking test set, but they typically do not provide performance information on each preference dimension. In this work, we address the evaluation challenge of reward models by probing preference representations. To confirm the effectiveness of this evaluation method, we construct a Multi-dimensional Reward Model Benchmark (MRMBench), a collection of six probing tasks for different preference dimensions. We design it to favor and encourage reward models that better capture preferences across different dimensions. Furthermore, we introduce an analysis method, inference-time probing, which identifies the dimensions used during the reward prediction and enhances its interpretability. Through extensive experiments, we find that MRMBench strongly correlates with the alignment performance of large language models (LLMs), making it a reliable reference for developing advanced reward models. Our analysis of MRMBench evaluation results reveals that reward models often struggle to capture preferences across multiple dimensions, highlighting the potential of multi-objective optimization in reward modeling. Additionally, our findings show that the proposed inference-time probing method offers a reliable metric for assessing the confidence of reward predictions, which ultimately improves the alignment of LLMs.
MRO: Enhancing Reasoning in Diffusion Language Models via Multi-Reward Optimization
Oct 24, 2025


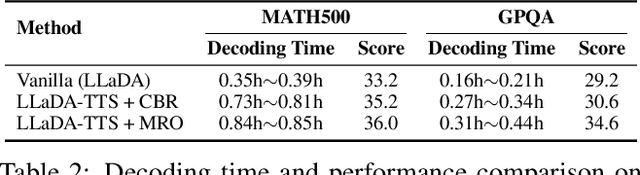
Recent advances in diffusion language models (DLMs) have presented a promising alternative to traditional autoregressive large language models (LLMs). However, DLMs still lag behind LLMs in reasoning performance, especially as the number of denoising steps decreases. Our analysis reveals that this shortcoming arises primarily from the independent generation of masked tokens across denoising steps, which fails to capture the token correlation. In this paper, we define two types of token correlation: intra-sequence correlation and inter-sequence correlation, and demonstrate that enhancing these correlations improves reasoning performance. To this end, we propose a Multi-Reward Optimization (MRO) approach, which encourages DLMs to consider the token correlation during the denoising process. More specifically, our MRO approach leverages test-time scaling, reject sampling, and reinforcement learning to directly optimize the token correlation with multiple elaborate rewards. Additionally, we introduce group step and importance sampling strategies to mitigate reward variance and enhance sampling efficiency. Through extensive experiments, we demonstrate that MRO not only improves reasoning performance but also achieves significant sampling speedups while maintaining high performance on reasoning benchmarks.
SageLM: A Multi-aspect and Explainable Large Language Model for Speech Judgement
Aug 28, 2025Speech-to-Speech (S2S) Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling end-to-end spoken dialogue systems. However, evaluating these models remains a fundamental challenge. We propose \texttt{SageLM}, an end-to-end, multi-aspect, and explainable speech LLM for comprehensive S2S LLMs evaluation. First, unlike cascaded approaches that disregard acoustic features, SageLM jointly assesses both semantic and acoustic dimensions. Second, it leverages rationale-based supervision to enhance explainability and guide model learning, achieving superior alignment with evaluation outcomes compared to rule-based reinforcement learning methods. Third, we introduce \textit{SpeechFeedback}, a synthetic preference dataset, and employ a two-stage training paradigm to mitigate the scarcity of speech preference data. Trained on both semantic and acoustic dimensions, SageLM achieves an 82.79\% agreement rate with human evaluators, outperforming cascaded and SLM-based baselines by at least 7.42\% and 26.20\%, respectively.
HEAL: A Hypothesis-Based Preference-Aware Analysis Framework
Aug 27, 2025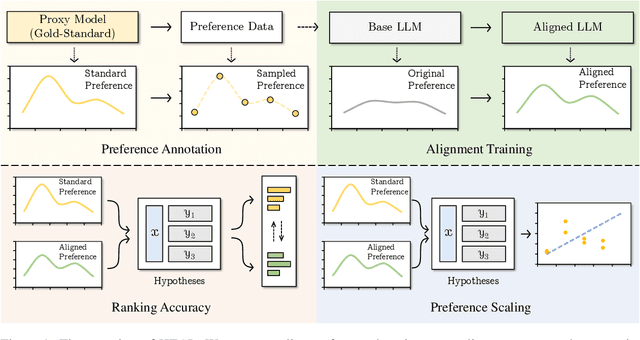
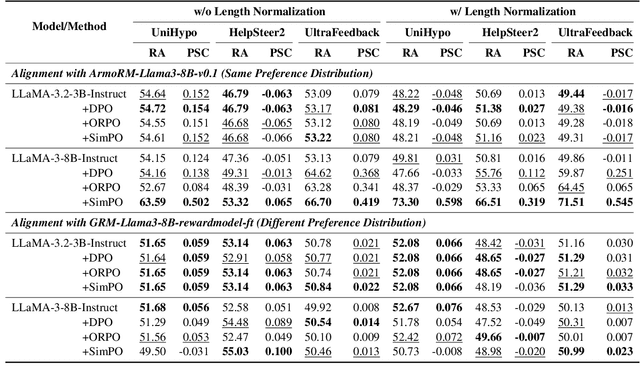
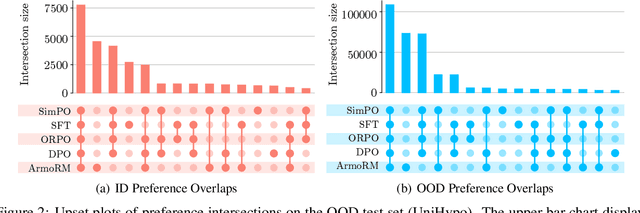
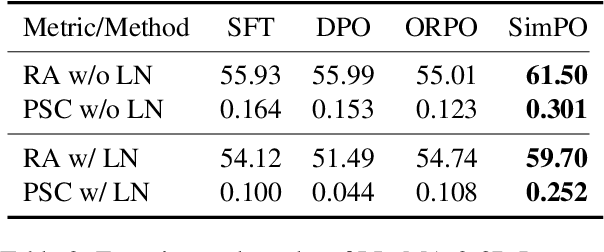
Preference optimization methods like DPO have achieved remarkable performance in LLM alignment. However, the evaluation for these methods relies on a single response and overlooks other potential outputs, which could also be generated in real-world applications within this hypothetical space. To address this issue, this paper presents a \textbf{H}ypothesis-based Pr\textbf{E}ference-aware \textbf{A}na\textbf{L}ysis Framework (HEAL), a novel evaluation paradigm that formulates preference alignment as a re-ranking process within hypothesis spaces. The framework incorporates two complementary metrics: ranking accuracy for evaluating ordinal consistency and preference strength correlation for assessing continuous alignment. To facilitate this framework, we develop UniHypoBench, a unified hypothesis benchmark constructed from diverse instruction-response