 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models as Biomedical Hypothesis Generators: A Comprehensive Evaluation
Jul 12, 2024
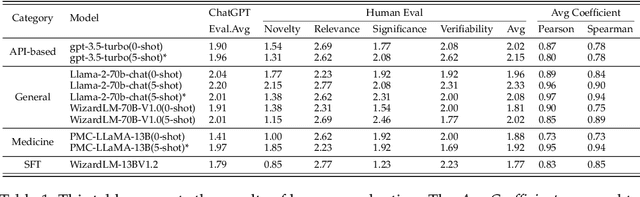
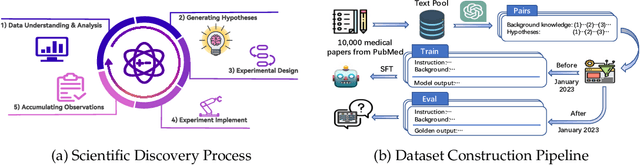

The rapid growth of biomedical knowledge has outpaced our ability to efficiently extract insights and generate novel hypotheses. Large language models (LLMs) have emerged as a promising tool to revolutionize knowledge interaction and potentially accelerate biomedical discovery. In this paper, we present a comprehensive evaluation of LLMs as biomedical hypothesis generators. We construct a dataset of background-hypothesis pairs from biomedical literature, carefully partitioned into training, seen, and unseen test sets based on publication date to mitigate data contamination. Using this dataset, we assess the hypothesis generation capabilities of top-tier instructed models in zero-shot, few-shot, and fine-tuning settings. To enhance the exploration of uncertainty, a crucial aspect of scientific discovery, we incorporate tool use and multi-agent interactions in our evaluation framework. Furthermore, we propose four novel metrics grounded in extensive literature review to evaluate the quality of generated hypotheses, considering both LLM-based and human assessments. Our experiments yield two key findings: 1) LLMs can generate novel and validated hypotheses, even when tested on literature unseen during training, and 2) Increasing uncertainty through multi-agent interactions and tool use can facilitate diverse candidate generation and improve zero-shot hypothesis generation performance. However, we also observe that the integration of additional knowledge through few-shot learning and tool use may not always lead to performance gains, highlighting the need for careful consideration of the type and scope of external knowledge incorporated. These findings underscore the potential of LLMs as powerful aids in biomedical hypothesis generation and provide valuable insights to guide further research in this area.
UltraMedical: Building Specialized Generalists in Biomedicine
Jun 06, 2024Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains and are moving towards more specialized areas. Recent advanced proprietary models such as GPT-4 and Gemini have achieved significant advancements in biomedicine, which have also raised privacy and security challenges. The construction of specialized generalists hinges largely on high-quality datasets, enhanced by techniques like supervised fine-tuning and reinforcement learning from human or AI feedback, and direct preference optimization. However, these leading technologies (e.g., preference learning) are still significantly limited in the open source community due to the scarcity of specialized data. In this paper, we present the UltraMedical collections, which consist of high-quality manual and synthetic datasets in the biomedicine domain, featuring preference annotations across multiple advanced LLMs. By utilizing these datasets, we fine-tune a suite of specialized medical models based on Llama-3 series, demonstrating breathtaking capabilities across various medical benchmarks. Moreover, we develop powerful reward models skilled in biomedical and general reward benchmark, enhancing further online preference learning within the biomedical LLM community.
Large Language Models are Zero Shot Hypothesis Proposers
Nov 10, 2023



Significant scientific discoveries have driven the progress of human civilisation. The explosion of scientific literature and data has created information barriers across disciplines that have slowed the pace of scientific discovery. Large Language Models (LLMs) hold a wealth of global and interdisciplinary knowledge that promises to break down these information barriers and foster a new wave of scientific discovery. However, the potential of LLMs for scientific discovery has not been formally explored. In this paper, we start from investigating whether LLMs can propose scientific hypotheses. To this end, we construct a dataset consist of background knowledge and hypothesis pairs from biomedical literature. The dataset is divided into training, seen, and unseen test sets based on the publication date to control visibility. We subsequently evaluate the hypothesis generation capabilities of various top-tier instructed models in zero-shot, few-shot, and fine-tuning settings, including both closed and open-source LLMs. Additionally, we introduce an LLM-based multi-agent cooperative framework with different role designs and external tools to enhance the capabilities related to generating hypotheses. We also design four metrics through a comprehensive review to evaluate the generated hypotheses for both ChatGPT-based and human evaluations. Through experiments and analyses, we arrive at the following findings: 1) LLMs surprisingly generate untrained yet validated hypotheses from testing literature. 2) Increasing uncertainty facilitates candidate generation, potentially enhancing zero-shot hypothesis generation capabilities. These findings strongly support the potential of LLMs as catalysts for new scientific discoveries and guide further exploration.