 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARTI-MARS$^2$: Scaling Multi-Agent Self-Search via Reinforcement Learning for Code Generation
Feb 08, 2026While the complex reasoning capability of Large Language Models (LLMs) has attracted significant attention, single-agent systems often encounter inherent performance ceilings in complex tasks such as code generation. Multi-agent collaboration offers a promising avenue to transcend these boundaries. However, existing frameworks typically rely on prompt-based test-time interactions or multi-role configurations trained with homogeneous parameters, limiting error correction capabilities and strategic diversity. In this paper, we propose a Multi-Agent Reinforced Training and Inference Framework with Self-Search Scaling (MARTI-MARS2), which integrates policy learning with multi-agent tree search by formulating the multi-agent collaborative exploration process as a dynamic and learnable environment. By allowing agents to iteratively explore and refine within the environment, the framework facilitates evolution from parameter-sharing homogeneous multi-role training to heterogeneous multi-agent training, breaking through single-agent capability limits. We also introduce an efficient inference strategy MARTI-MARS2-T+ to fully exploit the scaling potential of multi-agent collaboration at test time. We conduct extensive experiments across varied model scales (8B, 14B, and 32B) on challenging code generation benchmarks. Utilizing two collaborating 32B models, MARTI-MARS2 achieves 77.7%, outperforming strong baselines like GPT-5.1. Furthermore, MARTI-MARS2 reveals a novel scaling law: shifting from single-agent to homogeneous multi-role and ultimately to heterogeneous multi-agent paradigms progressively yields higher RL performance ceilings, robust TTS capabilities, and greater policy diversity, suggesting that policy diversity is critical for scaling intelligence via multi-agent reinforcement learning.
Emotion-Director: Bridging Affective Shortcut in Emotion-Oriented Image Generation
Dec 22, 2025Image generation based on diffusion models has demonstrated impressive capability, motivating exploration into diverse and specialized applications. Owing to the importance of emotion in advertising, emotion-oriented image generation has attracted increasing attention. However, current emotion-oriented methods suffer from an affective shortcut, where emotions are approximated to semantics. As evidenced by two decades of research, emotion is not equivalent to semantics. To this end, we propose Emotion-Director, a cross-modal collaboration framework consisting of two modules. First, we propose a cross-Modal Collaborative diffusion model, abbreviated as MC-Diffusion. MC-Diffusion integrates visual prompts with textual prompts for guidance, enabling the generation of emotion-oriented images beyond semantics. Further, we improve the DPO optimization by a negative visual prompt, enhancing the model's sensitivity to different emotions under the same semantics. Second, we propose MC-Agent, a cross-Modal Collaborative Agent system that rewrites textual prompts to express the intended emotions. To avoid template-like rewrites, MC-Agent employs multi-agents to simulate human subjectivity toward emotions, and adopts a chain-of-concept workflow that improves the visual expressiveness of the rewritten prompts. Extensive qualitative and quantitative experiments demonstrate the superiority of Emotion-Director in emotion-oriented image generation.
WeMusic-Agent: Efficient Conversational Music Recommendation via Knowledge Internalization and Agentic Boundary Learning
Dec 18, 2025Personalized music recommendation in conversational scenarios usually requires a deep understanding of user preferences and nuanced musical context, yet existing methods often struggle with balancing specialized domain knowledge and flexible tool integration. This paper proposes WeMusic-Agent, a training framework for efficient LLM-based conversational music recommendation. By integrating the knowledge internalization and agentic boundary learning, the framework aims to teach the model to intelligently decide when to leverage internalized knowledge and when to call specialized tools (e.g., music retrieval APIs, music recommendation systems). Under this framework, we present WeMusic-Agent-M1, an agentic model that internalizes extensive musical knowledge via continued pretraining on 50B music-related corpus while acquiring the ability to invoke external tools when necessary. Additionally, considering the lack of open-source benchmarks for conversational music recommendation, we also construct a benchmark for personalized music recommendations derived from real-world data in WeChat Listen. This benchmark enables comprehensive evaluation across multiple dimensions, including relevance, personalization, and diversity of the recommendations. Experiments on real-world data demonstrate that WeMusic-Agent achieves significant improvements over existing models.
