 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: Unleashing the Power of Speculative Decoding via Margin-Aware Verification
Jan 21, 2026Speculative Decoding (SD) accelerates autoregressive large language model (LLM) inference by decoupling generation and verification. While recent methods improve draft quality by tightly coupling the drafter with the target model, the verification mechanism itself remains largely unchanged, relying on strict token-level rejection sampling. In practice, modern LLMs frequently operate in low-margin regimes where the target model exhibits weak preference among top candidates. In such cases, rejecting plausible runner-up tokens yields negligible information gain while incurring substantial rollback cost, leading to a fundamental inefficiency in verification. We propose Margin-Aware Speculative Verification, a training-free and domain-agnostic verification strategy that adapts to the target model's local decisiveness. Our method conditions verification on decision stability measured directly from the target logits and relaxes rejection only when strict verification provides minimal benefit. Importantly, the approach modifies only the verification rule and is fully compatible with existing target-coupled speculative decoding frameworks. Extensive experiments across model scales ranging from 8B to 235B demonstrate that our method delivers consistent and significant inference speedups over state-of-the-art baselines while preserving generation quality across diverse benchmarks.
Teaching Large Reasoning Models Effective Reflection
Jan 19, 2026Large Reasoning Models (LRMs) have recently shown impressive performance on complex reasoning tasks, often by engaging in self-reflective behaviors such as self-critique and backtracking. However, not all reflections are beneficial-many are superficial, offering little to no improvement over the original answer and incurring computation overhead. In this paper, we identify and address the problem of superficial reflection in LRMs. We first propose Self-Critique Fine-Tuning (SCFT), a training framework that enhances the model's reflective reasoning ability using only self-generated critiques. SCFT prompts models to critique their own outputs, filters high-quality critiques through rejection sampling, and fine-tunes the model using a critique-based objective. Building on this strong foundation, we further introduce Reinforcement Learning with Effective Reflection Rewards (RLERR). RLERR leverages the high-quality reflections initialized by SCFT to construct reward signals, guiding the model to internalize the self-correction process via reinforcement learning. Experiments on two challenging benchmarks, AIME2024 and AIME2025, show that SCFT and RLERR significantly improve both reasoning accuracy and reflection quality, outperforming state-of-the-art baselines. All data and codes are available at https://github.com/wanghanbinpanda/SCFT.
Group Pattern Selection Optimization: Let LRMs Pick the Right Pattern for Reasoning
Jan 12, 2026Large reasoning models (LRMs) exhibit diverse high-level reasoning patterns (e.g., direct solution, reflection-and-verification, and exploring multiple solutions), yet prevailing training recipes implicitly bias models toward a limited set of dominant patterns. Through a systematic analysis, we identify substantial accuracy variance across these patterns on mathematics and science benchmarks, revealing that a model's default reasoning pattern is often sub-optimal for a given problem. To address this, we introduce Group Pattern Selection Optimization (GPSO), a reinforcement learning framework that extends GRPO by incorporating multi-pattern rollouts, verifier-guided optimal pattern selection per problem, and attention masking during optimization to prevent the leakage of explicit pattern suffixes into the learned policy. By exploring a portfolio of diverse reasoning strategies and optimizing the policy on the most effective ones, GPSO enables the model to internalize the mapping from problem characteristics to optimal reasoning patterns. Extensive experiments demonstrate that GPSO delivers consistent and substantial performance gains across various model backbones and benchmarks, effectively mitigating pattern sub-optimality and fostering more robust, adaptable reasoning. All data and codes are available at https://github.com/wanghanbinpanda/GPSO.
