 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHi-Light: A Path to high-fidelity, high-resolution video relighting with a Novel Evaluation Paradigm
Jan 30, 2026Video relighting offers immense creative potential and commercial value but is hindered by challenges, including the absence of an adequate evaluation metric, severe light flickering, and the degradation of fine-grained details during editing. To overcome these challenges, we introduce Hi-Light, a novel, training-free framework for high-fidelity, high-resolution, robust video relighting. Our approach introduces three technical innovations: lightness prior anchored guided relighting diffusion that stabilises intermediate relit video, a Hybrid Motion-Adaptive Lighting Smoothing Filter that leverages optical flow to ensure temporal stability without introducing motion blur, and a LAB-based Detail Fusion module that preserves high-frequency detail information from the original video. Furthermore, to address the critical gap in evaluation, we propose the Light Stability Score, the first quantitative metric designed to specifically measure lighting consistency. Extensive experiments demonstrate that Hi-Light significantly outperforms state-of-the-art methods in both qualitative and quantitative comparisons, producing stable, highly detailed relit videos.
UniLayDiff: A Unified Diffusion Transformer for Content-Aware Layout Generation
Dec 09, 2025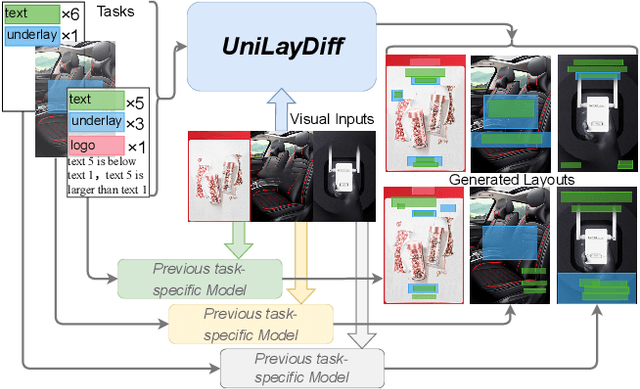
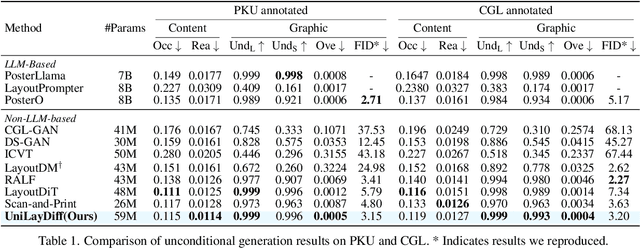
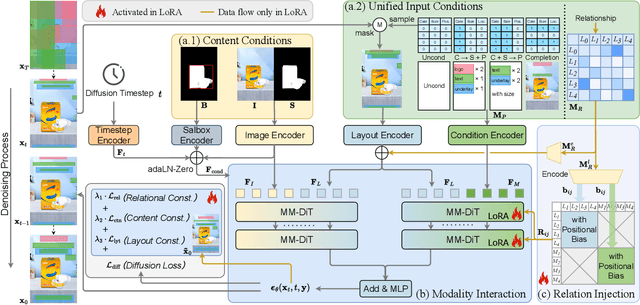
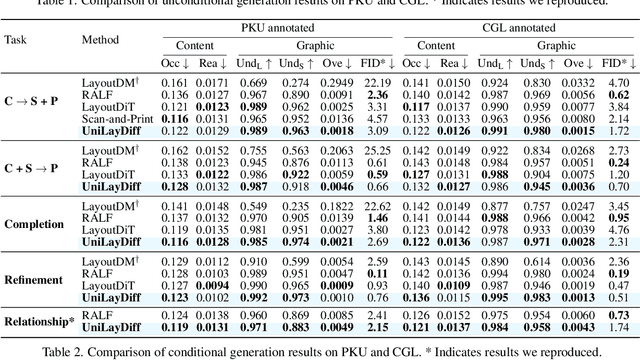
Content-aware layout generation is a critical task in graphic design automation, focused on creating visually appealing arrangements of elements that seamlessly blend with a given background image. The variety of real-world applications makes it highly challenging to develop a single model capable of unifying the diverse range of input-constrained generation sub-tasks, such as those conditioned by element types, sizes, or their relationships. Current methods either address only a subset of these tasks or necessitate separate model parameters for different conditions, failing to offer a truly unified solution. In this paper, we propose UniLayDiff: a Unified Diffusion Transformer, that for the first time, addresses various content-aware layout generation tasks with a single, end-to-end trainable model. Specifically, we treat layout constraints as a distinct modality and employ Multi-Modal Diffusion Transformer framework to capture the complex interplay between the background image, layout elements, and diverse constraints. Moreover, we integrate relation constraints through fine-tuning the model with LoRA after pretraining the model on other tasks. Such a schema not only achieves unified conditional generation but also enhances overall layout quality. Extensive experiments demonstrate that UniLayDiff achieves state-of-the-art performance across from unconditional to various conditional generation tasks and, to the best of our knowledge, is the first model to unify the full range of content-aware layout generation tasks.