pairs. Through extensive experiments based on HEAL, with a particular focus on the intrinsic mechanisms of preference learning, we demonstrate that current preference learning methods can effectively capture preferences provided by proxy models while simultaneously suppressing negative samples. These findings contribute to preference learning research through two significant avenues. Theoretically, we introduce hypothesis space analysis as an innovative paradigm for understanding preference alignment. Practically, HEAL offers researchers robust diagnostic tools for refining preference optimization methods, while our empirical results identify promising directions for developing more advanced alignment algorithms capable of comprehensive preference capture.
LaTeXTrans: Structured LaTeX Translation with Multi-Agent Coordination
Aug 26, 2025Despite the remarkable progress of modern machine translation (MT) systems on general-domain texts, translating structured LaTeX-formatted documents remains a significant challenge. These documents typically interleave natural language with domain-specific syntax, such as mathematical equations, tables, figures, and cross-references, all of which must be accurately preserved to maintain semantic integrity and compilability. In this paper, we introduce LaTeXTrans, a collaborative multi-agent system designed to address this challenge. LaTeXTrans ensures format preservation, structural fidelity, and terminology consistency through six specialized agents: 1) a Parser that decomposes LaTeX into translation-friendly units via placeholder substitution and syntax filtering; 2) a Translator, Validator, Summarizer, and Terminology Extractor that work collaboratively to ensure context-aware, self-correcting, and terminology-consistent translations; 3) a Generator that reconstructs the translated content into well-structured LaTeX documents. Experimental results demonstrate that LaTeXTrans can outperform mainstream MT systems in both translation accuracy and structural fidelity, offering an effective and practical solution for translating LaTeX-formatted documents.
A Physics-Driven Neural Network with Parameter Embedding for Generating Quantitative MR Maps from Weighted Images
Aug 11, 2025We propose a deep learning-based approach that integrates MRI sequence parameters to improve the accuracy and generalizability of quantitative image synthesis from clinical weighted MRI. Our physics-driven neural network embeds MRI sequence parameters -- repetition time (TR), echo time (TE), and inversion time (TI) -- directly into the model via parameter embedding, enabling the network to learn the underlying physical principles of MRI signal formation. The model takes conventional T1-weighted, T2-weighted, and T2-FLAIR images as input and synthesizes T1, T2, and proton density (PD) quantitative maps. Trained on healthy brain MR images, it was evaluated on both internal and external test datasets. The proposed method achieved high performance with PSNR values exceeding 34 dB and SSIM values above 0.92 for all synthesized parameter maps. It outperformed conventional deep learning models in accuracy and robustness, including data with previously unseen brain structures and lesions. Notably, our model accurately synthesized quantitative maps for these unseen pathological regions, highlighting its superior generalization capability. Incorporating MRI sequence parameters via parameter embedding allows the neural network to better learn the physical characteristics of MR signals, significantly enhancing the performance and reliability of quantitative MRI synthesis. This method shows great potential for accelerating qMRI and improving its clinical utility.
GRAM: A Generative Foundation Reward Model for Reward Generalization
Jun 18, 2025In aligning large language models (LLMs), reward models have played an important role, but are standardly trained as discriminative models and rely only on labeled human preference data. In this paper, we explore methods that train reward models using both unlabeled and labeled data. Building on the generative models in LLMs, we develop a generative reward model that is first trained via large-scale unsupervised learning and then fine-tuned via supervised learning. We also show that by using label smoothing, we are in fact optimizing a regularized pairwise ranking loss. This result, in turn, provides a new view of training reward models, which links generative models and discriminative models under the same class of training objectives. The outcome of these techniques is a foundation reward model, which can be applied to a wide range of tasks with little or no further fine-tuning effort. Extensive experiments show that this model generalizes well across several tasks, including response ranking, reinforcement learning from human feedback, and task adaptation with fine-tuning, achieving significant performance improvements over several strong baseline models.