Speculative Decoding in Decentralized LLM Inference: Turning Communication Latency into Computation Throughput
Nov 13, 2025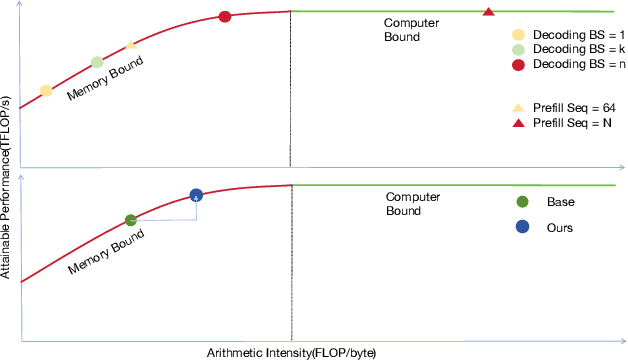
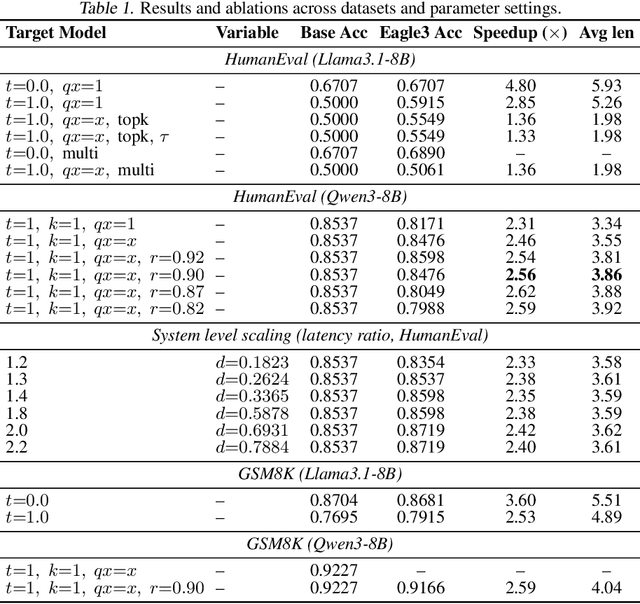

Speculative decoding accelerates large language model (LLM) inference by using a lightweight draft model to propose tokens that are later verified by a stronger target model. While effective in centralized systems, its behavior in decentralized settings, where network latency often dominates compute, remains under-characterized. We present Decentralized Speculative Decoding (DSD), a plug-and-play framework for decentralized inference that turns communication delay into useful computation by verifying multiple candidate tokens in parallel across distributed nodes. We further introduce an adaptive speculative verification strategy that adjusts acceptance thresholds by token-level semantic importance, delivering an additional 15% to 20% end-to-end speedup without retraining. In theory, DSD reduces cross-node communication cost by approximately (N-1)t1(k-1)/k, where t1 is per-link latency and k is the average number of tokens accepted per round. In practice, DSD achieves up to 2.56x speedup on HumanEval and 2.59x on GSM8K, surpassing the Eagle3 baseline while preserving accuracy. These results show that adapting speculative decoding for decentralized execution provides a system-level optimization that converts network stalls into throughput, enabling faster distributed LLM inference with no model retraining or architectural changes.