Positional Encoding Field
Oct 23, 2025Diffusion Transformers (DiTs) have emerged as the dominant architecture for visual generation, powering state-of-the-art image and video models. By representing images as patch tokens with positional encodings (PEs), DiTs combine Transformer scalability with spatial and temporal inductive biases. In this work, we revisit how DiTs organize visual content and discover that patch tokens exhibit a surprising degree of independence: even when PEs are perturbed, DiTs still produce globally coherent outputs, indicating that spatial coherence is primarily governed by PEs. Motivated by this finding, we introduce the Positional Encoding Field (PE-Field), which extends positional encodings from the 2D plane to a structured 3D field. PE-Field incorporates depth-aware encodings for volumetric reasoning and hierarchical encodings for fine-grained sub-patch control, enabling DiTs to model geometry directly in 3D space. Our PE-Field-augmented DiT achieves state-of-the-art performance on single-image novel view synthesis and generalizes to controllable spatial image editing.
Glissando-Net: Deep sinGLe vIew category level poSe eStimation ANd 3D recOnstruction
Jan 24, 2025



We present a deep learning model, dubbed Glissando-Net, to simultaneously estimate the pose and reconstruct the 3D shape of objects at the category level from a single RGB image. Previous works predominantly focused on either estimating poses(often at the instance level), or reconstructing shapes, but not both. Glissando-Net is composed of two auto-encoders that are jointly trained, one for RGB images and the other for point clouds. We embrace two key design choices in Glissando-Net to achieve a more accurate prediction of the 3D shape and pose of the object given a single RGB image as input. First, we augment the feature maps of the point cloud encoder and decoder with transformed feature maps from the image decoder, enabling effective 2D-3D interaction in both training and prediction. Second, we predict both the 3D shape and pose of the object in the decoder stage. This way, we better utilize the information in the 3D point clouds presented only in the training stage to train the network for more accurate prediction. We jointly train the two encoder-decoders for RGB and point cloud data to learn how to pass latent features to the point cloud decoder during inference. In testing, the encoder of the 3D point cloud is discarded. The design of Glissando-Net is inspired by codeSLAM. Unlike codeSLAM, which targets 3D reconstruction of scenes, we focus on pose estimation and shape reconstruction of objects, and directly predict the object pose and a pose invariant 3D reconstruction without the need of the code optimization step. Extensive experiments, involving both ablation studies and comparison with competing methods, demonstrate the efficacy of our proposed method, and compare favorably with the state-of-the-art.
ComposeAnyone: Controllable Layout-to-Human Generation with Decoupled Multimodal Conditions
Jan 21, 2025



Building on the success of diffusion models, significant advancements have been made in multimodal image generation tasks. Among these, human image generation has emerged as a promising technique, offering the potential to revolutionize the fashion design process. However, existing methods often focus solely on text-to-image or image reference-based human generation, which fails to satisfy the increasingly sophisticated demands. To address the limitations of flexibility and precision in human generation, we introduce ComposeAnyone, a controllable layout-to-human generation method with decoupled multimodal conditions. Specifically, our method allows decoupled control of any part in hand-drawn human layouts using text or reference images, seamlessly integrating them during the generation process. The hand-drawn layout, which utilizes color-blocked geometric shapes such as ellipses and rectangles, can be easily drawn, offering a more flexible and accessible way to define spatial layouts. Additionally, we introduce the ComposeHuman dataset, which provides decoupled text and reference image annotations for different components of each human image, enabling broader applications in human image generation tasks. Extensive experiments on multiple datasets demonstrate that ComposeAnyone generates human images with better alignment to given layouts, text descriptions, and reference images, showcasing its multi-task capability and controllability.
