 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Vision: Evaluating Multimodal LLMs Logic Understanding and Code Generation Capabilities
Feb 17, 2025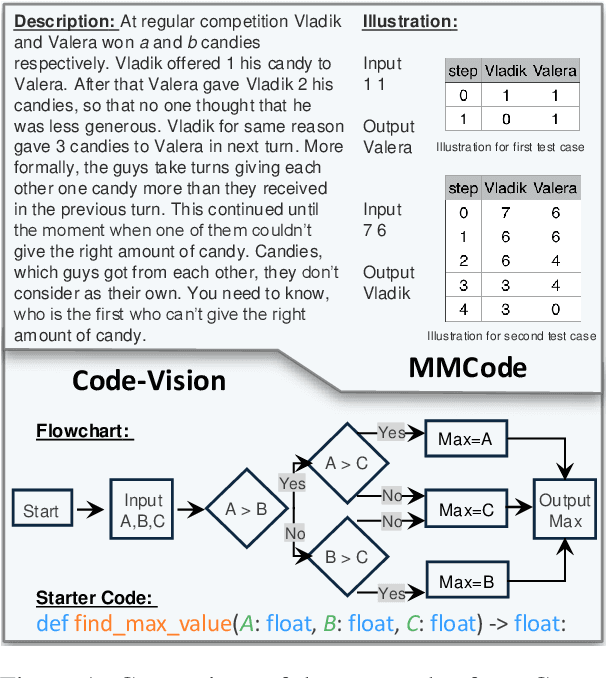

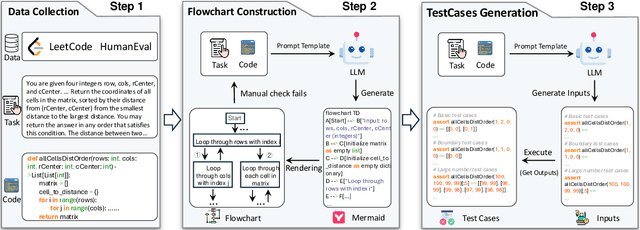
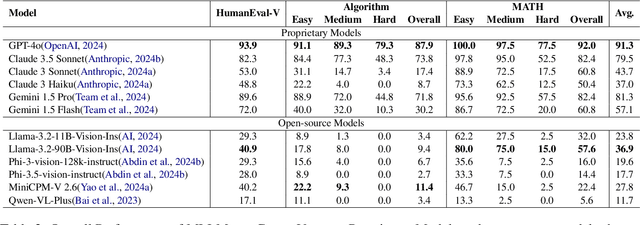
This paper introduces Code-Vision, a benchmark designed to evaluate the logical understanding and code generation capabilities of Multimodal Large Language Models (MLLMs). It challenges MLLMs to generate a correct program that fulfills specific functionality requirements based on a given flowchart, which visually represents the desired algorithm or process. Code-Vision comprises three subsets: HumanEval-V, Algorithm, and MATH, which evaluate MLLMs' coding abilities across basic programming, algorithmic, and mathematical problem-solving domains. Our experiments evaluate 12 MLLMs on Code-Vision. Experimental results demonstrate that there is a large performance difference between proprietary and open-source models. On Hard problems, GPT-4o can achieve 79.3% pass@1, but the best open-source model only achieves 15%. Further experiments reveal that Code-Vision can pose unique challenges compared to other multimodal reasoning benchmarks MMCode and MathVista. We also explore the reason for the poor performance of the open-source models. All data and codes are available at https://github.com/wanghanbinpanda/CodeVision.
Boosting Text-To-Image Generation via Multilingual Prompting in Large Multimodal Models
Jan 13, 2025Previous work on augmenting large multimodal models (LMMs) for text-to-image (T2I) generation has focused on enriching the input space of in-context learning (ICL). This includes providing a few demonstrations and optimizing image descriptions to be more detailed and logical. However, as demand for more complex and flexible image descriptions grows, enhancing comprehension of input text within the ICL paradigm remains a critical yet underexplored area. In this work, we extend this line of research by constructing parallel multilingual prompts aimed at harnessing the multilingual capabilities of LMMs. More specifically, we translate the input text into several languages and provide the models with both the original text and the translations. Experiments on two LMMs across 3 benchmarks show that our method, PMT2I, achieves superior performance in general, compositional, and fine-grained assessments, especially in human preference alignment. Additionally, with its advantage of generating more diverse images, PMT2I significantly outperforms baseline prompts when incorporated with reranking methods. Our code and parallel multilingual data can be found at https://github.com/takagi97/PMT2I.