Code-Vision: Evaluating Multimodal LLMs Logic Understanding and Code Generation Capabilities
Feb 17, 2025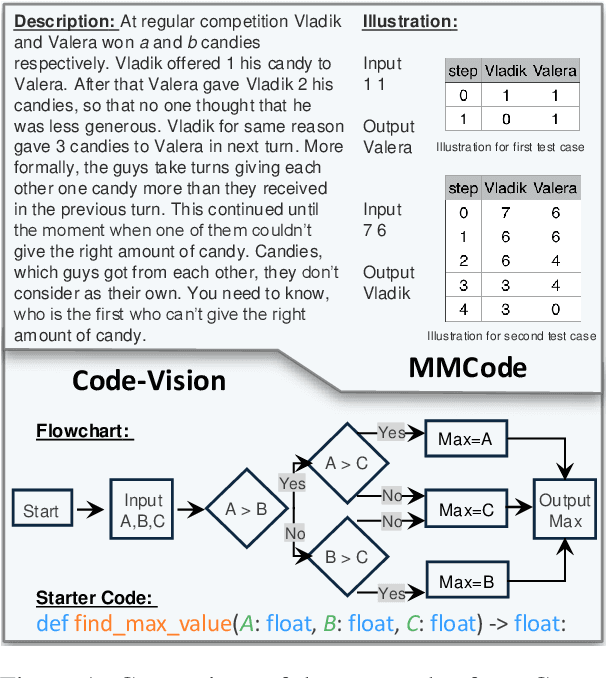

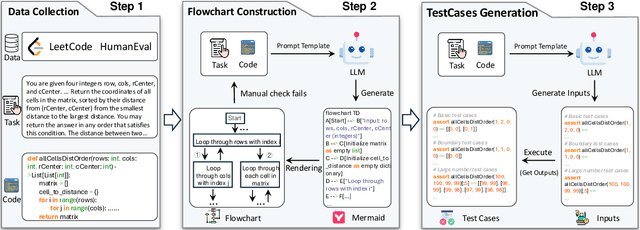
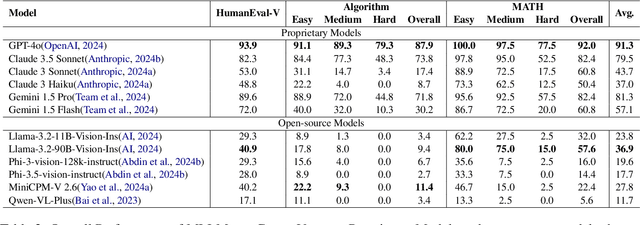
This paper introduces Code-Vision, a benchmark designed to evaluate the logical understanding and code generation capabilities of Multimodal Large Language Models (MLLMs). It challenges MLLMs to generate a correct program that fulfills specific functionality requirements based on a given flowchart, which visually represents the desired algorithm or process. Code-Vision comprises three subsets: HumanEval-V, Algorithm, and MATH, which evaluate MLLMs' coding abilities across basic programming, algorithmic, and mathematical problem-solving domains. Our experiments evaluate 12 MLLMs on Code-Vision. Experimental results demonstrate that there is a large performance difference between proprietary and open-source models. On Hard problems, GPT-4o can achieve 79.3% pass@1, but the best open-source model only achieves 15%. Further experiments reveal that Code-Vision can pose unique challenges compared to other multimodal reasoning benchmarks MMCode and MathVista. We also explore the reason for the poor performance of the open-source models. All data and codes are available at https://github.com/wanghanbinpanda/CodeVision.
DynaWeightPnP: Toward global real-time 3D-2D solver in PnP without correspondences
Sep 27, 2024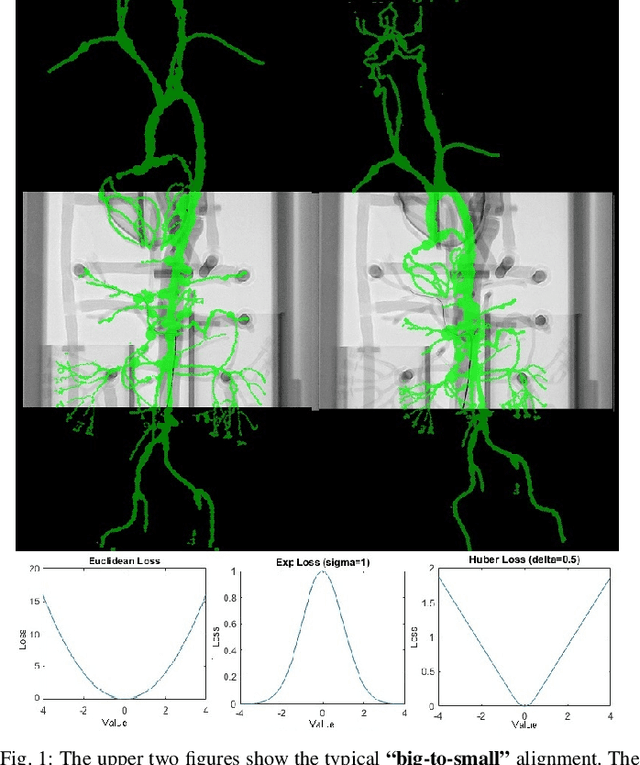
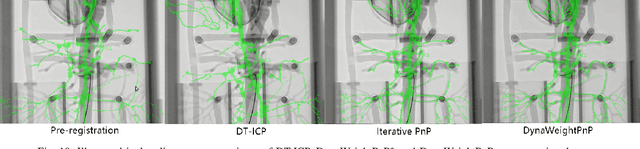

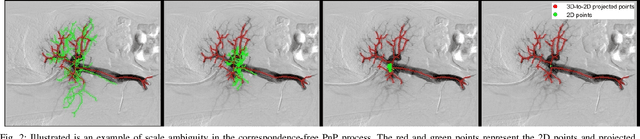
This paper addresses a special Perspective-n-Point (PnP) problem: estimating the optimal pose to align 3D and 2D shapes in real-time without correspondences, termed as correspondence-free PnP. While several studies have focused on 3D and 2D shape registration, achieving both real-time and accurate performance remains challenging. This study specifically targets the 3D-2D geometric shape registration tasks, applying the recently developed Reproducing Kernel Hilbert Space (RKHS) to address the "big-to-small" issue. An iterative reweighted least squares method is employed