CatV2TON: Taming Diffusion Transformers for Vision-Based Virtual Try-On with Temporal Concatenation
Jan 20, 2025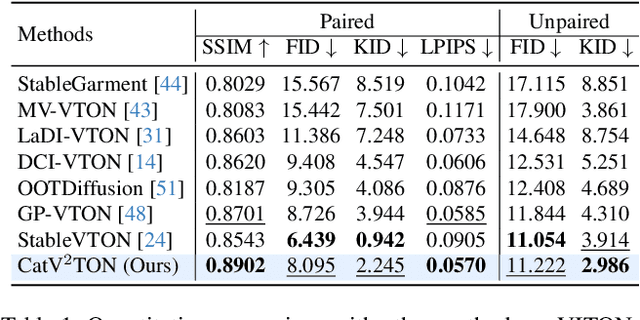
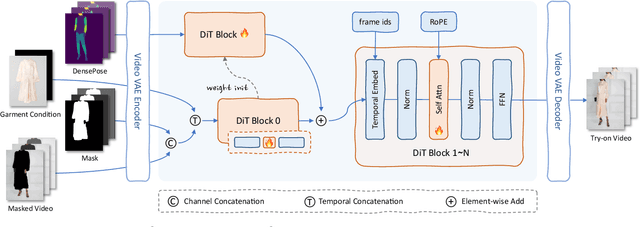
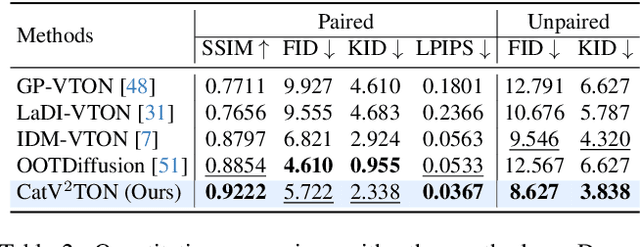
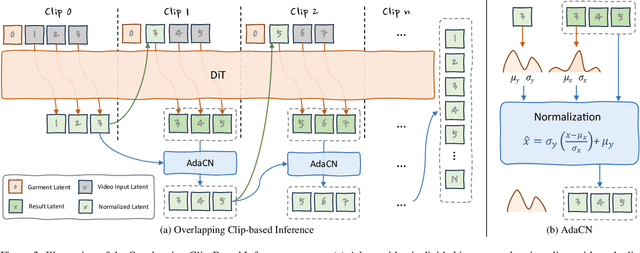
Virtual try-on (VTON) technology has gained attention due to its potential to transform online retail by enabling realistic clothing visualization of images and videos. However, most existing methods struggle to achieve high-quality results across image and video try-on tasks, especially in long video scenarios. In this work, we introduce CatV2TON, a simple and effective vision-based virtual try-on (V2TON) method that supports both image and video try-on tasks with a single diffusion transformer model. By temporally concatenating garment and person inputs and training on a mix of image and video datasets, CatV2TON achieves robust try-on performance across static and dynamic settings. For efficient long-video generation, we propose an overlapping clip-based inference strategy that uses sequential frame guidance and Adaptive Clip Normalization (AdaCN) to maintain temporal consistency with reduced resource demands. We also present ViViD-S, a refined video try-on dataset, achieved by filtering back-facing frames and applying 3D mask smoothing for enhanced temporal consistency. Comprehensive experiments demonstrate that CatV2TON outperforms existing methods in both image and video try-on tasks, offering a versatile and reliable solution for realistic virtual try-ons across diverse scenarios.
CatVTON: Concatenation Is All You Need for Virtual Try-On with Diffusion Models
Jul 21, 2024



Virtual try-on methods based on diffusion models achieve realistic try-on effects but often replicate the backbone network as a ReferenceNet or use additional image encoders to process condition inputs, leading to high training and inference costs. In this work, we rethink the necessity of ReferenceNet and image encoders and innovate the interaction between garment and person by proposing CatVTON, a simple and efficient virtual try-on diffusion model. CatVTON facilitates the seamless transfer of in-shop or worn garments of any category to target persons by simply concatenating them in spatial dimensions as inputs. The efficiency of our model is demonstrated in three aspects: (1) Lightweight network: Only the original diffusion modules are used, without additional network modules. The text encoder and cross-attentions for text injection in the backbone are removed, reducing the parameters by 167.02M. (2) Parameter-efficient training: We identified the try-on relevant modules through experiments and achieved high-quality try-on effects by training only 49.57M parameters, approximately 5.51 percent of the backbone network's parameters. (3) Simplified inference: CatVTON eliminates all unnecessary conditions and preprocessing steps, including pose estimation, human parsing, and text input, requiring only a garment reference, target person image, and mask for the virtual try-on process. Extensive experiments demonstrate that CatVTON achieves superior qualitative and quantitative results with fewer prerequisites and trainable parameters than baseline methods. Furthermore, CatVTON shows good generalization in in-the-wild scenarios despite using open-source datasets with only 73K samples.