MuCPT: Music-related Natural Language Model Continued Pretraining
Nov 18, 2025
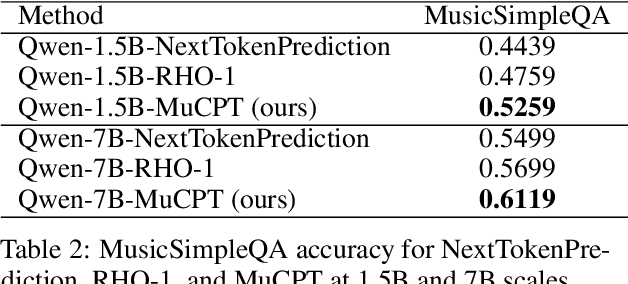
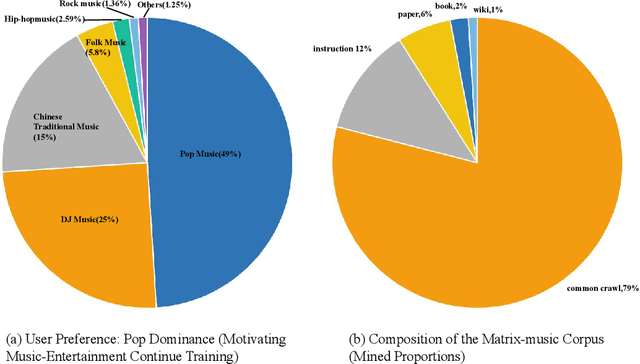
Large language models perform strongly on general tasks but remain constrained in specialized settings such as music, particularly in the music-entertainment domain, where corpus scale, purity, and the match between data and training objectives are critical. We address this by constructing a large, music-related natural language corpus (40B tokens) that combines open source and in-house data, and by implementing a domain-first data pipeline: a lightweight classifier filters and weights in-domain text, followed by multi-stage cleaning, de-duplication, and privacy-preserving masking. We further integrate multi-source music text with associated metadata to form a broader, better-structured foundation of domain knowledge. On the training side, we introduce reference-model (RM)-based token-level soft scoring for quality control: a unified loss-ratio criterion is used both for data selection and for dynamic down-weighting during optimization, reducing noise gradients and amplifying task-aligned signals, thereby enabling more effective music-domain continued pretraining and alignment. To assess factuality, we design the MusicSimpleQA benchmark, which adopts short, single-answer prompts with automated agreement scoring. Beyond the benchmark design, we conduct systematic comparisons along the axes of data composition. Overall, this work advances both the right corpus and the right objective, offering a scalable data-training framework and a reusable evaluation tool for building domain LLMs in the music field.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
A Survey of Reinforcement Learning for Large Reasoning Models
Sep 10, 2025In this paper, we survey recent advances in Reinforcement Learning (RL) for reasoning with Large Language Models (LLMs). RL has achieved remarkable success in advancing the frontier of LLM capabilities, particularly in addressing complex logical tasks such as mathematics and coding. As a result, RL has emerged as a foundational methodology for transforming LLMs into LRMs. With the rapid progress of the field, further scaling of RL for LRMs now faces foundational challenges not only in computational resources but also in algorithm design, training data, and infrastructure. To this end, it is timely to revisit the development of this domain, reassess its trajectory, and explore strategies to enhance the scalability of RL toward Artificial SuperIntelligence (ASI). In particular, we examine research applying RL to LLMs and LRMs for reasoning abilities, especially since the release of DeepSeek-R1, including foundational components, core problems, training resources, and downstream applications, to identify future opportunities and directions for this rapidly evolving area. We hope this review will promote future research on RL for broader reasoning models. Github: https://github.com/TsinghuaC3I/Awesome-RL-for-LRMs
AdsQA: Towards Advertisement Video Understanding
Sep 10, 2025Large language models (LLMs) have taken a great step towards AGI. Meanwhile, an increasing number of domain-specific problems such as math and programming boost these general-purpose models to continuously evolve via learning deeper expertise. Now is thus the time further to extend the diversity of specialized applications for knowledgeable LLMs, though collecting high quality data with unexpected and informative tasks is challenging. In this paper, we propose to use advertisement (ad) videos as a challenging test-bed to probe the ability of LLMs in perceiving beyond the objective physical content of common visual domain. Our motivation is to take full advantage of the clue-rich and information-dense ad videos' traits, e.g., marketing logic, persuasive strategies, and audience engagement. Our contribution is three-fold: (1) To our knowledge, this is the first attempt to use ad videos with well-designed tasks to evaluate LLMs. We contribute AdsQA, a challenging ad Video QA benchmark derived from 1,544 ad videos with 10,962 clips, totaling 22.7 hours, providing 5 challenging tasks. (2) We propose ReAd-R, a Deepseek-R1 styled RL model that reflects on questions, and generates answers via reward-driven optimization. (3) We benchmark 14 top-tier LLMs on AdsQA, and our \texttt{ReAd-R}~achieves the state-of-the-art outperforming strong competitors equipped with long-chain reasoning capabilities by a clear margin.
ReviewRL: Towards Automated Scientific Review with RL
Aug 14, 2025Peer review is essential for scientific progress but faces growing challenges due to increasing submission volumes and reviewer fatigue. Existing automated review approaches struggle with factual accuracy, rating consistency, and analytical depth, often generating superficial or generic feedback lacking the insights characteristic of high-quality human reviews. We introduce ReviewRL, a reinforcement learning framework for generating comprehensive and factually grounded scientific paper reviews. Our approach combines: (1) an ArXiv-MCP retrieval-augmented context generation pipeline that incorporates relevant scientific literature, (2) supervised fine-tuning that establishes foundational reviewing capabilities, and (3) a reinforcement learning procedure with a composite reward function that jointly enhances review quality and rating accuracy. Experiments on ICLR 2025 papers demonstrate that ReviewRL significantly outperforms existing methods across both rule-based metrics and model-based quality assessments. ReviewRL establishes a foundational framework for RL-driven automatic critique generation in scientific discovery, demonstrating promising potential for future development in this domain. The implementation of ReviewRL will be released at GitHub.
