 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Biomedical Hypothesis Generators: A Comprehensive Evaluation
Paper and Code
Jul 12, 2024
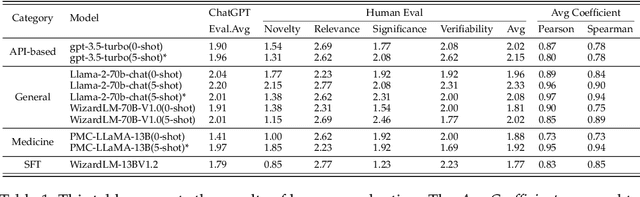
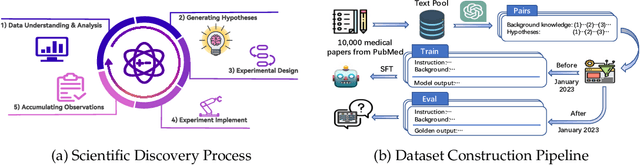

The rapid growth of biomedical knowledge has outpaced our ability to efficiently extract insights and generate novel hypotheses. Large language models (LLMs) have emerged as a promising tool to revolutionize knowledge interaction and potentially accelerate biomedical discovery. In this paper, we present a comprehensive evaluation of LLMs as biomedical hypothesis generators. We construct a dataset of background-hypothesis pairs from biomedical literature, carefully partitioned into training, seen, and unseen test sets based on publication date to mitigate data contamination. Using this dataset, we assess the hypothesis generation capabilities of top-tier instructed models in zero-shot, few-shot, and fine-tuning settings. To enhance the exploration of uncertainty, a crucial aspect of scientific discovery, we incorporate tool use and multi-agent interactions in our evaluation framework. Furthermore, we propose four novel metrics grounded in extensive literature review to evaluate the quality of generated hypotheses, considering both LLM-based and human assessments. Our experiments yield two key findings: 1) LLMs can generate novel and validated hypotheses, even when tested on literature unseen during training, and 2) Increasing uncertainty through multi-agent interactions and tool use can facilitate diverse candidate generation and improve zero-shot hypothesis generation performance. However, we also observe that the integration of additional knowledge through few-shot learning and tool use may not always lead to performance gains, highlighting the need for careful consideration of the type and scope of external knowledge incorporated. These findings underscore the potential of LLMs as powerful aids in biomedical hypothesis generation and provide valuable insights to guide further research in this area.