to solve the RKHS-based formulation efficiently. Moreover, our work identifies a unique and interesting observability issue in correspondence-free PnP: the numerical ambiguity between rotation and translation. To address this, we proposed DynaWeightPnP, introducing a dynamic weighting sub-problem and an alternative searching algorithm designed to enhance pose estimation and alignment accuracy. Experiments were conducted on a typical case, that is, a 3D-2D vascular centerline registration task within Endovascular Image-Guided Interventions (EIGIs). Results demonstrated that the proposed algorithm achieves registration processing rates of 60 Hz (without post-refinement) and 31 Hz (with post-refinement) on modern single-core CPUs, with competitive accuracy comparable to existing methods. These results underscore the suitability of DynaWeightPnP for future robot navigation tasks like EIGIs.
SLAM assisted 3D tracking system for laparoscopic surgery
Sep 18, 2024



A major limitation of minimally invasive surgery is the difficulty in accurately locating the internal anatomical structures of the target organ due to the lack of tactile feedback and transparency. Augmented reality (AR) offers a promising solution to overcome this challenge. Numerous studies have shown that combining learning-based and geometric methods can achieve accurate preoperative and intraoperative data registration. This work proposes a real-time monocular 3D tracking algorithm for post-registration tasks. The ORB-SLAM2 framework is adopted and modified for prior-based 3D tracking. The primitive 3D shape is used for fast initialization of the monocular SLAM. A pseudo-segmentation strategy is employed to separate the target organ from the background for tracking purposes, and the geometric prior of the 3D shape is incorporated as an additional constraint in the pose graph. Experiments from in-vivo and ex-vivo tests demonstrate that the proposed 3D tracking system provides robust 3D tracking and effectively handles typical challenges such as fast motion, out-of-field-of-view scenarios, partial visibility, and "organ-background" relative motion.