Code-Vision: Evaluating Multimodal LLMs Logic Understanding and Code Generation Capabilities
Feb 17, 2025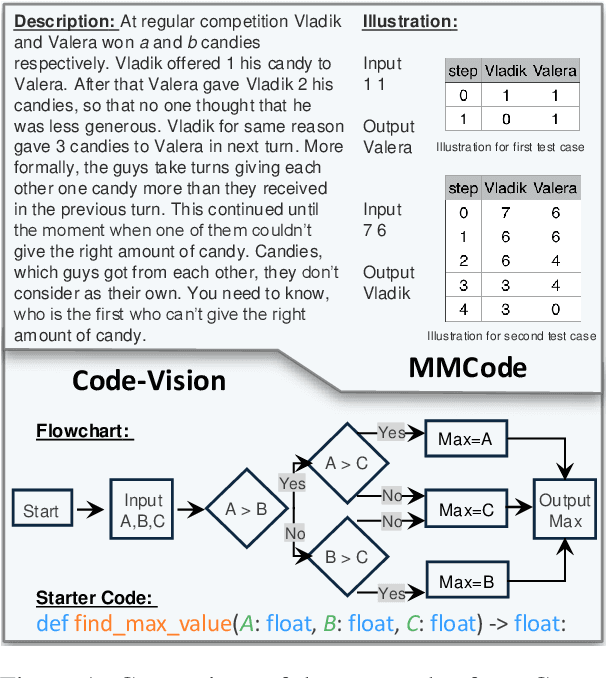

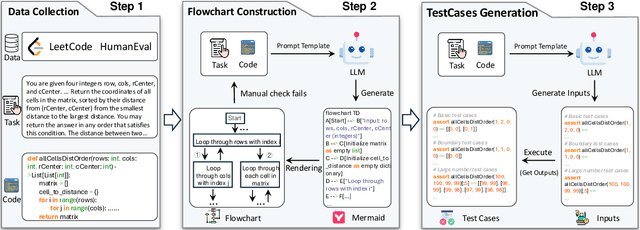
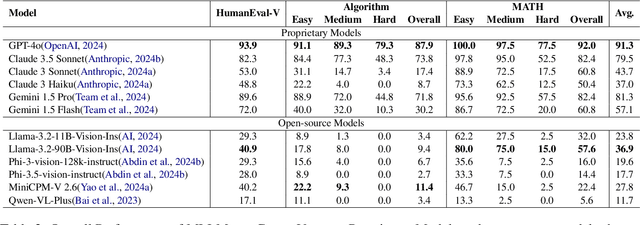
This paper introduces Code-Vision, a benchmark designed to evaluate the logical understanding and code generation capabilities of Multimodal Large Language Models (MLLMs). It challenges MLLMs to generate a correct program that fulfills specific functionality requirements based on a given flowchart, which visually represents the desired algorithm or process. Code-Vision comprises three subsets: HumanEval-V, Algorithm, and MATH, which evaluate MLLMs' coding abilities across basic programming, algorithmic, and mathematical problem-solving domains. Our experiments evaluate 12 MLLMs on Code-Vision. Experimental results demonstrate that there is a large performance difference between proprietary and open-source models. On Hard problems, GPT-4o can achieve 79.3% pass@1, but the best open-source model only achieves 15%. Further experiments reveal that Code-Vision can pose unique challenges compared to other multimodal reasoning benchmarks MMCode and MathVista. We also explore the reason for the poor performance of the open-source models. All data and codes are available at https://github.com/wanghanbinpanda/CodeVision.
Generative Regression Based Watch Time Prediction for Video Recommendation: Model and Performance
Dec 28, 2024



Watch time prediction (WTP) has emerged as a pivotal task in short video recommendation systems, designed to encapsulate user interests. Predicting users' watch times on videos often encounters challenges, including wide value ranges and imbalanced data distributions, which can lead to significant bias when directly regressing watch time. Recent studies have tried to tackle these issues by converting the continuous watch time estimation into an ordinal classification task. While these methods are somewhat effective, they exhibit notable limitations. Inspired by language modeling, we propose a novel Generative Regression (GR) paradigm for WTP based on sequence generation. This approach employs structural discretization to enable the lossless reconstruction of original values while maintaining prediction fidelity. By formulating the prediction problem as a numerical-to-sequence mapping, and with meticulously designed vocabulary and label encodings, each watch time is transformed into a sequence of tokens. To expedite model training, we introduce the curriculum learning with an embedding mixup strategy which can mitigate training-and-inference inconsistency associated with teacher forcing. We evaluate our method against state-of-the-art approaches on four public datasets and one industrial dataset. We also perform online A/B testing on Kuaishou, a leading video app with about 400 million DAUs, to demonstrate the real-world efficacy of our method. The results conclusively show that GR outperforms existing techniques significantly. Furthermore, we successfully apply GR to another regression task in recommendation systems, i.e., Lifetime Value (LTV) prediction, which highlights its potential as a novel and effective solution to general regression challenges.