Large Language Models as Biomedical Hypothesis Generators: A Comprehensive Evaluation
Jul 12, 2024
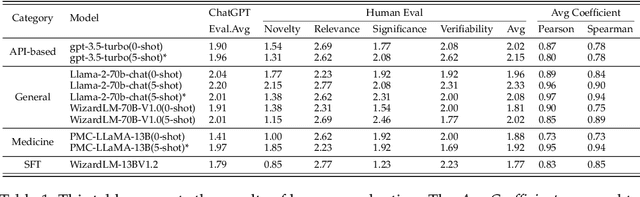
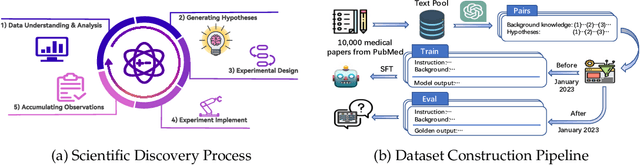

The rapid growth of biomedical knowledge has outpaced our ability to efficiently extract insights and generate novel hypotheses. Large language models (LLMs) have emerged as a promising tool to revolutionize knowledge interaction and potentially accelerate biomedical discovery. In this paper, we present a comprehensive evaluation of LLMs as biomedical hypothesis generators. We construct a dataset of background-hypothesis pairs from biomedical literature, carefully partitioned into training, seen, and unseen test sets based on publication date to mitigate data contamination. Using this dataset, we assess the hypothesis generation capabilities of top-tier instructed models in zero-shot, few-shot, and fine-tuning settings. To enhance the exploration of uncertainty, a crucial aspect of scientific discovery, we incorporate tool use and multi-agent interactions in our evaluation framework. Furthermore, we propose four novel metrics grounded in extensive literature review to evaluate the quality of generated hypotheses, considering both LLM-based and human assessments. Our experiments yield two key findings: 1) LLMs can generate novel and validated hypotheses, even when tested on literature unseen during training, and 2) Increasing uncertainty through multi-agent interactions and tool use can facilitate diverse candidate generation and improve zero-shot hypothesis generation performance. However, we also observe that the integration of additional knowledge through few-shot learning and tool use may not always lead to performance gains, highlighting the need for careful consideration of the type and scope of external knowledge incorporated. These findings underscore the potential of LLMs as powerful aids in biomedical hypothesis generation and provide valuable insights to guide further research in this area.
Enhance the Image: Super Resolution using Artificial Intelligence in MRI
Jun 19, 2024



This chapter provides an overview of deep learning techniques for improving the spatial resolution of MRI, ranging from convolutional neural networks, generative adversarial networks, to more advanced models including transformers, diffusion models, and implicit neural representations. Our exploration extends beyond the methodologies to scrutinize the impact of super-resolved images on clinical and neuroscientific assessments. We also cover various practical topics such as network architectures, image evaluation metrics, network loss functions, and training data specifics, including downsampling methods for simulating low-resolution images and dataset selection. Finally, we discuss existing challenges and potential future directions regarding the feasibility and reliability of deep learning-based MRI super-resolution, with the aim to facilitate its wider adoption to benefit various clinical and neuroscientific applications.
Artificial Intelligence for Neuro MRI Acquisition: A Review
Jun 10, 2024Magnetic resonance imaging (MRI) has significantly benefited from the resurgence of artificial intelligence (AI). By leveraging AI's capabilities in large-scale optimization and pattern recognition, innovative methods are transforming the MRI acquisition workflow, including planning, sequence design, and correction of acquisition artifacts. These emerging algorithms demonstrate substantial potential in enhancing the efficiency and throughput of acquisition steps. This review discusses several pivotal AI-based methods in neuro MRI acquisition, focusing on their technological advances, impact on clinical practice, and potential risks.