RKHS-BA: A Semantic Correspondence-Free Multi-View Registration Framework with Global Tracking
Mar 02, 2024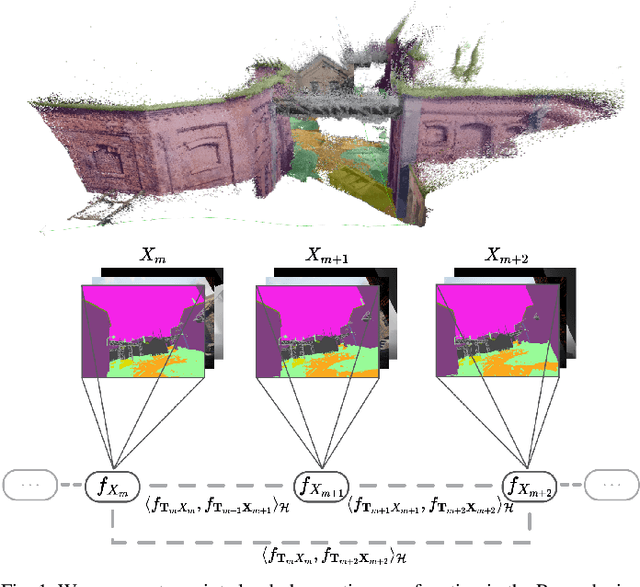
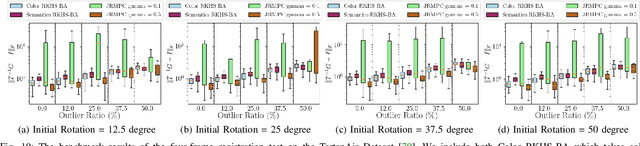
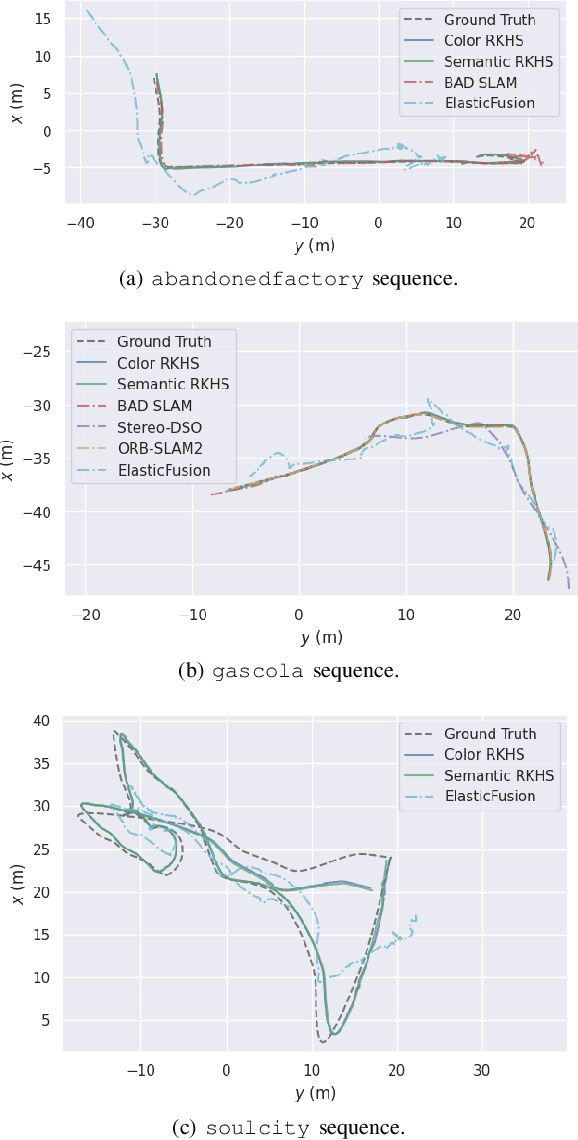

This work reports a novel Bundle Adjustment (BA) formulation using a Reproducing Kernel Hilbert Space (RKHS) representation called RKHS-BA. The proposed formulation is correspondence-free, enables the BA to use RGB-D/LiDAR and semantic labels in the optimization directly, and provides a generalization for the photometric loss function commonly used in direct methods. RKHS-BA can incorporate appearance and semantic labels within a continuous spatial-semantic functional representation that does not require optimization via image pyramids. We demonstrate its applications in sliding-window odometry and global LiDAR mapping, which show highly robust performance in extremely challenging scenes and the best trade-off of generalization and accuracy.
BDIS-SLAM: A lightweight CPU-based dense stereo SLAM for surgery
Dec 25, 2023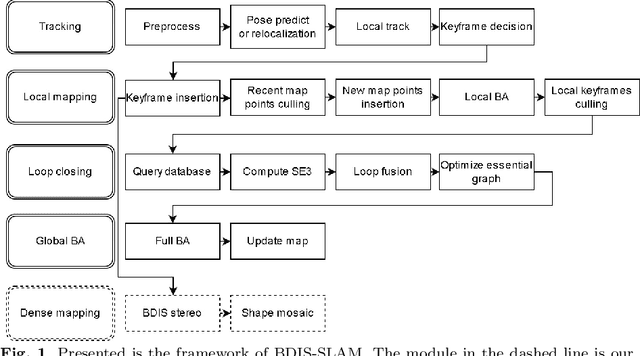
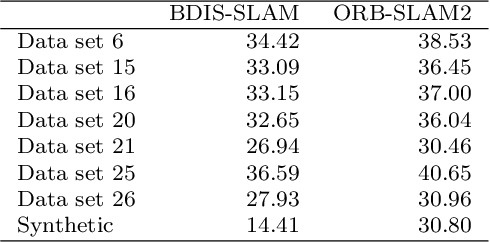
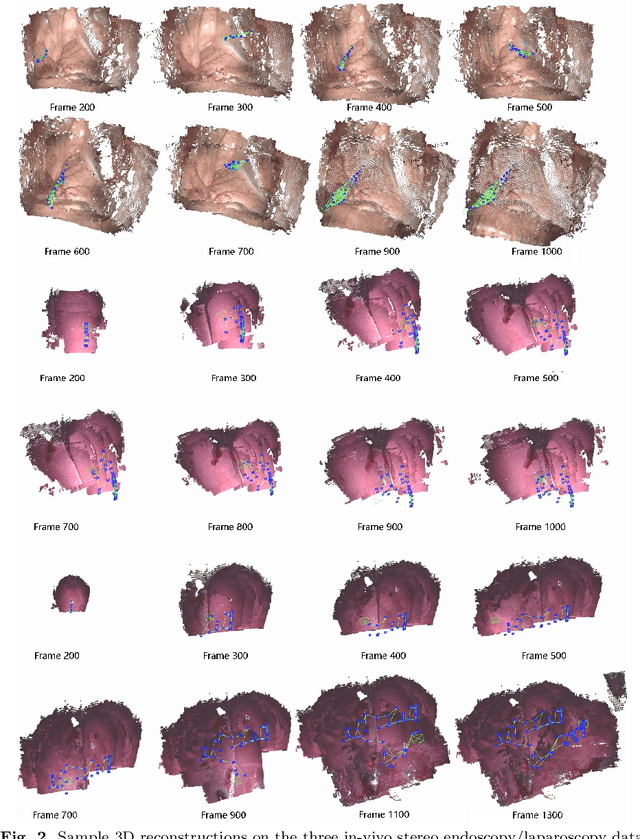
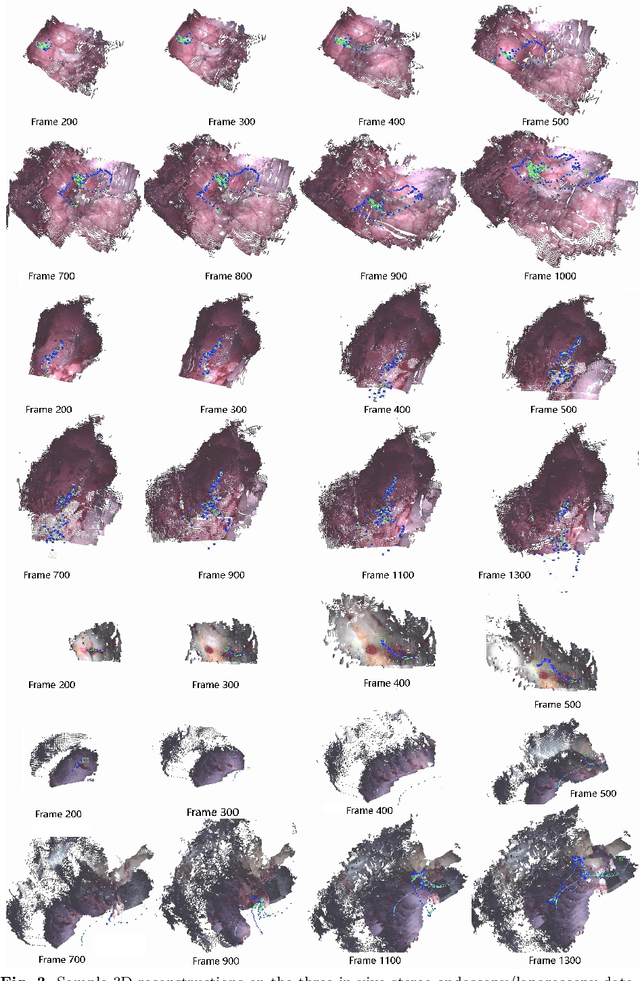
Purpose: Common dense stereo Simultaneous Localization and Mapping (SLAM) approaches in Minimally Invasive Surgery (MIS) require high-end parallel computational resources for real-time implementation. Yet, it is not always feasible since the computational resources should be allocated to other tasks like segmentation, detection, and tracking. To solve the problem of limited parallel computational power, this research aims at a lightweight dense stereo SLAM system that works on a single-core CPU and achieves real-time performance (more than 30 Hz in typical scenarios). Methods: A new dense stereo mapping module is integrated with the ORB-SLAM2 system and named BDIS-SLAM. Our new dense stereo mapping module includes stereo matching and 3D dense depth mosaic methods. Stereo matching is achieved with the recently proposed CPU-level real-time matching algorithm Bayesian Dense Inverse Searching (BDIS). A BDIS-based shape recovery and a depth mosaic strategy are integrated as a new thread and coupled with the backbone ORB-SLAM2 system for real-time stereo shape recovery. Results: Experiments on in-vivo data sets show that BDIS-SLAM runs at over 30 Hz speed on modern single-core CPU in typical endoscopy/colonoscopy scenarios. BDIS-SLAM only consumes around an additional 12% time compared with the backbone ORB-SLAM2. Although our lightweight BDIS-SLAM simplifies the process by ignoring deformation and fusion procedures, it can provide a usable dense mapping for modern MIS on computationally constrained devices. Conclusion: The proposed BDIS-SLAM is a lightweight stereo dense SLAM system for MIS. It achieves 30 Hz on a modern single-core CPU in typical endoscopy/colonoscopy scenarios (image size around 640*480). BDIS-SLAM provides a low-cost solution for dense mapping in MIS and has the potential to be applied in surgical robots and AR systems.
Iterative PnP and its application in 3D-2D vascular image registration for robot navigation
Oct 19, 2023This paper reports on a new real-time robot-centered 3D-2D vascular image alignment algorithm, which is robust to outliers and can align nonrigid shapes. Few works have managed to achieve both real-time and accurate performance for vascular intervention robots. This work bridges high-accuracy 3D-2D registration techniques and computational efficiency requirements in intervention robot applications. We categorize centerline-based vascular 3D-2D image registration problems as an iterative Perspective-n-Point (PnP) problem and propose to use the Levenberg-Marquardt solver on the Lie manifold. Then, the recently developed Reproducing Kernel Hilbert Space (RKHS) algorithm is introduced to overcome the ``big-to-small'' problem in typical robotic scenarios. Finally, an iterative reweighted least squares is applied to solve RKHS-based formulation efficiently. Experiments indicate that the proposed algorithm processes registration over 50 Hz (rigid) and 20 Hz (nonrigid) and obtains competing registration accuracy similar to other works. Results indicate that our Iterative PnP is suitable for future vascular intervention robot applications.